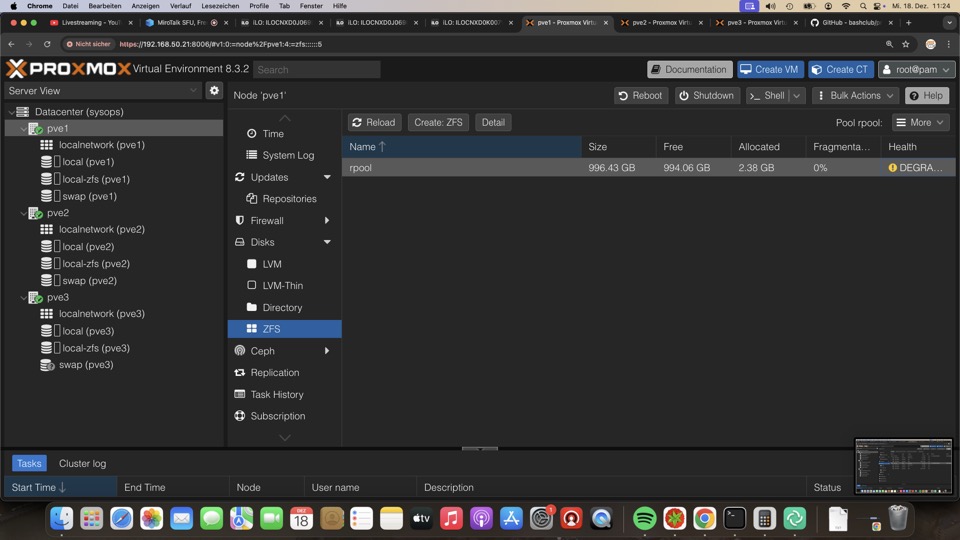
Dokumentation
Dokumentation von den Kursen von sysops
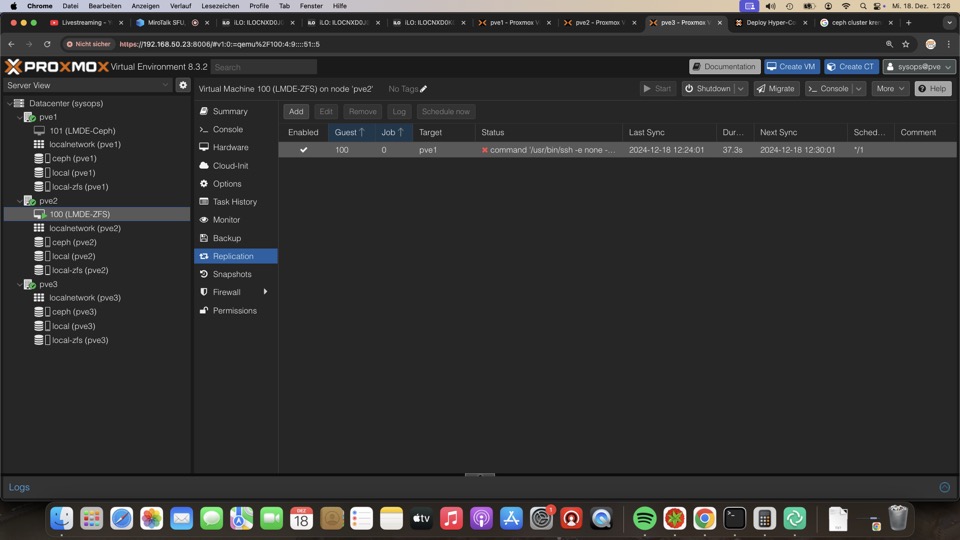
- Proxmox
- Verschlüsselung mit Proxmox, ZFS und Debian / Windows
- Proxmox Best Practice Setup für ZFS und / oder Ceph im Cluster für Einsteiger (Stand Dezember 2024)
- ZFS Grundlagen am Beispiel Proxmox VE(Stand Januar 2025)
- OPNsense Migration Legacy zu Instance, ohne neues Ausrollen von Konfigurationen
- Backup und Replikation trojanersicher für Proxmox VE mit Miyagi Workflow
- Migration Univention Corporate Server & Kopano nach Zamba AD & Mailcow
- Virtuelle Maschine mit Windows 10 Bios auf Proxmox zu Windows 11 mit UEFI umstellen
- Stand der Technik nach DSGVO am Beispiel Kopano - Was sagt ChatGPT?
- Information zur Sicherung und Wiederherstellung von Windows 10/11-Systemen
- ZFS Grundlagen am Beispiel Proxmox VE(Stand Dezember 2025)
- Das Ende von Hetzner DNS Robot und ACME API - Stand Januar 2026
Proxmox
Die Dokumentation für "Proxmox Produktiv mit ZFS betreiben" basiert auf einem kostenpflichtigen Kurs und soll dessen Inhalte wiedergeben, kann aber nicht die Betreuung und Beantwortung von Fragen, wie sie der Besuch des Kurses bietet, ersetzen. Es soll das Wissen von den hauptberuflichen Sysops Admins an Interessierte weitergegeben werden, die es danach auf den von Ihnen betreuten Systemen umsetzen können.
https://cloudistboese.de - Das Schulungsportal von sysops.tv
Proxmox VE - Alternative zu vSphere und Hyper-V mit Support aus Deutschland und Österreich
Was ist Proxmox VE
- Proxmox VE ist eine Gesamtlösung zur Virtualisierung
- Einsatzbereiche Standalone bis Cluster
- Es beinhaltet entscheidende Storagefunktionen mit ZFS und Ceph
- Umfangreiche Virtualisierung und Containering Lösung
- Moderner Unterbau mit aktuellem Debian Linux
- Reichhaltige Funktionen die durch eigene Kommandozeilenlösungen erweitert werden
Wo sind die Grenzen von Proxmox VE
- Kaum bis keine Funktionen in der GUI für Storage Steuerung und Monitoring
- Viele Funktionen lassen sich nur per Kommandozeile ausführen
- Es gibt keine Möglichkeit ein defektes System per Installation zu reparieren, Reparaturkenntnisse müssen vorhanden sein
- Das Eigenmonitoring ist so gut wie nicht vorhanden. Defekte Replikationen, Raids oder Datenträger nur mühsam feststellbar
Weitere Funktionen, die eher weniger Sinn machen
- SAN mit iSCSI (keine GUI)
- SAN mit NFS (beste Option)
- Hardware Raid mit LVM (kein Vorteil zu ZFS / CEPH)
- Multipath nur per manueller Konfiguration
Indikation für Einsatz
- Kleinere Anzahl von PVE Systemen mit direkt angeschlossenen Datenträgern (kein Hardware Raid!)
- Hoher Bedarf an Reparatur durch Snapshots (tausende Snapshots kein Problem)
- Leichte Replikation der Daten auf zweites System und eventuelle weitere Ziele (mit Bashclub Tools und GUI möglich, Pull Replikation nur mit unseren Tools)
- Hauseigene Datensicherungslösung auf Hypervisor Ebene
- Eigenes Monitoring und Reporting bevorzugt - Zentrales Monitoring wie Check_MK ist zwingend notwendig
** Bei Proxmox kommt alles aus den Kernel (ZFS, Ceph, LXC, KVM, uvm.) **
Linux Kommandos die man kennen sollte
- lsblk #zeigt Datenträger und Partitionen an
- ls -althr /dev/disk/by-id # zeigt Festplatten Aliase zum eindeutigen Zuweisen von Raids an
- ls -althr /sys/class/net #zeigt aktuelle Netzwerkkarten an
- ls -althr /dev/zvol/rpool/data # zeigt ZVOL Namenszuordnungen zu /dev/zdxxx an
- dmesg -Tw #zeigt Hardwareänderungen wie Diskwechsel oder Netzwerkkabel stecken live an
- systemctl --failed #zeigt hängende dienste an
- htop #zeigt load an. hier sollten die drei Zahlen unter der Anzahl der logischen Kerne sein. Also 16 Kerne, Load unter 16. Erste Zahl letze Minute, zweite Zahl letze fünf Minuten, dritte für letzte Viertelstunde
- zpool list # hier muss der Wert Cap unter 80% liegen, sonst müssen Snapshots oder sogar produktive Daten gelöscht werden
- zpool status #Raid Status
- zfs list -t snapshot #z. B. mit -oname,written,creation rpool/data/vm-100-disk-1
- qm stop 100 && zfs rollback rpool/data/subvol-100-disk-0@zfs-auto-snap_hourly-2024-10-24-0217 && qm start 100 # Rollback ohne Widerkehr der Daten einer VM
Proxmox Installation
Um Proxmox mit ZFS nutzen zu können, müssen die Platten direkt an Proxmox angebunden werden. Es sollte kein RAID Controller mit RAID 0 genutzt werden, da dies früher oder später zu Problemen und Datenverlusten führen wird! Damit auch eine Update von Promox 7.x auf 8.x gezeigt werden kann, wird im Kurs mit der Installation einer Proxmox Version 7.x begonnen und später auf 8 aktualisiert. Das Postinstall Script aus dem Bashclub wird installiert, um auch alle benötigten Tools für die tägliche Arbeit und im Problemfall im Zugriff zu haben. (z.B. ohne ein Netzwerkverbindung kann nichts mehr nachinstalliert werden)
Spickzettel für Installation
- Kein RAID Controller
- Platten direkt an Proxmox geben, es müssen die Herstellerbezeichnung der Platten im Linux Betriebssystem sichtbar sein. (z.B. nvme-INTEL_... über das Kommando
ls /dev/disk/by-id) - ISO Installation mit Version 7.x
- Install Proxmox starten
- Die Standardauswahl im Installer würde LVM auf eine Disk installieren, was nur für Hardware Raid Sinn machen würde
- ZFS RAID 1 oder ZFS RAID 10 sind die empholenen Level für die Beste Leistung, haben jedoch einen Platzverlust von 50%, was in der Natur liegt
- Advanced Options - ZFS Optionen können default gelassen werden, ashift=12 + compression=on passt für alle Platten über 2TB
- Passwort muss sich in der HTML Console gut tippen lassen - HTML und JAVA Konsolen sind hier sehr schwierig mit deutsch Tastatur! Testen!
- Die Installation mit sorgfältig gewählten Namen und IP Adressen durchführen
- Install Proxmox starten
Proxmox GUI Zugriff
-
Im Browser: https://<ip>:8006
- Single PAM - ssh login # Benutzer auf Linux Ebene und PVE GUI
- Proxmox VE - Weboberfläche Cluster User
-
Proxmox CLI gegen root SSH Zugriff schützen (macht auch das SSH Hardening unseres Postinstallers)
-
/etc/ssh/.sshd_config
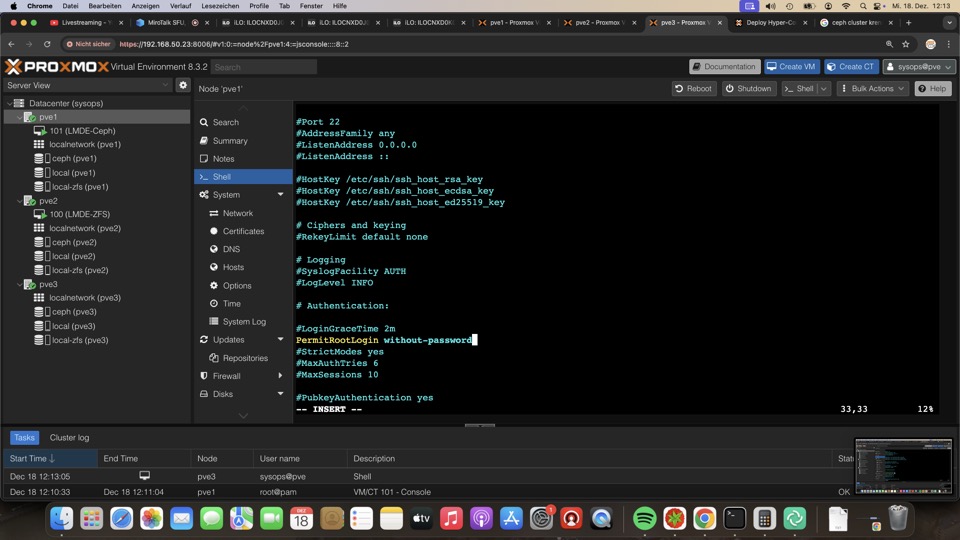
- PermitRootLogin without-password
- service sshd reload
Proxmox GUI
-
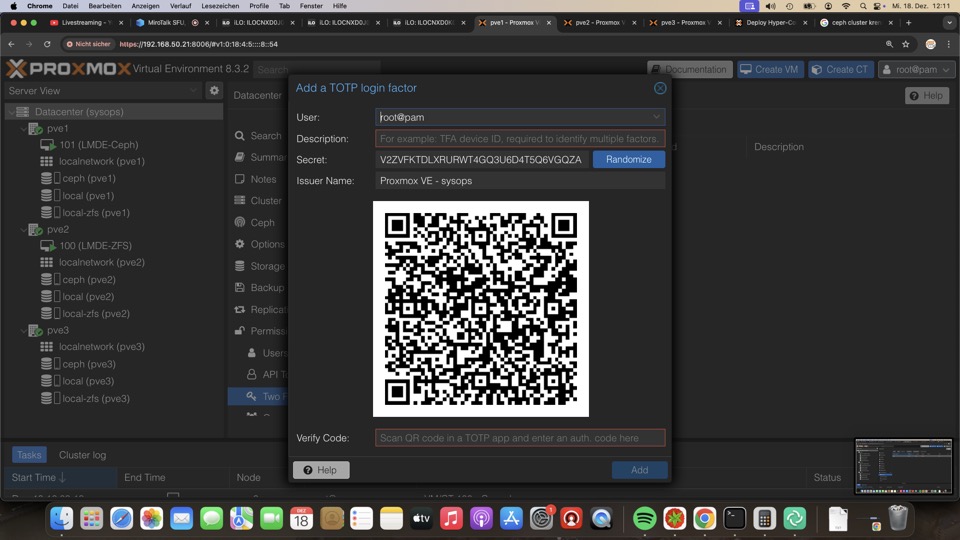
TOTP (time-based one-time password) kann über die Proxmox GUI gesetzt werden
- Datacenter - Permissions - Two Factor
- Selbst bei kompromitierem Passwort kann kein Dritter zugreifen!
- Für PAM und PVE User möglich
Update nach Proxmox 8.x - Für Einsteiger am einfachsten bei Erstinstallation zu üben
Das Pre-Upgrade Check Script pve7to8 sollte ausgeführt werden, um mögliche Probleme vor dem Upgrade erkennen zu können. Erstmal ohne Parameter und anschließend mit Parameter (--full: alle Checks).
** Für das Upgrade muss entweder eine Subskription erorben werden. Alternativ kann man auch das Enterprise Repository deaktivieren und das No-Subkription Repository aktivieren. Nur so erhält man Proxmox Updates!!! Ohne diese Auswahl kommen nur Debian Security Fixes!!!
Hier der Stand Version 7 zu 8
-
pve7to8 -
ve7to8 -- full
Wir empfehlen die VMs und Container zu stoppen und einen zeitnahen Reboot - Der neue Kernel passend zur GUI kann nur so aktiviert werden
apt update apt dist-upgrade pveversion
Letzte Version PVE 7 sollte nun installiert sein, kein Reboot notwendig hier
Upgradeprozedur bei Standardsystem
sed -i 's/bullseye/bookworm/g' /etc/apt/sources.list # ändert alle Repositories von Bullseye (Debian 11) zu Bookworm (Debian 12)
Enterprise Repo anpassen
echo "deb https://enterprise.proxmox.com/debian/pve bookworm pve-enterprise" > /etc/apt/sources.list.d/pve-enterprise.list
Debian update
screen # falls etwas schief geht kann man mit screen -r zurück zur Sitzung apt update apt dist-upgrade #sollte hier mehrere hundert Aktualisierungen ankündigen
Während des Upgrades sollte man alles mit N beantworten und den Diensteneustarts zustimmen. Es kommt ggf. auch ein Textdokument was mit w zu verlassen ist
Unser Postinstaller sorgt in kürzester Zeit für alle notwendigen Sicherheits- und Komforfunktionen für den Notfall
Postinstall aus bashclub (proxmox-zfs-postinstall) auf github
-
Bashclub Postinstaller Proxmox
- ZFS L1ARC Size wird von PVE nur lieblos berechnet, empfohlen sind 1GB RAM für 1TB netto Datastore als first Level Cache
- Swappiness auf 10 Prozent oder kleiner, damit PVE nicht zu früh auslagert, jedoch am besten nicht den RAM überprovisioneieren!
- ZFS auto snapshots - die Werte können frei konfiguriert werden. Empfehlung für den Start (PVE weiß nichts davon!)
- monthly: 3
- weekly: 6
- daily: 10
- frequent: 12
- hourly: 96 --> wegen Weihnachten und Ostern
- Repo
- No Subscription auswählen, falls keine Subskription vorhanden
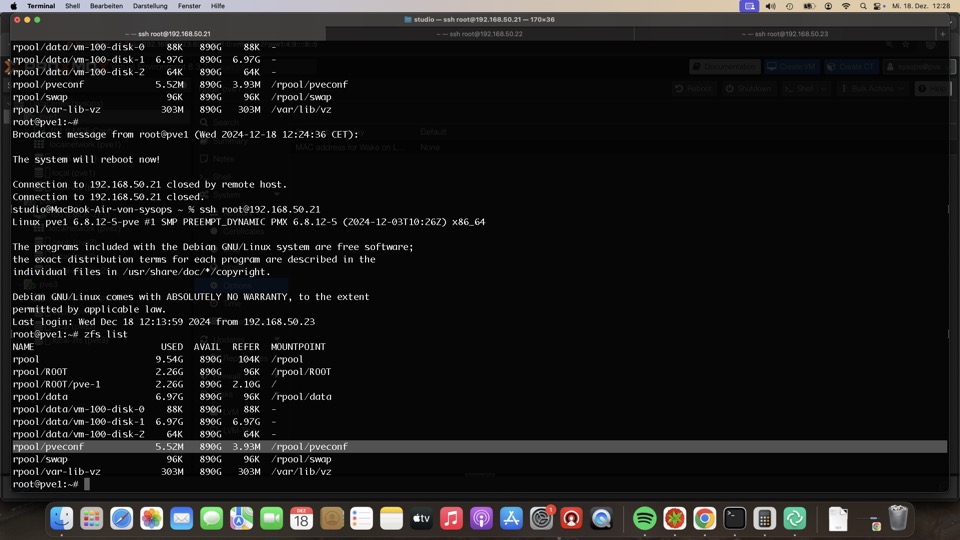
Wir sichern extra die /etc Ordner nach rpool/pveconf, da der Ordner /etc/pve aus einer Datenbank live erstellt wird. Er wäre bei einer Reparatur via Boot ISO leer!!!
Die ZFS auto Snapshots werden über die crontab ausgeführt. Dafür gibt es verschiedene Verzeichnisse:
- /etc/cron.hourly
- /etc/cron.daily
- /etc/cron.weekly
- /etc/cron.monthly
- /etc/cron.d (viertelstündlich)
In den Ordner liegt dann für jede "Aufgabe" ein eigene Datei (z.B. zfs-auto-snapshot), in welcher die auszuführen Kommandos enthalten sind. Dort ist auch hinterlegt wieviele auto snapshots aufgehoben werden sollenn. (--keep=96)
Die Zeitpunkte wann dieses ausgeführt werden sind in der Datei
/etc/crontabdefiniert. z. B. könnte dort der tägliche Zeitpunkt angepasst werden
Ebenfalls finden sich Skripte ab Werk unter /etc/cron.d für z. B. Scrubbing und Trimming am Sonntag. Nicht jedem taugt dieser Zeitpunkt!
cat /etc/crontab
# /etc/crontab: system-wide crontab
# Unlike any other crontab you don't have to run the `crontab'
# command to install the new version when you edit this file
# and files in /etc/cron.d. These files also have username fields,
# that none of the other crontabs do.
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.daily; }
47 6 * * 7 root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.weekly; }
52 6 1 * * root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.monthly; }
#
Zusätzlich gibt es für jeden User (z.B. root) noch eine eigene crontab, diese liegen unter cd /var/spool/cron/crontabs/. Dort gibt es dann eine Datei root für den User root, falls diese erzeugt wurde. Diese Datei wird z.B. auf den Linux VMs genutzt, um das Trimming zeitgesteuert ausgeführen zu können.
proxmox-boot-tool / ZFS Feature Upgrade / Trimming einschalten
Mit dem
promox-boot-toolkönnten Platten nach einen Hardwaretausch wieder bootfähig gemacht werden. Heute sollte nach Möglichkeit uefi Boot eingesetzt werden und nicht mehr legacy Boot, damit werden die Boot Platten automatisch erkannt und müssen nicht einzeln durch probiert werden, wie bei legacy boot. Autotrim sollte auf den SSD ZFS Datasets eingeschaltet sein, damit gelöschte Blöcke wieder im Dateisystem schnell verfügbar gemacht werden.
Optionale Funktionen zur ZFS Storage Optimierung
- zpool set autotrim=on rpool # für SSD Pools
- zpool set autoexpand=on rpool #vor Plattentausch auf größere Disks
- zpool upgrade #regelmäßig prüfen ob hier bei zpool status ein Hinweis ist. Der aktuelle PVE ISO Installer muss aber mit der Version bestückt sein, daher ggf. immer eine Version abwarten
- zpool trim rpool #test ob Trimming das System ausbremst
- zpool iostat -v 1 # Live Status
Einige wichtige Ordner vom Proxmox:
- Proxmox Konfiguration unter /etc/pve #Wie bereits oben erwähnt wird dieser Ordner nur zur Laufzeit von PVE aktiviert und ist bei einer Wiederherstellung per ISO leer! Daher unser Backup unter rpool/pveconf
- Template Ordner /var/lib/vz
- ISO Ablage Ordner /var/lib/vz/template/iso - z.B. virtio-win.iso
- Cache /var/lib/vz/cache/ z.B. *.tar.gz Proxmox Mailgateway
PVE startet noch, hat aber defekte Installation oder Konfiguration - Rollback vom Debian mit PVE
Wenn der Proxmox nicht mehr richtig funktioniert, werden die folgenden Schritte durchgeführt, um ihn wieder herzustellen zu können. Die erforderlichen ZFS snapshots werden durch die "Tools" des Postinstaller erzeugt.
Beim PVE Ordner (/etc/pve) handelt es sich um eine Datenbank (/dev/fuse 128M 20K 128M 1% /etc/pve), die ohne den Postinstaller nicht gesichert würden (rpool/pveconf 884G 128K 884G 1% /rpool/pveconf).
Daher sollte der Postinstaller aus dem Bashclub auf jeden Promox PVE installiert sein, damit die Konfigurationsverzeichnisse von Proxmox auf ZFS gesichert und mit Auto Snapshosts versehen werden !!!
-
Proxmox CD bzw. ISO booten - Debug auswählen
-
exit - damit nicht der Installer bootet zpool status zpool import # zeigt ob der Pool komplett und fehlerfrei ist, könnte ja ein Hardware Problem sein zpool import rpool # würde wegen letztem Zugriff durch Fremdsystem nicht reichen zpool import -f rpool zpool status zpool list zfs list -t snapshot rpool/ROOT/pve-1 Dann z. B. auf funktionierenden Stand zurückrollen... zfs rollback -r rpool/ROOT/pve-1@zfs-auto-snap.hourly\_2023-09-26-1251 # entsprechender snapshot - boot und Proxmox geht wieder ``` Reboot oder Reset Server
**Sollte der Rollback Punkt z. B. auf einen Punkt von PVE 7 zeigen, so kann man beim Booten einen älteren Kernel auswählen
Nach erfolgreichem Neustart empfehle ich
- proxmox-boot-tool refresh
- apt update
- apt dist-upgrade
- reboot als Test
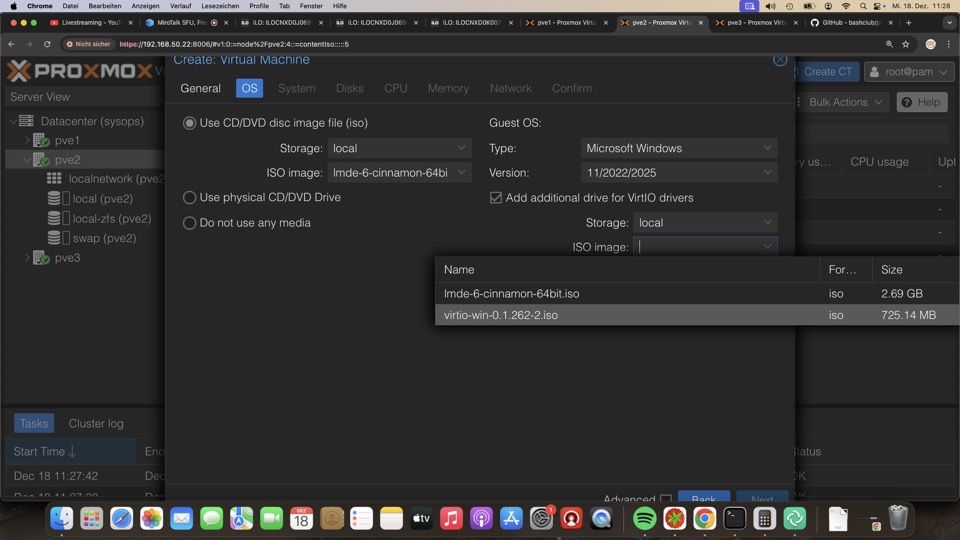
Installation Windows mit VirtIO Treiber
** Inzwischen installiert der Postinstaller einmalig eine aktuelle Virtio Treiber ISO als stabile Version - Für spätere Downloads...**
-
VirtIO Treiber im Internet finden
- Proxmox Windows Driver im Browser suchen
-
Auf Proxmox Seite nach Stable suchen
- Link kopieren
- In ProxMox GUI
- Download URL eintragen unter pvews - local (pvews) - ISO Images
- Filename: VirtIO-win.iso
- ISO Ablage Ordner **/var/lib/vz/**template/iso
- Download URL eintragen unter pvews - local (pvews) - ISO Images
-
Create VM
- General
- Node: pvews
- VM ID: 101
- Name: win
- Start at boot: Haken
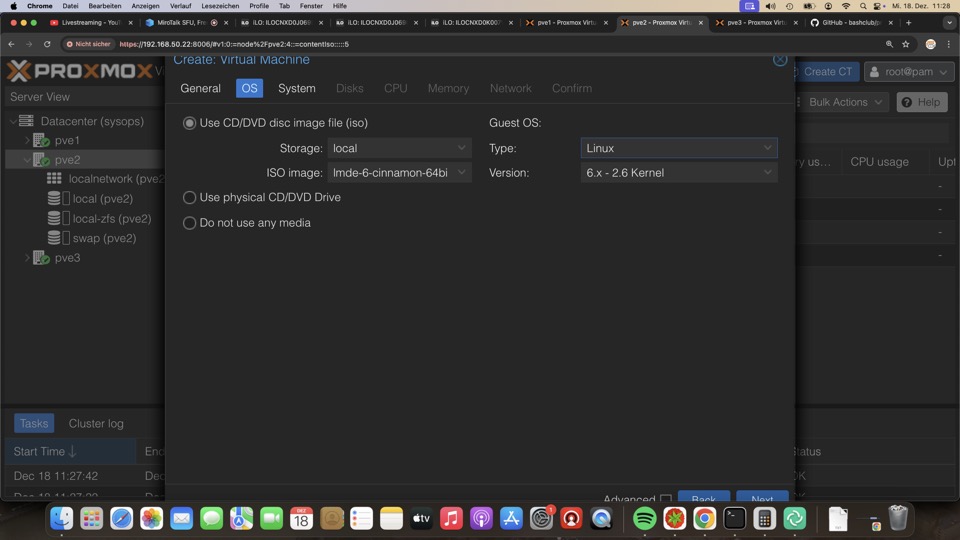
- OS
- Use CD/DVD disc image file (iso)
- Storage: local
- ISO Image: Win10_22H2_German_x64.iso
- Use CD/DVD disc image file (iso)
- System
- Maschine q35 # nicht i440fx
- BIOS: OVMF (UEFI)
- Add EFI Disk: Haken
- Emu Agent Haken
- EFI Storage: local-zfs
- SCSI Controller: VirtIO SCSI Single # Achtung bei Hotplug weiterer Platten muss im Geräte Manager der neue Controller gefunden werden oder Reboot!
- Disks
- Bus/Device: SCSI 0
- VirtIO Block ist obsolet !!!
- SCSI - VirtIO SCSI Single - steht auf der Seite davor - SCSI Contoller kann ein Prozessorkern pro Festplatte exklusiv nutzen
- Discard: Haken # für Trimming der VM
- SSD emulation: # Haken für Trimming
- Cache: - Default (no cache) - keine Cache einschalten !!!
- Bus/Device: SCSI 0
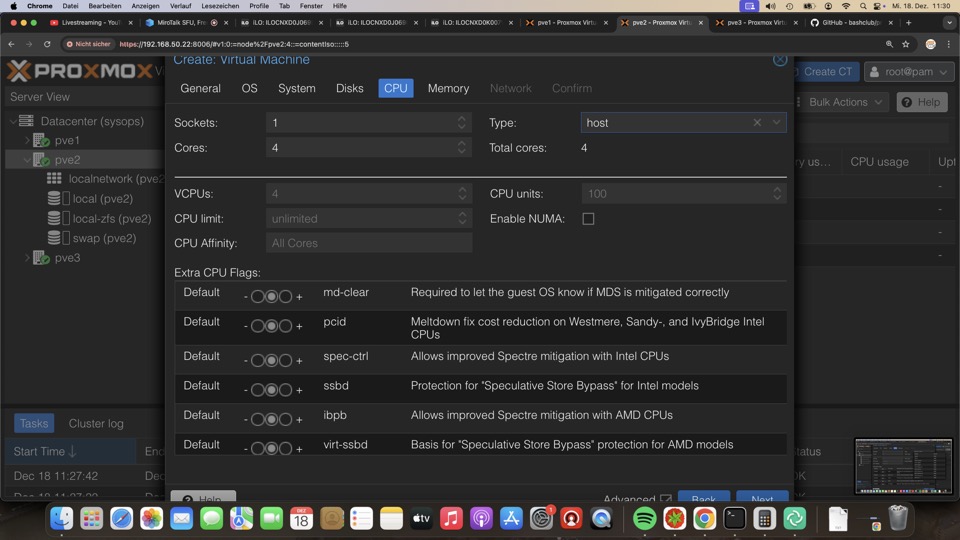
- CPU
- Socket: 1
- Cores: 4 # relativer Wert zu anderen VMs
- Type: Host (Standard: x64-64-v2-AES) # mit Host wird die CPU 1:1 abgebildet, AES und Co. reduzieren den Funktionsumfang der virtuellen CPU, erhöhen aber die Kompatibilität bei Migration zwischen nur ähnlichen PVE Hosts
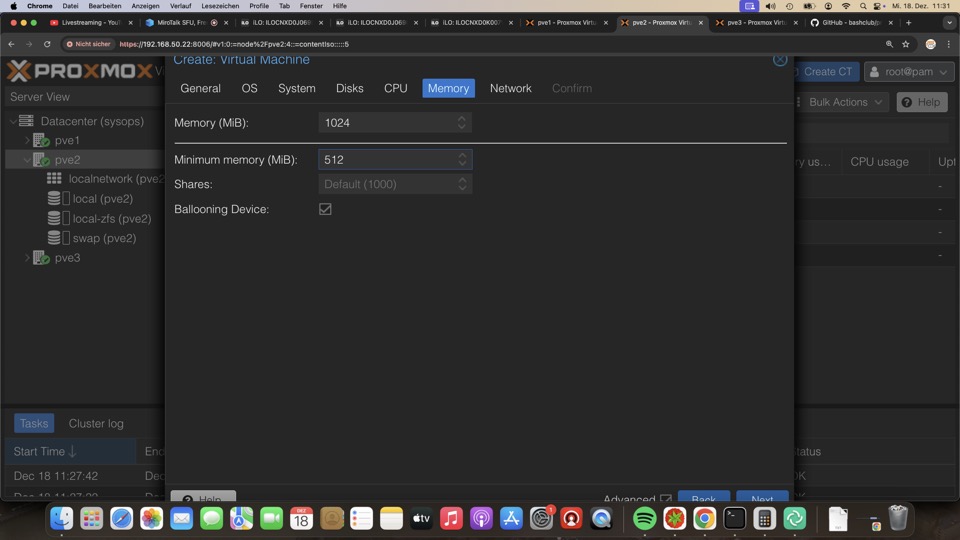
- Memory
- Memory: 4096
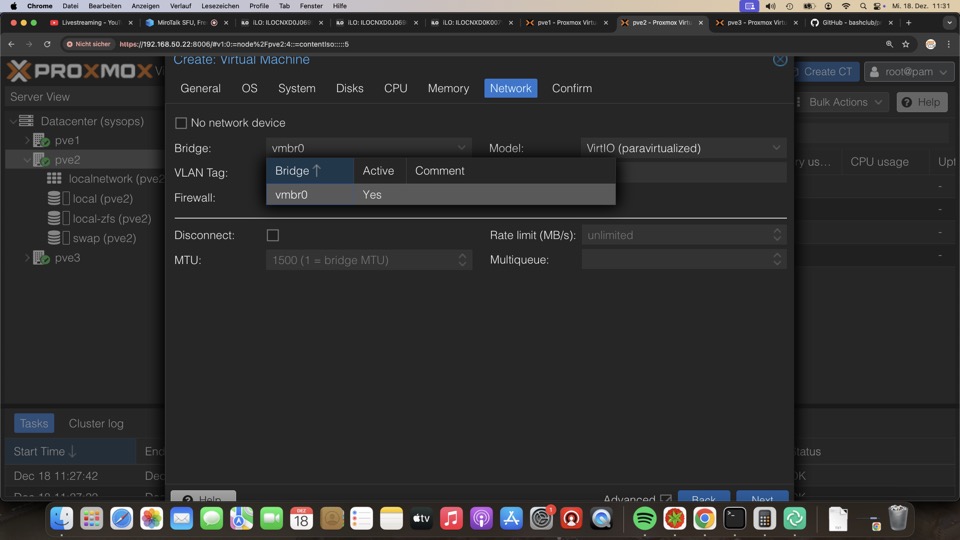
- Network
- Bridge: vmbr0
- Model VirtIO (paravirtualized) - kann mehr wie 1Gbit, 100Gbit möglich
- General
Inzwischen kann man die geladene virtio.iso als zweites Laufwerk in die VM einklinken
q35 Version 5.2 - weniger Probleme als mit Version 8.0 wegen deutschen Treibern - ist für US optimiert ... - Probleme mit Netzwerkkarten möglich
EFI hat feste Bildschirmauflösung - kann nur im EFI der VM eingestellt werden (EFI BIOS) - Im Bootvorgang in der Console (Proxmox GUI) - ESC drücken
Während der Installation am einfachsten nur die VIOSCSI Treiber installieren, da sonst keine Disks angeboten werden Den Rest des Setups von der VIRTIO ISO kann nach der Installation erledigt werden. Das spart die dummen Sicherheitsfragen und geht schneller.
Am Ende sollte auf der VM Statusseite die IP Adresse zu sehen sein, ansonsten noch prüfen ob der Haken bei Guest Agent an ist!
Für alle die von den APPS genervt sind etwas lustiges zum nachbasteln
Get-appxPackage | Remove-appxPackage # man verliert Taschenrechner - alle App werden entfernt - auch der Storage wird entfernt - Nach Feature Update wieder alles da
**Windows installiert am Ende des Setups eine Wiederherstellungspartition. Diese ist eventuell zu entfernen, da ansonsten kein Resize möglich ist. Der Resize ist auf der Disk in PVE jederzeit möglich
** Windows ist inzwischen in der Lage freie Blöcke an ZFS zurückzugeben, für den Fall daß wie beschreiben SCSI Single + SSD Emulation plus Discard gewählt wurde**
Optional noch Hilbernation Mode aus
-
attrib powercfg -h off # evtl. darf es der User nicht - powershell als administrator starten
Unser Datastore Swap kann genutzt werden um die Auslagerungsdatei auf eine eigene Disk zu legen. Das spart bei ramhungrigen Systemen viel Platz, da dort keine automatischen Snapshots ausgeführt werden. Die Platte muss nicht gesichert werden. Bei Linux bitte die Swap Disks mit Backup einmal sichern
Trimming unter Linux
-
Unter Linux wird nicht mehr benötigter Storage einer SDD wie folgt an ZFS freigeben
- Linux
/sbin/fstrim -av# für Linux VM, nicht LXC!
- Linux
-
Eine automatisierte Freigabe von nicht mehr benötigtem Storage, kann über die crontab in Linux gesteuert werden
- crontab -e # crontab für den User root
- 5 * * * * /sbin/fstrim -a # Der crontab Eintrag bedeutet, daß jede fünfte Minute der vollen Stunde getrimmt wird
- crontab -e # crontab für den User root
fstrim -av # muss eine Ausgabe bringen - sonst ist die VM falsch konfiguriert - VM Platten auf SSD und Discard umstellen
Festplatten Tausch bei Defekt oder S.M.A.R.T Fehler
- Artikel von ProMox - ist nicht ganz korrekt: https://pve.proxmox.com/wiki/ZFS_on_Linux
Es reicht nicht mit zpool replace eine fehlende oder defekte Disk zu ersetzen. Sie könnte danach nicht booten. Wir benötigen ebenfalls zwei Partitionen mit dem Bootimage!
Der Fall beschreibt den Tausch optional gleich gegen eine größere Festplatte oder SSD
Erklärung zum Kommando sgdisk ... -- R ...
-
sgdisk \<gutes boot device\> - R \<neue Platte\># Partitionen werden kopiert und die GUID wird beibehalten - Soll eine neue GUID verwendet werden
sgdisk -G \<neue Platte\>
dmesg -Tw
Platte einbauen und Output prüfen, sdf ist neue Disk
zpool set autoexpand=on rpool # Erweiterung des Pools erfolgt am Ende automatisch! Bei Raid 10 reicht es zwei Disks zu Tauschen, bei RaidZx müssen allte getauscht werden um den Platz zu erweitern!
ls -althr /dev/disk/by-id | grep sdf (sdf wurde als neue Disk erkannt)
zpool status
Output zeigt aktive oder defekte Disks
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ata-INTEL_SSDSC2KB019T8_PHYF951101ZS1P9DGN-part3 ONLINE 0 0 0
ata-INTEL_SSDSC2KB019T8_PHYF951102271P9DGN-part3 ONLINE 0 0 33
Wir tauschen nun die zweite Disk vorsorglich
-part3 zeigt deutlich daß es sich hier um die dritte Partion handelt die ersetzt werden muss, folglich sind Parition 1 und 2 zum booten!!!
ls -althr /dev/disk/by-id | grep ata-INTEL_SSDSC2KB019T8_PHYF951102271P9DGN-part3
lrwxrwxrwx 1 root root 10 Oct 15 17:38 ata-INTEL_SSDSC2KB019T8_PHYF951102271P9DGN-part3 -> ../../sdb3
Wir müssen also sdb3 ersetzen
Als erstes Paritionstabelle übernehmen und erweitern, falls größere Disk
sgdisk /dev/sdb -R /dev/sdf #sdb ist eine gute Disk, sdf die neue Disk
sgdisk -G /dev/sdf # neue GUID damit EFI die Disk unterscheiden kann
proxmox-boot-tool format /dev/sdf2 #format mit fat32
proxmox-boot-tool init /dev/sdf2 #kopiert Bootimage und notiert die Disk für künftige Updates
Optional
cfdisk /dev/sda # Partition vergrößern
** Beim nächsten sgdisk der Paritionstabelle einfach die große Disk als Vorlage nehmen
Jetzt den eigentlichen Datenbestand ersetzen
ls -althr /dev/disk/by-id | grep sdf | grep part3
zpool replace rpool ata-INTEL_SSDSC2KB019T8_PHYF951102271P9DGN-part3 ata-INTEL_SSDSC2KB019T8_PHYF95111111PXXX-part3
** Kontrolle des Erfolgs mit
zpool status # da soll dann die alte Disk raus sein und keine Fehler
zpool list # eventuell mehr freier Speicher nach Austausch von zwei Disks oder mehr
proxmox-boot-tool status #sollte zwei Treffer und einen Fehler melden, wegen gezogener defekter Disk
proxmox-boot-tool clean entfernt tote Bootdatenträger
Windows kaputt machen - Trojanersimulation
- Netwerkkarte disablen durch Trojaner
- VM herunterfahren
- Entwicklung der Größe der snapshot‘s - als Indikator
- Trojaner verursacht eine größere Änderung in den snapshots
- Rollback snapshot über Cockpit oder über command Line
ZFS Cache
- Parameter -n: dry-run
- erstmal anschauen, was das Kommando machen würde
zpool add -n rpool cache ata-intense..
zpool add -nf rpool cache ata-intense.. # wenn schon Daten auf der Platte
zpool add -f rpool cache ata-intense..
zpool iostat -v 3
zpool iostat -v 1 # 1 sec
Das Wort "cache" im Kommando ist sehr wichtig, da sonst die Platte evt. als einzel Mirror an den stehenden Mirror angehängt wird und das wollen wir nicht, daher immer mit -n testen !!!
Proxmox Cluster
-
GUI - Cluster - create cluster
-
pvecm create „clustername“
-
GUI - Cluster - „add Cluster“
-
pvecm add clusterserver1
-
Kein Cluster mehr
-
https://pve.proxmox.com/wiki/Cluster_Manager#_remove_a_cluster_node
-
Auf der Seite zu den folgendem Punkt springen: First, stop the corosync and pve-cluster services on the node:◦
-
cd /etc/pve
-
storage.cfg
-
qemu-server/*.conf
-
lxc/*.conf
-
nodes/... # Ordner mit den Cluster Member
-
top ps aux ps aux | grep qm # Herstellung aller Maschinen anhand dieser Ausgabe -
Login in den Cluster funktioniert nach dem Fehlschlag nicht mehr
service pveproxy restart
- Neues Zertifikat - zwei Faktor Authentification der lokal User fliegt heraus
cd /rpool/pveconf
zfs list -t snapshot rpool/ROOT/pve-1
- PVE Config zurück rollen
zfs rollback -r rpool/ROOT/pve-1@zfs-auto-snap_hourly-2023-09-28-1017 # panic Variante und Stromkabel nach 2 s
-
besser von cd booten, rollback wie oben
-
Ordner .zfs unter /rpool/pveconf
-
cd snapshot # dieser Ordner nur in datasets vorhanden # Snapshot Order auswählen cd zfs-auto-snap_hourly-2023-09-28-0717 cd etc/pve/nodes/pvews cd lxc ls cp 100.conf /etc/pve/lxc cd .. cd qemu-server cp 101.conf /etc/pve/qemu-server # evtl. Alternativ cp 101.conf /etc/pve/nodes/pvews/qemu-server vi /etc/pve/nodes/pvews/qemu-server/101.conf # Anpassung von Namen -
Boot Partitionen löschen
- Über dd
dd if=/dev/zero of=/dev/sda2 bs=1M count=511
dd if=/dev/zero of=/dev/sdd2 bs=1M count=511
proxmox-boot-tool status
-
Boot über CD/DVD - Advanced - debug mode console
-
Type exit - damit Installer nicht startet
-
https://pve.proxmox.com/wiki/ZFS:_Switch_Legacy-Boot_to_Proxmox_Boot_Tool
-
Aus der Webseite:
- Repairing a System Stuck in the GRUB Rescue Shell
-
If you end up with a system stuck in the grub rescue> shell, the following steps should make it bootable again:
-
Boot using a Proxmox VE version 6.4 or newer ISO
-
Select Install Proxmox VE (Debug Mode)
-
Exit the first debug shell by typing Ctrl + D or
exit -
The second debug shell contains all the necessary binaries for the following steps
-
Import the root pool (usually named rpool) with an alternative mountpoint of /mnt:
-
zpool import -f -R /mnt rpool zfs list -
Find the partition to use for proxmox-boot-tool, following the instructions from Finding potential ESPs
-
Bind-mount all virtual filesystems needed for running proxmox-boot-tool:
-
mount -o rbind /proc /mnt/proc
-
mount -o rbind /sys /mnt/sys
-
mount -o rbind /dev /mnt/dev
-
mount -o rbind /run /mnt/run
-
ls /mnt
-
change root into /mnt
-
chroot /mnt /bin/bash
-
- Repairing a System Stuck in the GRUB Rescue Shell
-
cat /etc/network/interfaces
- Zeigt die Netzwerk Interface Einstellungen
-
proxmox-boot-tool status lsblk proxmox-boot-tool format /dev/sdb2 proxmox-boot-tool format /dev/sdc2 proxmox-boot-tool init /dev/sdb2 proxmox-boot-tool init /dev/sdc2 proxmox-boot-tool status proxmox-boot-tool clean zpool export rpool # Falls der `zpool export` vergessen wurde, nach dem reboot `zpool import -f rpool` -
<CTRL> <ALT> <ENF> # reboot auslösen
-
zpool import -f rpool # letzter Besitzer war CD exit # erneuter reboot zpool status -
Wichtige Dateien:
- /etc/network/interfaces
- storage.cfg
- qemu-server/*.conf
- lxc/*.conf
-
Boot Partitionen löschen
- cfdisk /dev/sdb
- Partition 1 und Partition 2 löschen ◦
- fdisk /dev/sdc
- Partition 1 in Partition 2 löschen
- reboot
- cfdisk /dev/sdb
-
Proxmox neu installieren auf cache SSD ohne ZFS
-
Boot von CD
-
Install Proxmox ohne ZFS auf SSD
-
Würde mit ZFS installiert, hätten wir wieder ein rpool und müssten den original Pool rpool in z.B. rpool1 umbenennen und local-zfs anpassen !!!!
-
Profi Tipp: Alle anderen Platten ziehen, damit auf keiner falschen Platten installiert wird
-
Installation mit ext4 mit lvm
-
Neues Zertifikat
-
Passwort neu
-
ssh meckert wegen known_hosts # Neu Installation
-
zfs list # zeigt leere Liste zpool import -fa # alle importieren zfs list # rpool ist wieder da cd /rpool/pveconf cd etc cd pve ls cp storage.cfg /etc/pve cd qemu-server cp 101.conf /etc/pve/qemu-server # Produktiv System cp *.conf /etc/pve/qemu- server cd .. cd lxc cp 100.conf /etc/pve/lxc # Produktiv System cp *.conf /etc/pve/lxc
-
-
ISO‘s als DVD heraus werfen, da vermutlich nicht gesichert
-
zpool remove rpool <cache ssd> # cache ssd entfernen # atach und detach nur mirror - alles andere wird removed
-
Am Abend wieder ganz machen
- Booten von CD/DVD
- Advanced Mode - Debug mode
-
Partitionstabelle wiederherstellen
-
Anderen Proxmox anschauen
-
https://pve.proxmox.com/wiki/ZFS:_Switch_Legacy-Boot_to_Proxmox_Boot_Tool
-
Repairing a System Stuck in the GRUB Rescue Shell
-
zpool import -f -R /mnt rpool zfs list -
Find the partition to use for proxmox-boot-tool, following the instructions from Finding potential ESPs
-
Bind-mount all virtual filesystems needed for running proxmox-boot-tool:
-
mount -o rbind /proc /mnt/proc mount -o rbind /sys /mnt/sys mount -o rbind /dev /mnt/dev mount -o rbind /run /mnt/run chroot /mnt /bin/bash # Partitionstabelle eines anderen ProxMox Systems anschauen sgdisk /dev/sdd -R /dev/sdb # muss resized werden cfdisk /dev/sdb -
Partition 3 wieder vergrößern # Werte überprüfen mit Foto falls vorhanden
-
sgdisk /dev/sdb -R /dev/sdc sgdisk -G /dev/sdb sgdisk -G /dev/sdc -
Änderungen haben nicht gegriffen - reboot erforderlich # alternativ parted - partprobe bekommt das im laufenden Betrieb hin
-
Reboot
-
Evtl. mit
proxmox-boot-toolPartitionen wieder herstellen, zuvor muss die Proxmox Umgebung über die chroot Umgebung gebaut werden ... -
reboot zpool import -fa exit # reboot vom ProxMox zpool status proxmox-boot-tool status
-
-
-
-
-
Variante für das Arbeiten
- Externe SSD - True NAS installieren - geht aber nur für VM‘s - VM‘s per SCSI freigeben
-
Backup Proxmox Datenbank - Wie funktioniert das ?
-
cat /etc/cron.d/pve-conf-backup-
rsync. -va --delete /etc /rpool/pveconf# alle 15 min - ab 3. Minute
-
-
Import Daten
-
vmdk vhdx raw qcow2 > mounten vom original (VM aus!) /mnt/pve/nfsstore oder smbshare
-
zvol / lvm / usb / hdd /ssd
-
qm importdisk 100 /mnt/hypervfreigabe/dc.vhdx local-zfs# (via samba) -
qm importdisk 100 /mnt/pve/nfsstore/vmfs/id/dc/dc.vmdk local-zfs #(via NFS oder SSHFS) -
Echte Systeme (physikalische Server)
-
Clonezilla
-
https://pve.proxmox.com/wiki/Migration_of_servers_to_Proxmox_VE
- Clonezilla Live CDs
-
Disks erscheinen erst mal unused - mit Doppelklick hinzufügen und booten
-
-
Backup und Monitoring
- Backup Dataset dürfen keine auto snapshots machen
-
zfs set com.sun:auto-snapshot=false backup# siehe Codeblock
-
zfs list # Ziel Backup Disk - Pool Backup
zfs create backup/repl -o com.sun:auto-snapshot=false
zfs set com.sun:auto-snapshot=false backup
bash-club-zfs-push-pull # auf Ziel ausführen
- bashclub zfs-push-pull installieren
git clone https://github.com/bashclub/bashclub-zfs-push-pull.git
cd bashclub-zfs-push-pull
chmod +x 02pull
bashclub-zfs
cp bashclub-zfs /usr/bin
vi 02pull # Anpassen - In for Schleife ein echo zum Testen
bashclub-zfs # Parameter I und R - alte Snapshot und Zwischen-snapshots mitnehmen # Prinzipiell pull !!! - Quelle kommt nicht auf das Ziel, sondern nur Ziel kommt auf Quelle
cp 02pull /etc/cron.hourly
Für Trojaner sicher immer die "pull Methode" anwenden. Nur Ziel kommt auf die Quelle und nicht umgekehrt.
Monitoring
- ID: backup-repl
- ZFS Pool: backup/repl
- Thin provision: Haken
- Block Size: 16k
- https://github.com/bashclub/check-zfs-replication
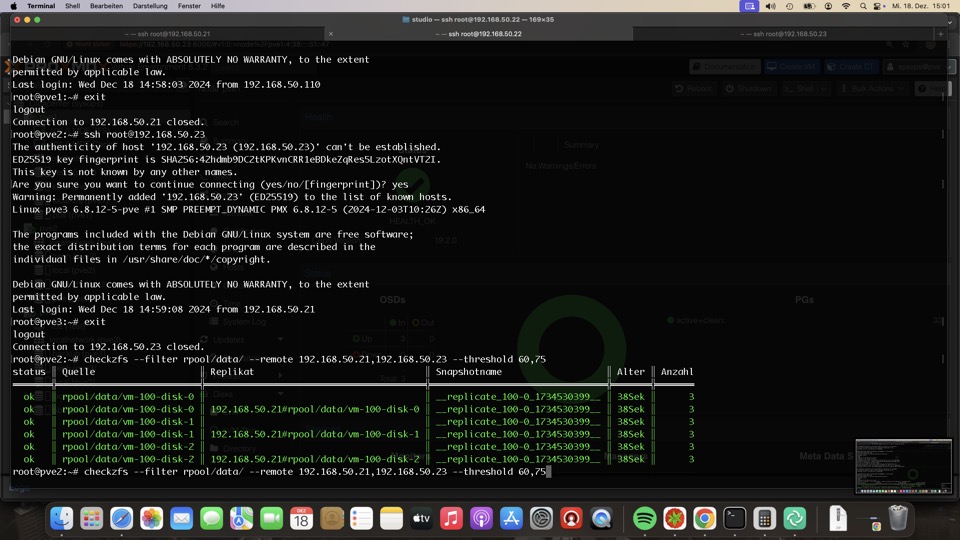
wget -O /usr/local/bin/checkzfs https://raw.githubusercontent.com/bashclub/check-zfs-replication/main/checkzfs.py
chmod +x /usr/local/bin/checkzfs
checkzfs --sourceonly
checkzfs --filter rpool/data/ --replicafilter backup/repl --threshold 75,90
checkzfs --filter rpool/data/ --replicafilter backup/repl --threshold 75,90 --columns +message
-
wget -O /usr/local/bin/checkzfs https://raw.githubusercontent.com/bashclub/check-zfs-replication/main/checkzfs.py-
Keep: Hours 96, dayly 14
-
ProxMox GUI
- Storage - Add ZFS
-
cd /etc/pve/qemu-server cp 101.conf 9101.conf vi 9101.conf -
Kommando im vi ausführen - local-zfs durch backup-repl ersetzen
- :%s/local-zfs/backup-repl/g # vi command
-
Swap entfernen
-
DVD Laufwerke entfernen
-
Name am Anfang repl- anfügen
-
- GUI der VM 9101
- Netzwerkkarte deaktivieren # Befehl kann man nachher in der conf nachschauen
- Autostart disablen
- VM 9101 starten # aber Replikationszeit beachten - cron.hourly
- LXC Container kann mittlerweile die Netzwerkkarte deaktivieren - alternativ in anderen vswitch
checkzfs --filter rpool/data/ --replicafilter backup/repl --threshold 75,90 --columns +message --output checkmk
# Datei generieren und auf anderen Server kopieren - über scp
zfs mount -a
ls /backup/repl/subvol-100-disk-0/etc/pmg
mkdir /mnt/restore
mount /dev/zvol/backup/repl/vm-101-disk-1-part3 /mnt/restore
ls /mnt/restore # Damit kann man Daten aus dem Windows zurückspielen
umount /mnt/restore
zfs create backup/klon -o com.sun:auto-snapshot=false
zfs list -t snapshot backup/repl/vm-101-disk-1
zfs clone backup/repl/vm-101-disk1@bashclub-zfs_2023-09-28_16:21:30 backup/klon/vm-101-disk-1
mount /dev/zvol/backup/klon/vm-101-disk-1-part3 /mnt/restore
ls /mnt/restore
vi /etc/pve/qemu-server/9101.conf # Anpassung das der Klon verwendet wird
- VM aus Klon booten und sich anschauen ...
umount /mnt/restore
zfs get guid
zfs get guid | grep bashclub-zfs_2023-09-28_16:46:50
zfs get creation rpool/data/subvol-100-disk-0@bashclub-zfs_2023-09-28_16:46:50
-
zfs Replication für arme
-
backup/repl # pull - Trojaner sicher
zfs snapshot rpool/data/vm-100-disk-0@snap1 # snapshot auslösen
zfs send rpool/data/vm-100-disk-0@snap1 | zfs recv -dvF backup/repl # local
zfs send rpool/data/vm-100-disk-0@snap1 | ssh rot@zielip zfs recv -dvF # anderes System
- backup/repl # push - Quelle kommt auf Ziel !!! (Risiko Securtiy)
ssh root@sourceip zfs send rpool/data/vm-100-disk-0@snap1 | zfs recv -dvF backup/repl # pull
- checkzfs mit Mail - dafür muss Mail konfiguriert sein
checkzfs --filter rpool/data/ --replicafilter backup/repl --threshold 75,90 --columns+message --output mail
Verschlüsselung mit Proxmox, ZFS und Debian / Windows
Hier mal zur Überlegung was für einen Sinn macht
Physischer PC
- Festplatte
- Partition mit FS
- Mount / c:\
- Partition mit FS
Proxmox LXC
- Festplatte+Festplatte als Raid
- Dataset
- Mountpoint /rpool/data/subvol-100-disk-0
- Dataset
Proxmox LXC ZFS verschlüsselt
- Festplatte+Festplatte als Raid
- Dataset entsperrt
- Mountpoint /rpool/data/subvol-100-disk-0
- Dataset entsperrt
zfs create rpool/encrypted -o keylocation=prompt -o keyformat=passphrase -o encryption=on
#Datastore im PVE anlegen auf rpool/encrypted
nach Reboot zfs load-key #Passphrase eingeben, dann pct start xxx
Alternativ kann man das auch von außen alle Stunde auf Verdacht oder nach Prüfung per SSH auslösen
Proxmox VM
- Festplatte+Festplatte als Raid
- ZVOL
- Gast Partition mit FS
- Mount / c:\
- Gast Partition mit FS
- ZVOL
Proxmox VM ZFS verschlüsselt
- Festplatte+Festplatte als Raid
- ZVOL entsperrt
- Gast Partition mit FS
- Mount / c:\
- Gast Partition mit FS
- ZVOL entsperrt
zfs create rpool/encrypted -o keylocation=prompt -o keyformat=passphrase -o encryption=on
#Datastore im PVE anlegen auf rpool/encrypted
nach Reboot zfs load-key #Passphrase eingeben, dann qm start xxx
Alternativ kann man das auch von außen alle Stunde auf Verdacht oder nach Prüfung per SSH auslösen
Proxmox VM Gast verschlüsselt
- Festplatte+Festplatte als Raid
- ZVOL
- Volumemanager
- LV mit encrypted FS
- entsperrter Mount / c:\
- LV mit encrypted FS
Verschlüsselung wird bei der Installation vorgenommen. Nach jedem Reboot muss das Passwort in KVM Konsole von Proxmox eingegeben werden. Automatisierung nicht möglich
Abschließend ist das Ziel zu prüfen. Verschlüsselung gegen Diebstahl ist die ZFS Lösung völlig ausreichend. Replikation geht mit Raw (send -w), Backup nur wenn entsperrt ist. Eine Sicherung einer intern verschlüsselten VM ist jederzeit, mit jeder Methode (PBS, ZFS) möglich, muss halt in jeder VM vorgenommen werden, LXCs lassen sich verschlüsselt nur gegen Diebstahl schützen, nicht gegen Einsicht.
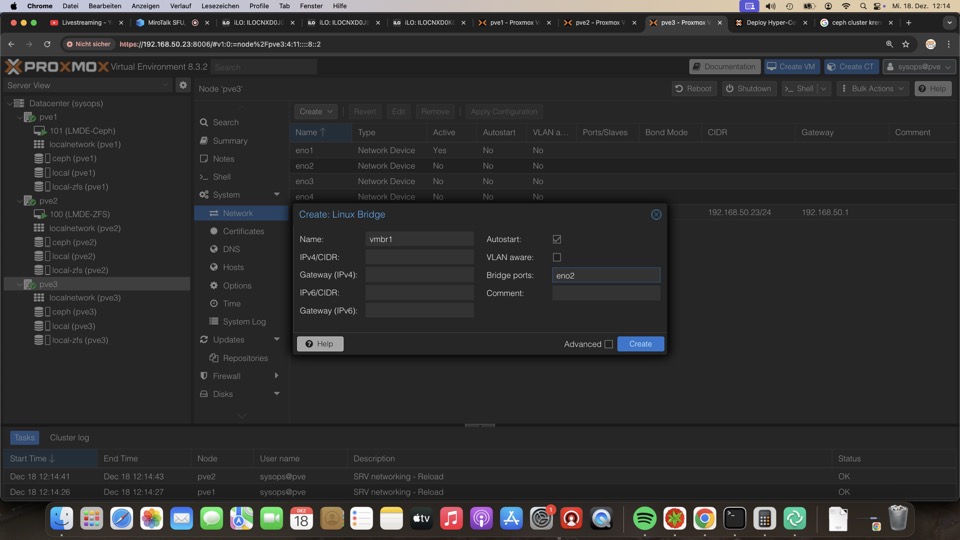
Proxmox Best Practice Setup für ZFS und / oder Ceph im Cluster für Einsteiger (Stand Dezember 2024)
Der Verfasser des Artikels, Christian-Peter Zengel, hat zum Zeitpunkt des Artikels ca 15 Jahre Erfahrung mit ZFS und Proxmox. Er betreibt aktuell ca 150 Systeme mit Proxmox und ZFS
Das Einsatzgebiet geht von Standaloneinstallation bis zu ca 10 Hosts im Cluster. Es ist keine Ceph Expertise vorhanden!
Dieser Dokumentation basiert auf diesem online Kurse von cloudistboese.de
18.12.2024 - 11h Proxmox Best Practice Cluster mit ZFS + Ceph für Einsteiger
ZFS ist die perfekte Grundlage für kleine und mittlere Kunden komplett unverwundbar gegen Ausfall, Trojaner und vor allem Dummheit zu sein.
Ceph ist die Basis der höchsten Verfügbar- und Skalierbarkeit
In diesem Kurs vermitteln wir ZFS und Ceph Grundkenntnisse für Proxmox
Achtung: Das Tempo dieses Kurses ist relativ schnell, dafür werden alle Schritte mit Screenshots dokumentiert!
Er eignet sich für den schnellen Einstieg mit mit Wissen aus zuverlässiger Quelle.
Dauer ca 4h+
- Basisinstallation Proxmox VE mit EFI auf ZFS
- Installation und Hinweise auf Fehlerbehebung von PVE-Clustern
- Einrichtung eines einfachen Ceph Clusters
- Musteranlage einer VM und LXC für höchste Leistung und Platzersparnis
- Konfiguration einer Hochverfügbarkeit für eine VM
- Replikation mit Bordmitteln und deren Erfolgskontrolle
- Automatisches Snapshotting von ZFS + Ceph mit CV4PVE + Admin GUI
- Einrichtung Proxmox Backupserver auf LVM oder ZFS mit Sicherheitsoptimierung
- Monitoring mit Check_MK plus Special Agent
Nach diesem Kurs kannst Du Proxmox im Cluster sicher und einfach betreiben.
Für erweiterte Trojanerabwehr bitte den Trojanersicherkurs besuchen.
Der folgende Artikel eignet sich besonders für Einsteiger die mit mehr als einem Host im Cluster starten müssen.
Der Bezug auf Ceph soll lediglich zum Funktionsvergleich dienen. Wir empfehlen bis 10 Hosts immer ZFS!
Installation Proxmox
Ein System hat extra Platten für unseren Workshop, zwei wurden bereits installiert.
Es kommt der HPE Microserver Gen10 Plus V2, vorzugsweise mit ECC, zum Einsatz

Wir installieren mindestens einen Raid1, 10 oder Z, niemals auf Basis eines Hardware Raid Controllers!
Für Cluster dringend alle IPs und Namen vorher klären, sonst kommt es zu späteren Zusatzarbeiten für den Cluster

Cluster mit drei PVE erstellen
Cluster wird in Sekunden erzeugt, ein Node alleine läuft problemlos
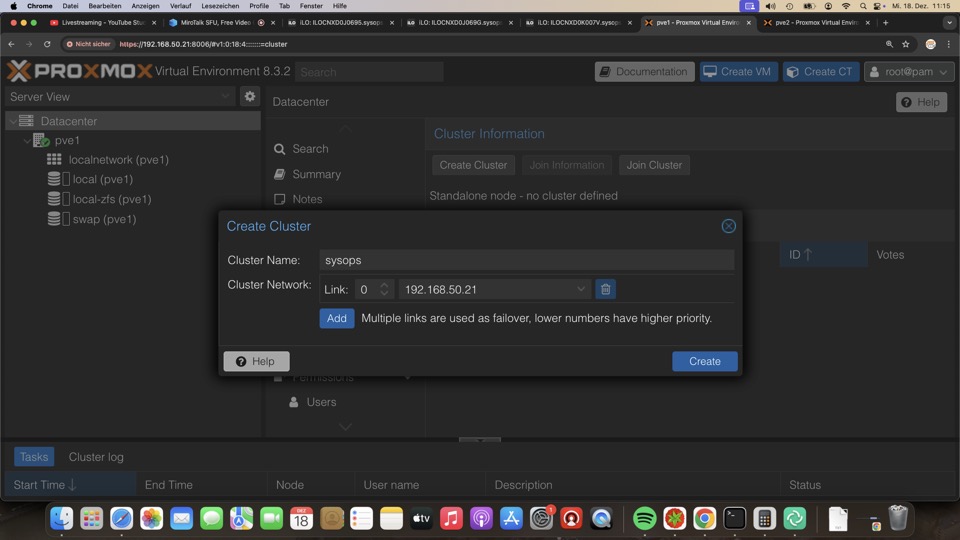
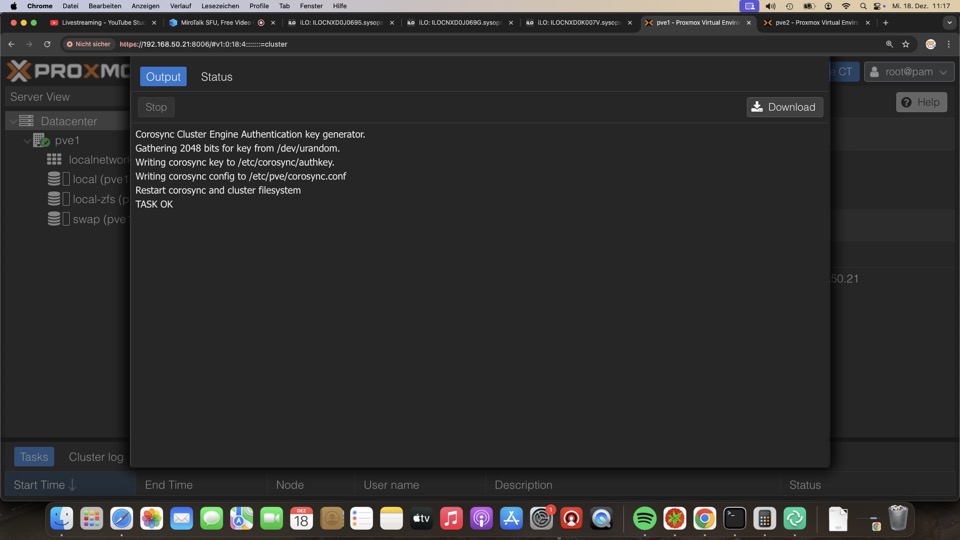
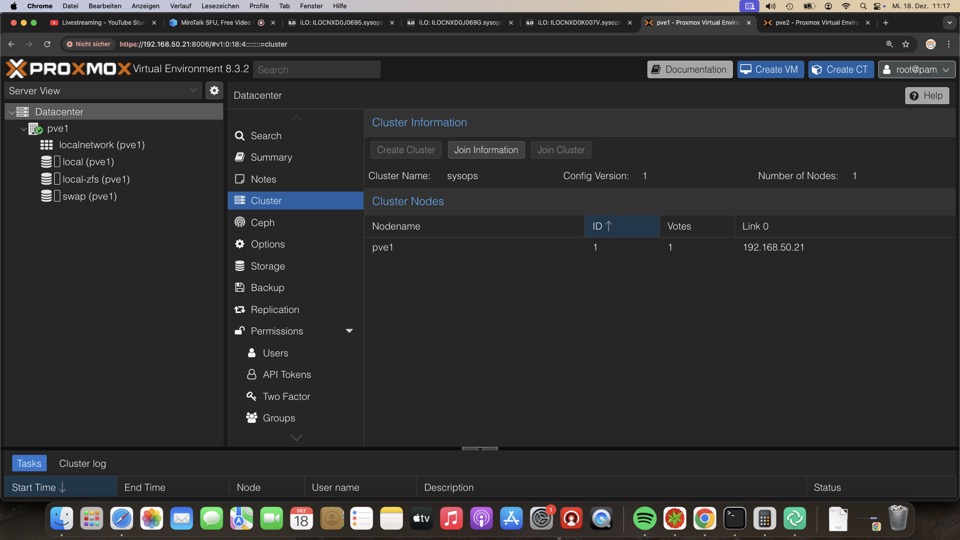
Cluster Nodes hinzufügen
Nodes mit den Join Information des ersten Clusternodes in der Zwischenlage auf neuen Node unter Join Cluster Einfügen und Rootpasswort und Clusternetz(e) bereitstellen
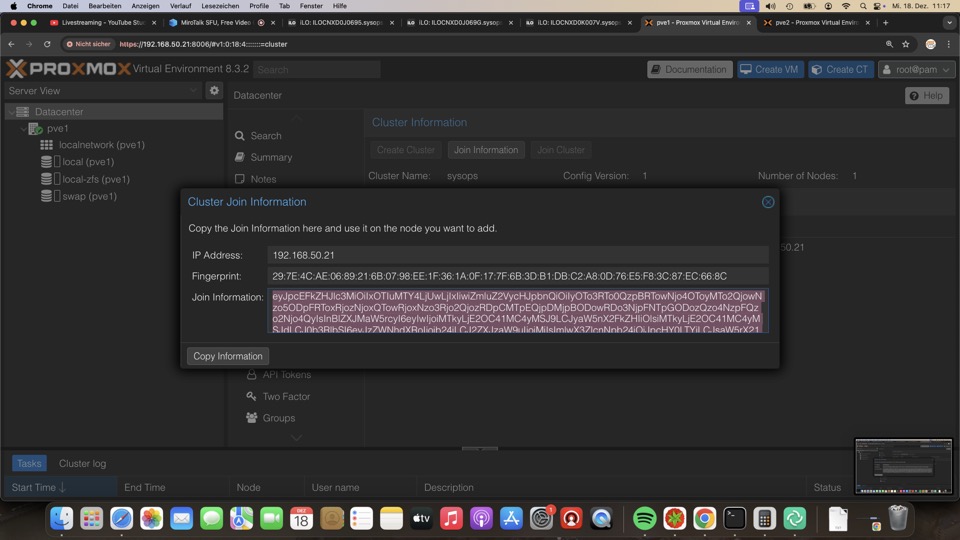
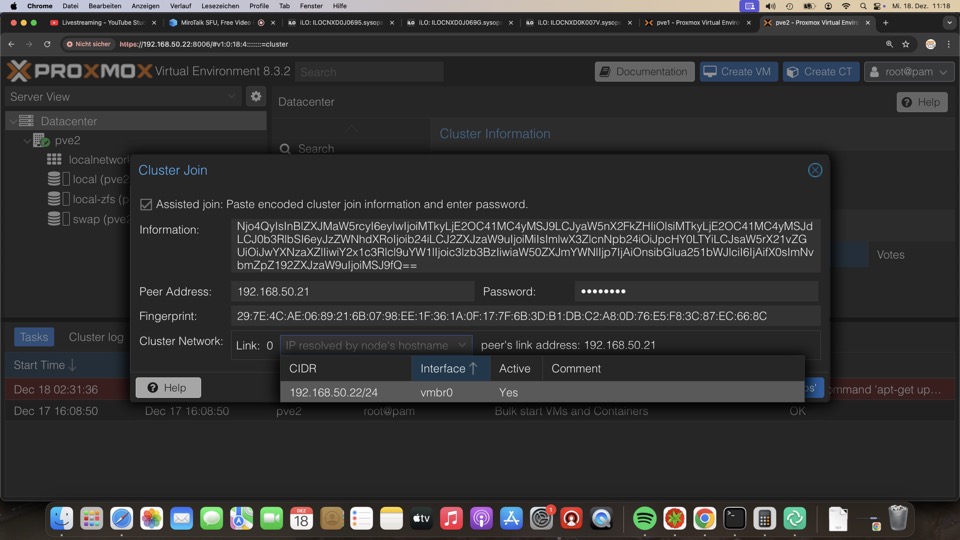


Der neue Node wird im Vorgang die Verbindung zum Browser verlieren, da er Schlüssel und Zertifikate des Clusters übernimmt. Der Browser muss neu geladen werden. Danach ist die Administration von jedem Clustermitglied aus möglich.
Lokale Storages benötigen lokalen Login zum Einrichten
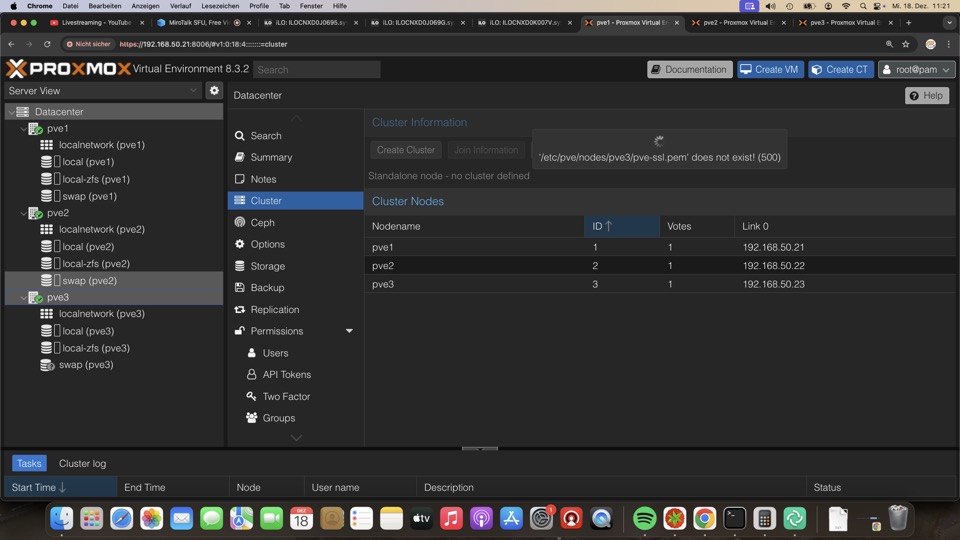
Postinstaller für erweiterte Funktionen
Unser Postinstaller vom #Bashclub funktioniert am besten mit Standalone.
Für unser Setup verzichten wir auf Autosnapshots für rpool/data, also dem local-zfs Store und auf das SSH-Hardening, aus Kompatibilitätsgründen
Diese Zusammfassung zeigt die für unser Setup günstigsten Settings, mehr Kontext im Kurs
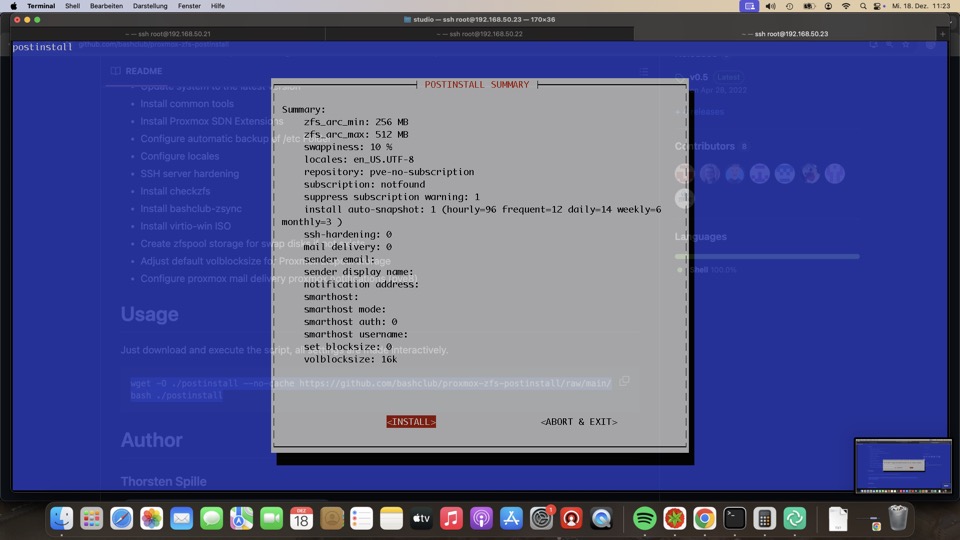
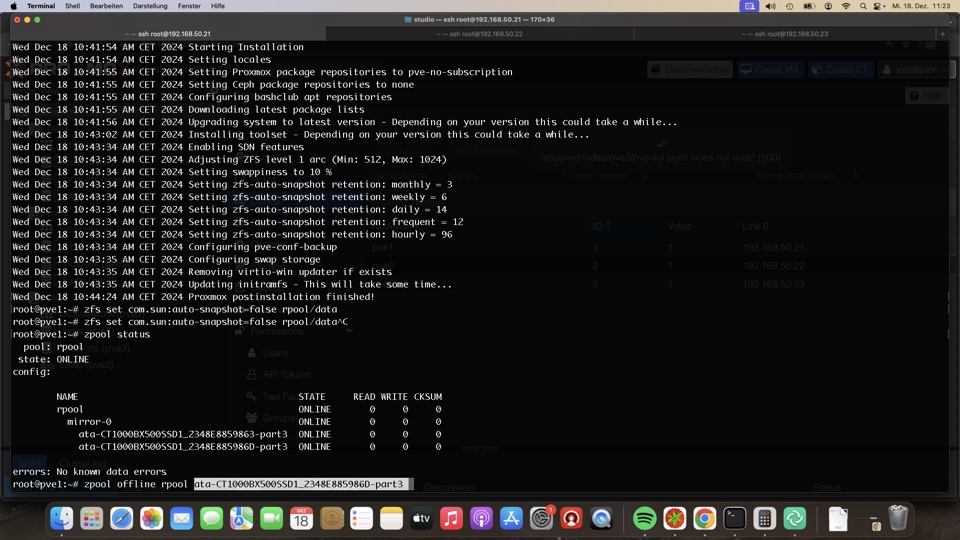
Demonstration ZFS Raid
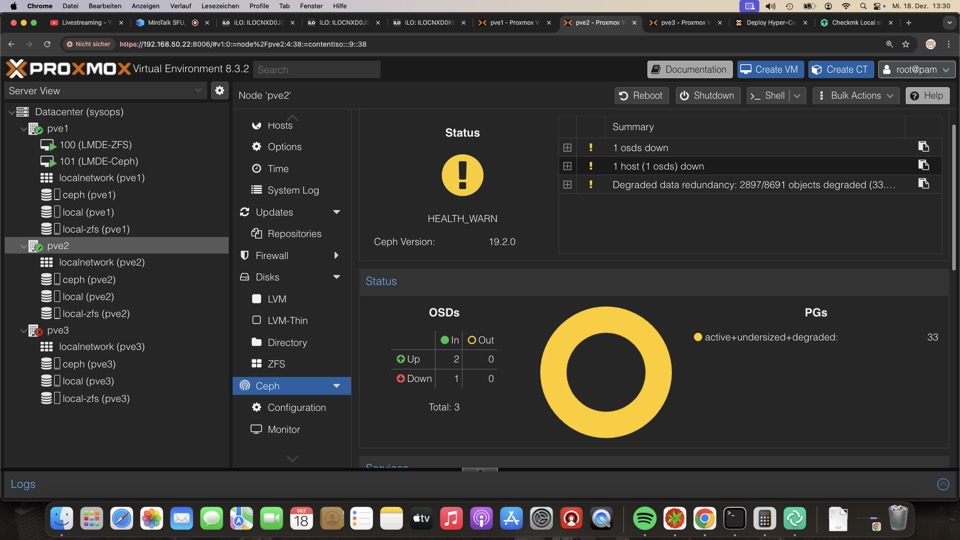
Software Raid mit ZFS ist ultra schnell bei Problemen entstört. Der direkte Zugriff auf die Platten bringt via Monitoring Probleme vor Ausfall zum Vorschein. Im Beispiel packen wir eine Platte vor Reboot offline, bitte nicht nachmachen!
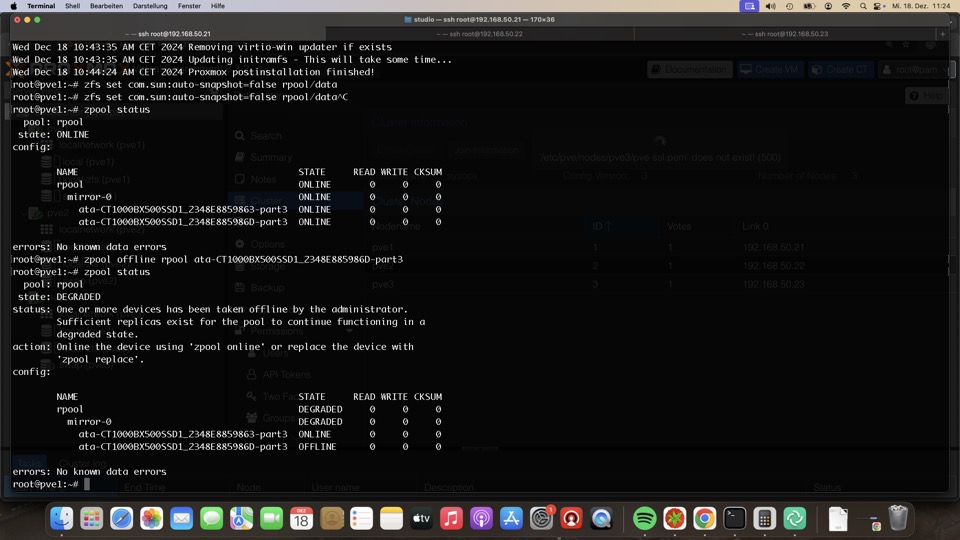
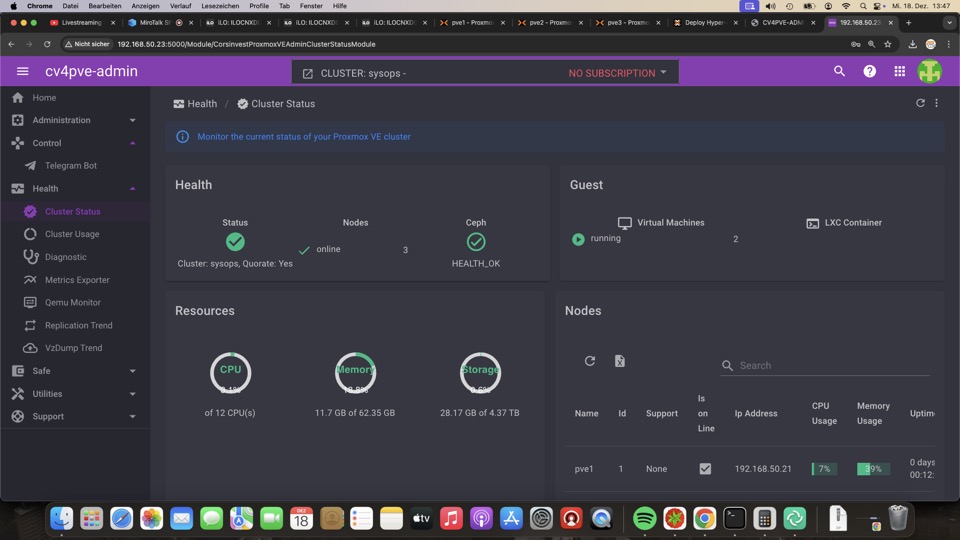
Trotz defektem Raid zeigt das Summarydashboard kein Problem. Hier muss mit Check_MK oder CV4PVE kontrolliert werden, oder...
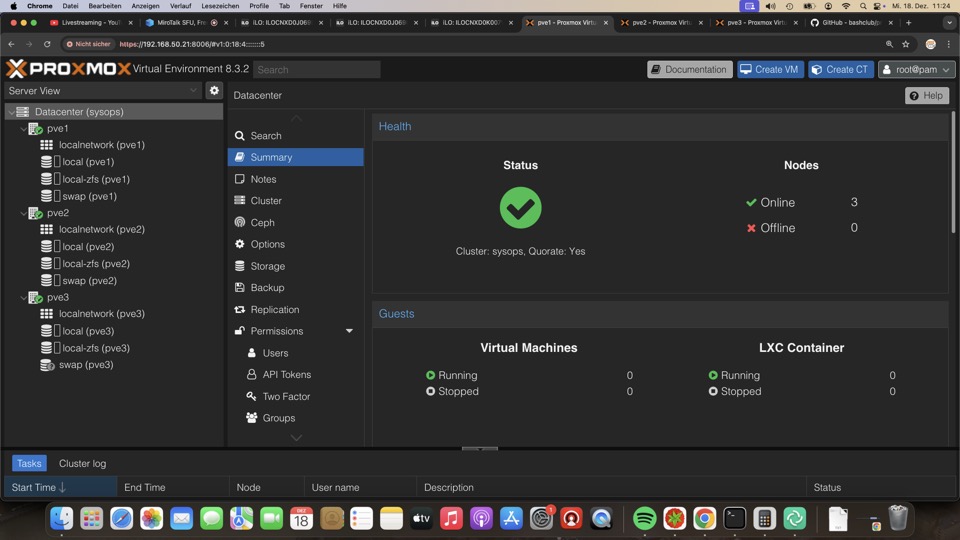
S.M.A.R.T Kontrolle via GUI aus Erfahrung oft noch ohne Fehler, während unser Check_MK Plugin schon Probleme erkennt!
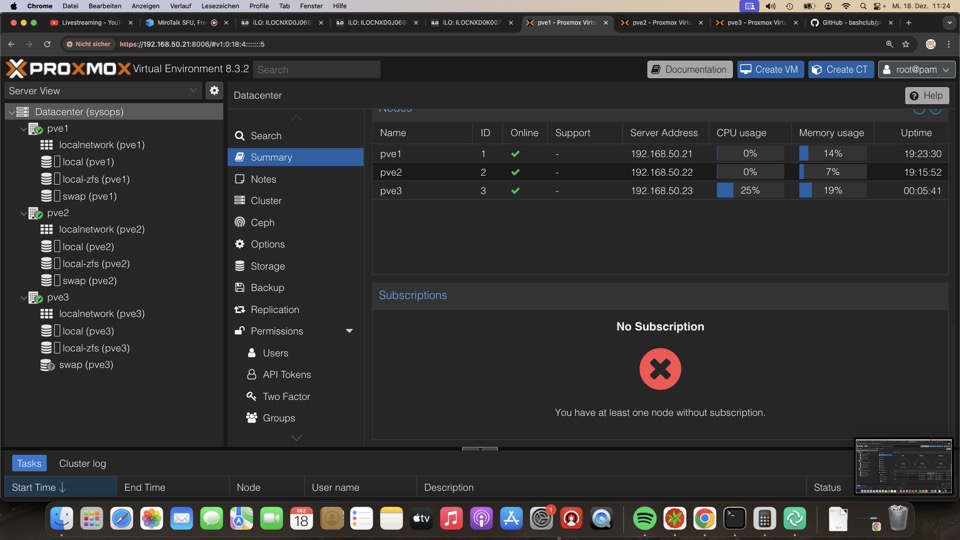
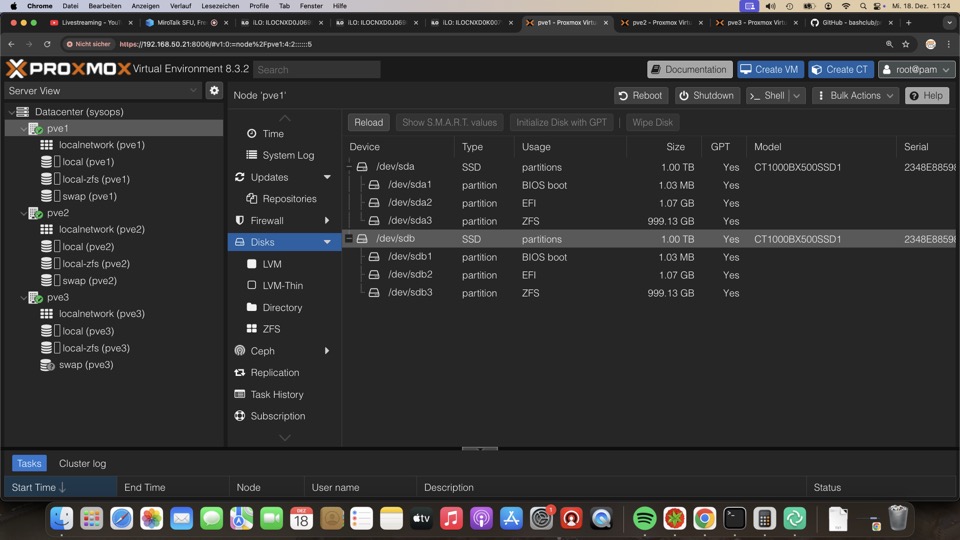
Mühselige Kontrolle aller Systeme via GUI pro Host ist nicht praxistauglich!!!
Musterinstallation Linux / Windows als VM
Der Postinstaller stellt die aktuelle Windows Treiber ISO in der Stabilen Version bereit, der Proxmox Installer das zweite Laufwerk dafür
i440FX als Maschinentyp und Bios sind inzwischen eher zu vermeiden, schliesslich soll der Kram lange laufen.
Funfact, i440FX war für die Pro Version des ersten Pentiums, dung ding da ding!
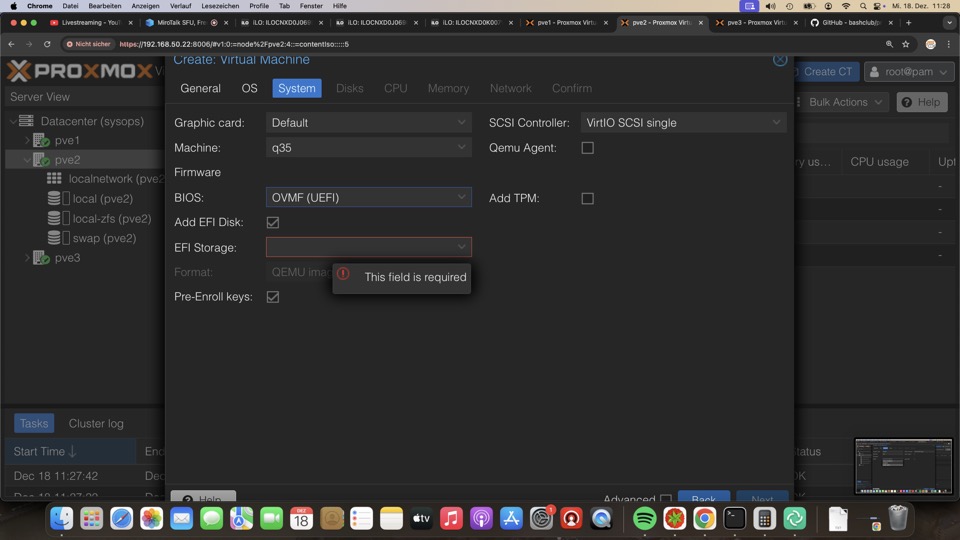
Proxmox VE legt im ZFS oder Ceph ebenfalls einen Blockstorage für TPM und EFI Einstellungen an, diese werden Raw ohne Dateisystem geschrieben und haben nichts mit der EFI-Boot-Partition zu tun.
Die native Bildschirmauflösung des Systems wird in der VM beim Starten mit ESC eingestellt.
Der Virtio SCSI single Controller wird im Host als eigener Prozess und im Gast als eigener Controller pro Disk aktiviert
Der Qemu Agent sorgt für Shattenkopien, Freezing, Herunterfahren und mehr!
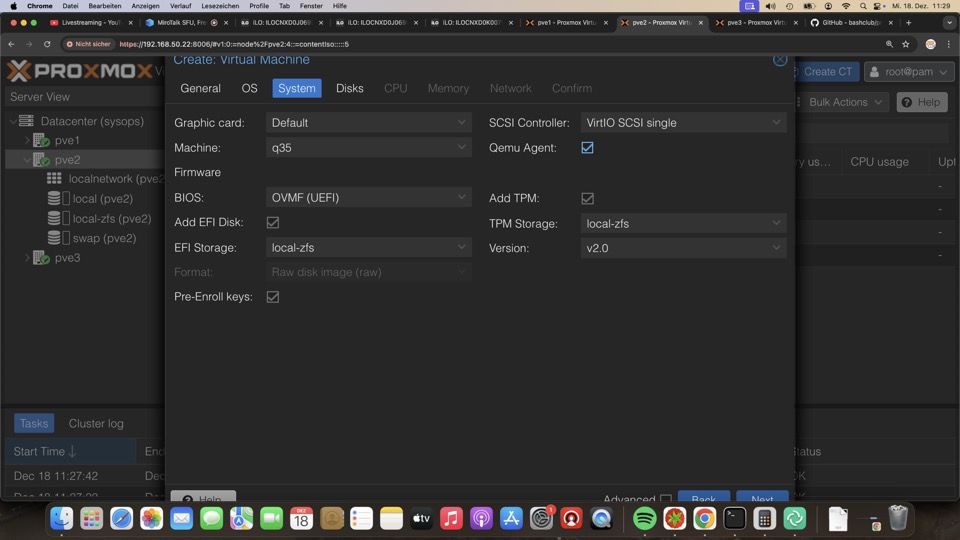
Die Kombination von Discard, SSD Emulation, wie auch IO thread gibt bessere Auslastung und Entlastung von gelöschten Daten an den Host

CPU Typ Host ist für identische Hardware in Clustern und Standalone zu bevorzugen, da hier alle Prozessorfunktionen genutzt werden
Ballooning spart RAM beim einschalten und macht noch mehr. Treiber unter Windows sind notwendig
Virtio Netzwerkkarten brauchen unter Windows eigene Treiber, performen aber bis 100Gbit
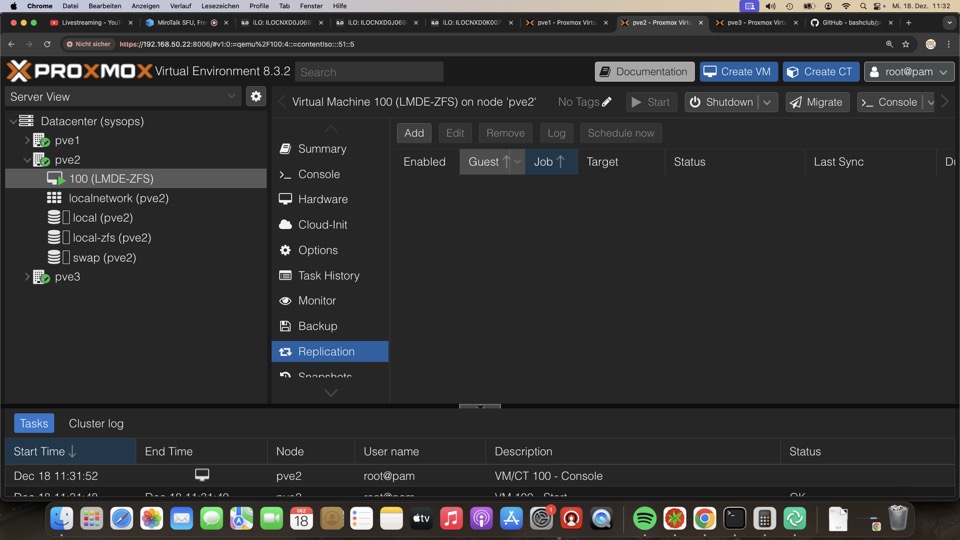
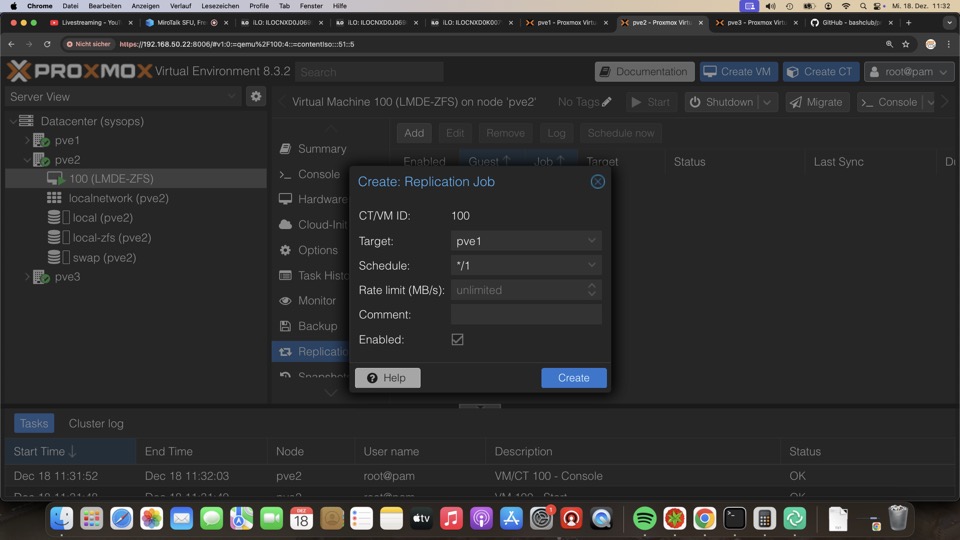
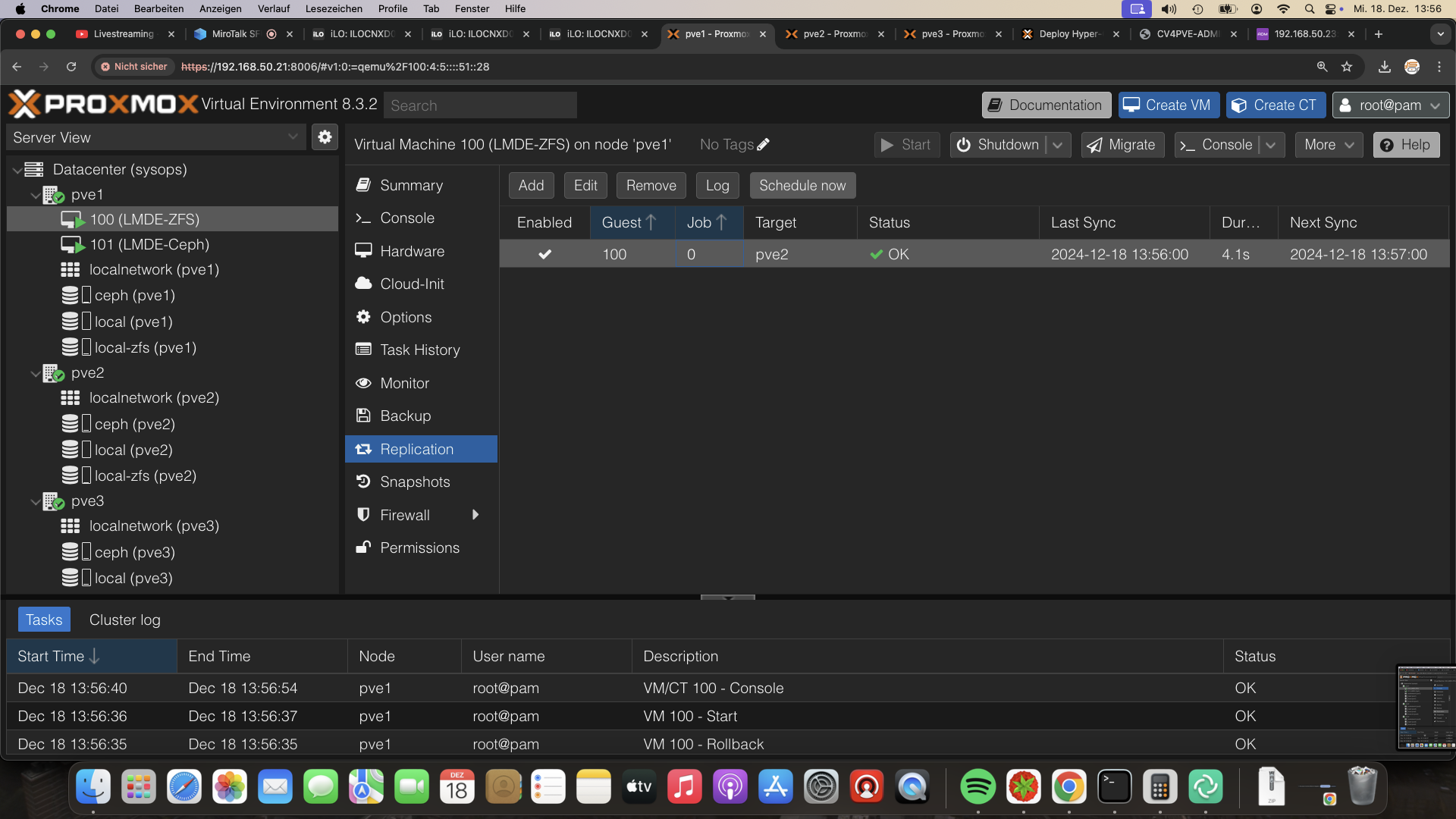
Die eingebaute Replikation ist erst mal gut genug, auch wenn es mit Zsync besser geht. Dafür hat man, leider nur in der VM hier, Kontrolle über den Erfolg. Löscht man den Job, löscht sich das Replikat
Das Zeitfenster ist mit 15-60 Minuten optimal, mit einer Minute perfekt. Jedoch sollte man nicht jede VM auf eine Minute stellen. da hier das ZFS Auflisten zu Timeouts führt.
Autosnapshotting ist nicht vorgesehen, leider!
Linux unterstützt alle Virtio Laufwerke und Netzwerkkarten nativ
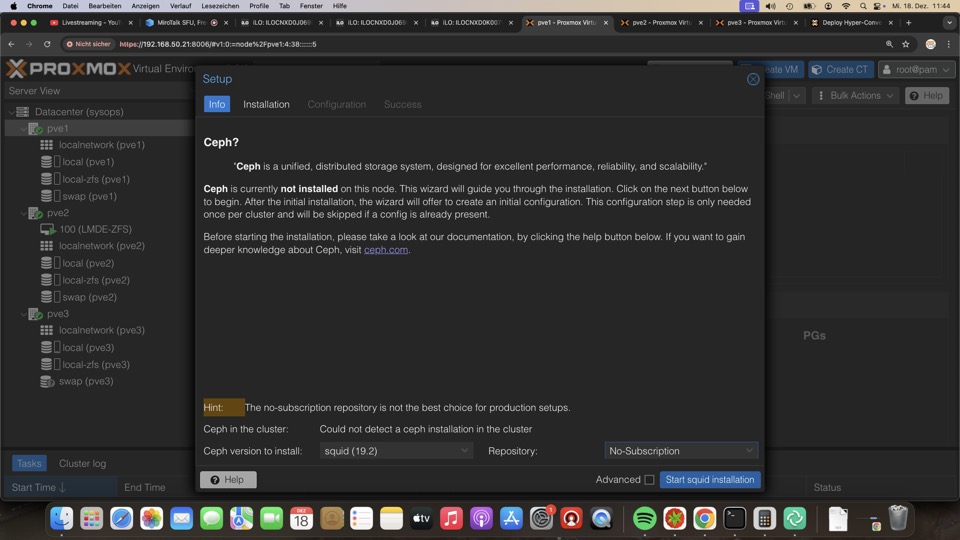
Installation Ceph
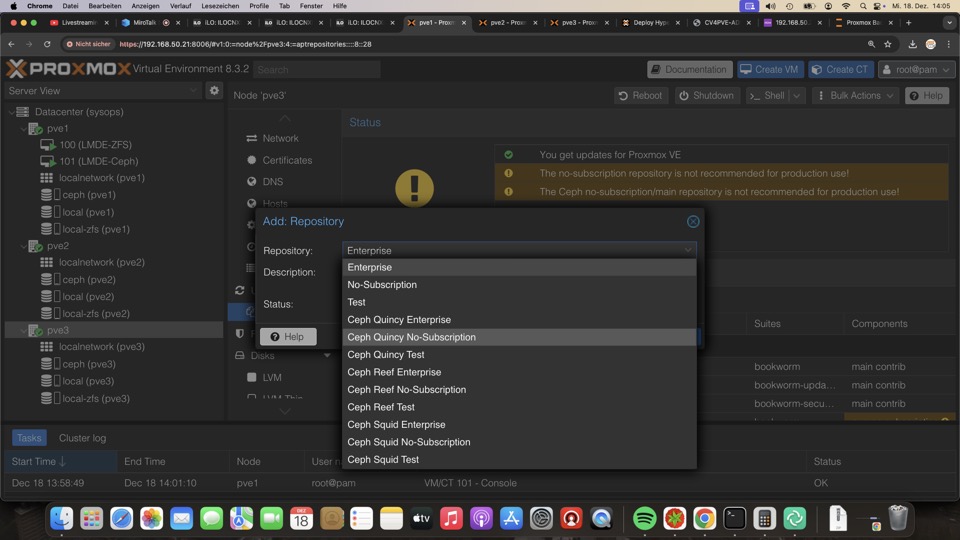
Der Assistent installiert die notwendigen Repositories. Wir empfehlen hier wenigstens die Community Subscription zu nehmen, da ein defekter Ceph-Cluster ein Single-Point-of-Failure ist

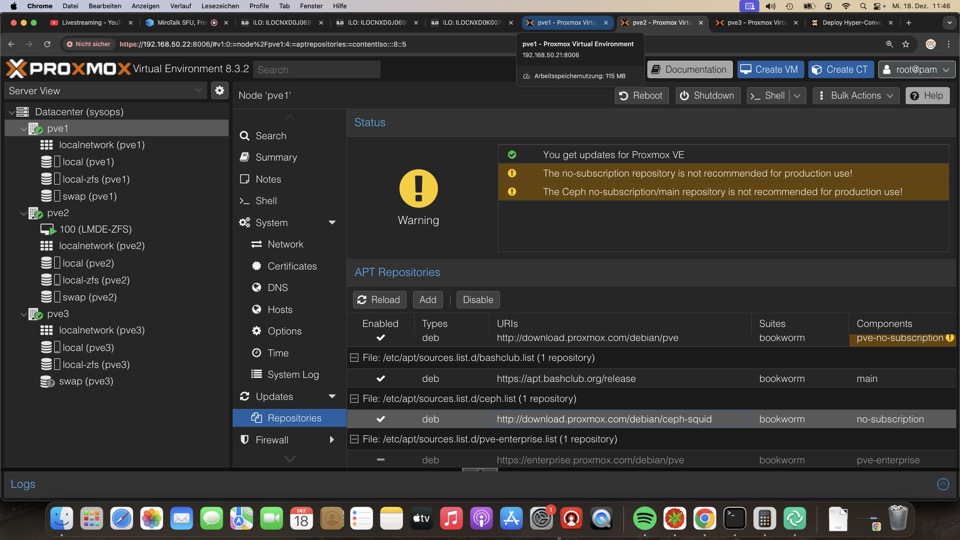
Die Auswahl der Netze für Cluster, Ceph, Rendundanz und weitere Segmentierungen sollten von einem Erfahrenen Fachmann vorgenommen werden. Wir empfehlen hier Inett aus Saarbrücken
Im aktuellen Setup können wir zum Testen nur das LAN nehmen, das wir ausdrücklich so nicht empfohlen!!!
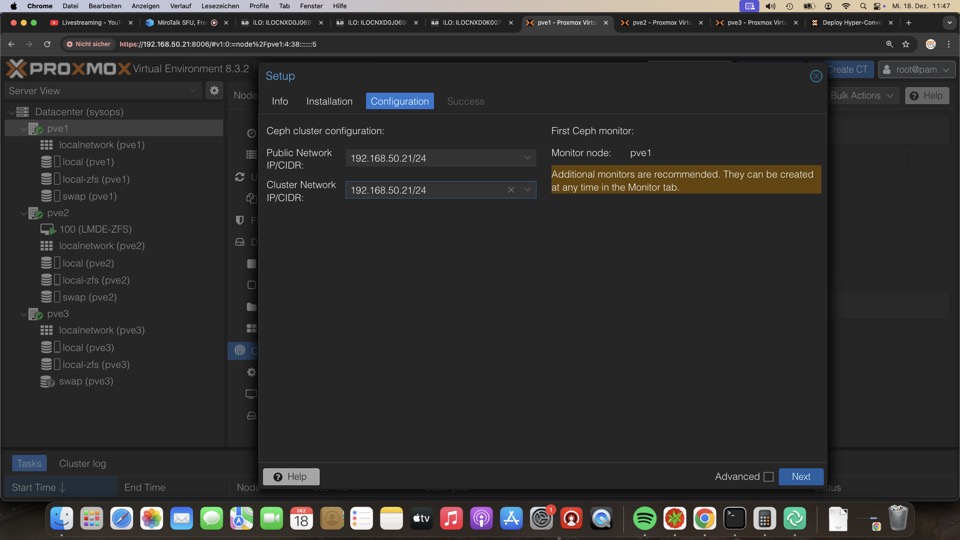
Die Installation muss auf allen Clustermitgliedern wiederholt werden, wobei die Konfiguration via PVE Cluster übernommen wird
Jeder Host bekommt mindestens eine SSD als sog. OSD, ab drei Stück haben wir einen funktionierenden Ceph Cluster, ohne extra Sicherheit. Als Nettonutzplatz erhalten wir 1/3 der SSDs, in dem Fall knapp 1TB
Auf keinen Fall dafür in irgendeiner Weise Hardware Raid Controller nutzen!!!
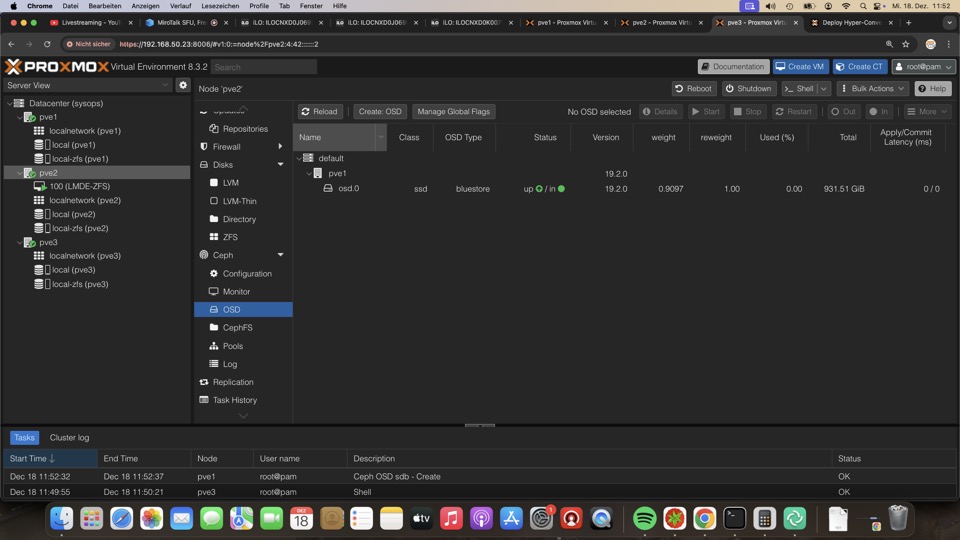
Ceph OSD Einrichtung
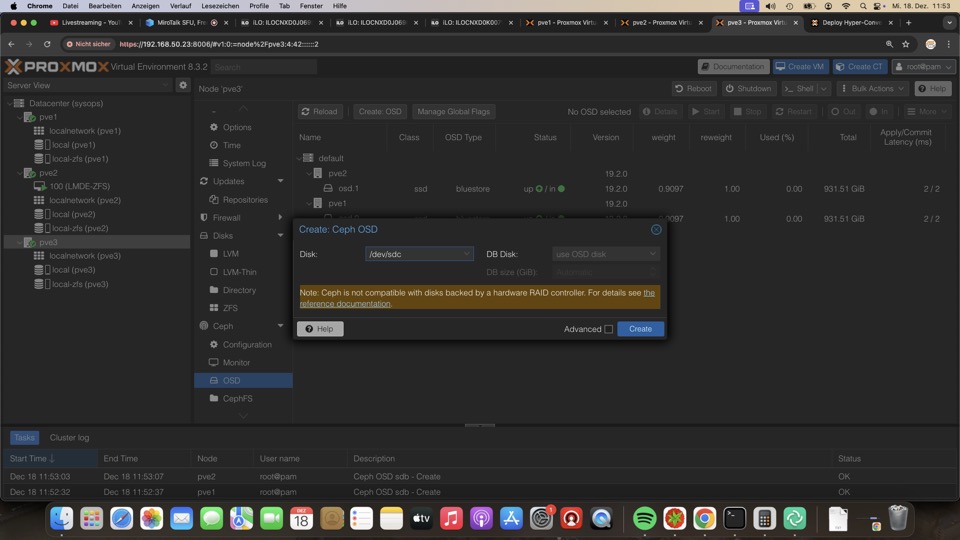

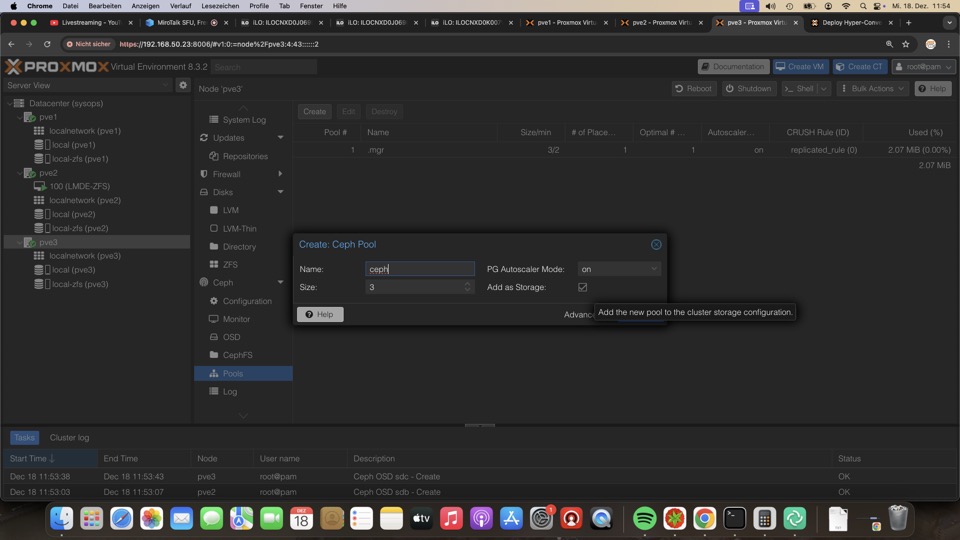
Ceph Pool anlegen
Der Pool verbindet die OSDs zum Verbund, die Rolle Monitor und Manager können auf mehrere Nodes verteilt werden, sonst wäre der Reboot des ersten Nodes nicht ohne Schaden möglich!
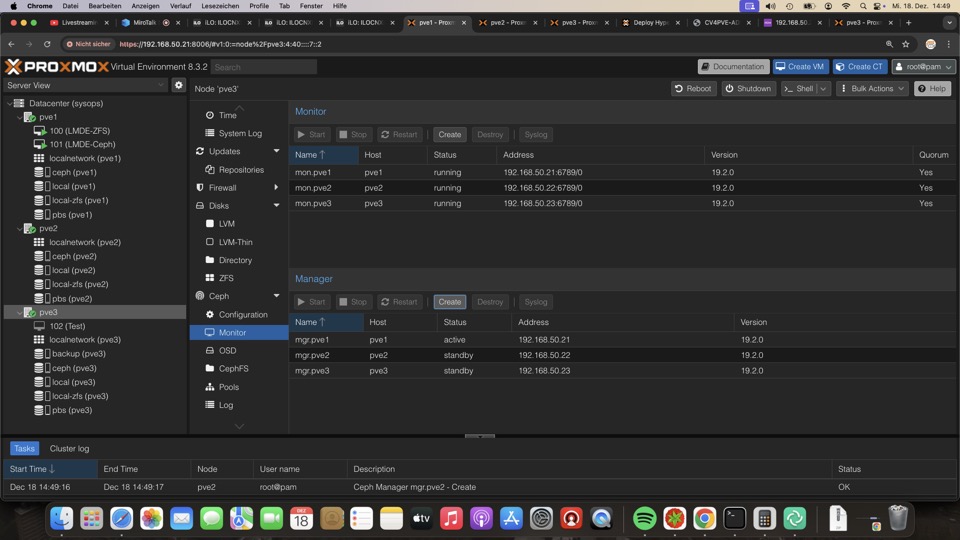
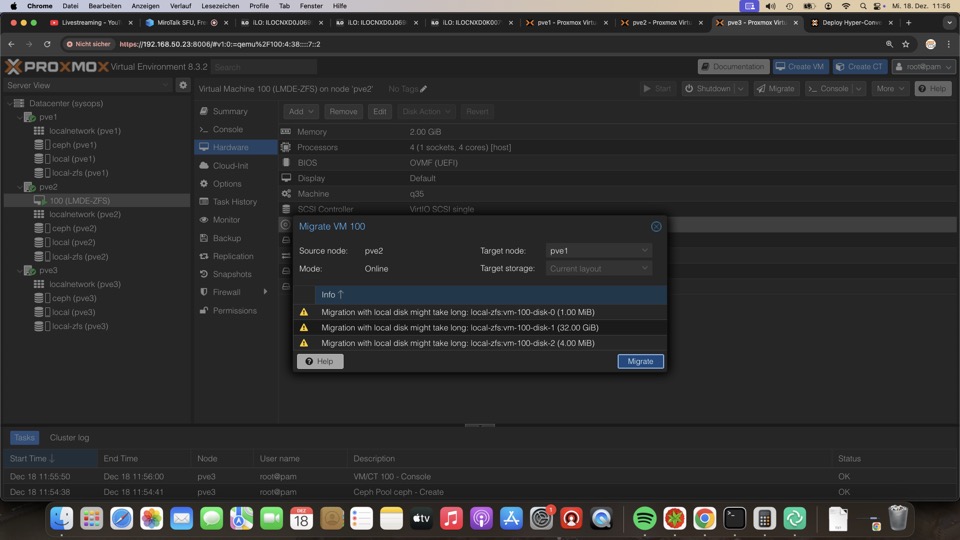
VM Migration Node zu Node
Die Übertragung einer laufenden VM oder eines LXC mit Shutdown ist bei ZFS und Ceph möglich.
Wärend bei CEPH der Speicher verteilt ist, muss bei ZFS RAM und Disk nocheinmalübertragen werden.
Bei vorheriger ZFS Replikation ist das meiste der VM schon auf dem Ziel und kann inkrementell ergänzr werden.
Gab es vorher keine Replikation muss die komplette VM übertragen werden.
Das Mittel der Übertragung ist je nach Zustand der VM via KVM oder ZFS möglich.
Ersteres würde zum Verlust von Snapshots führen!
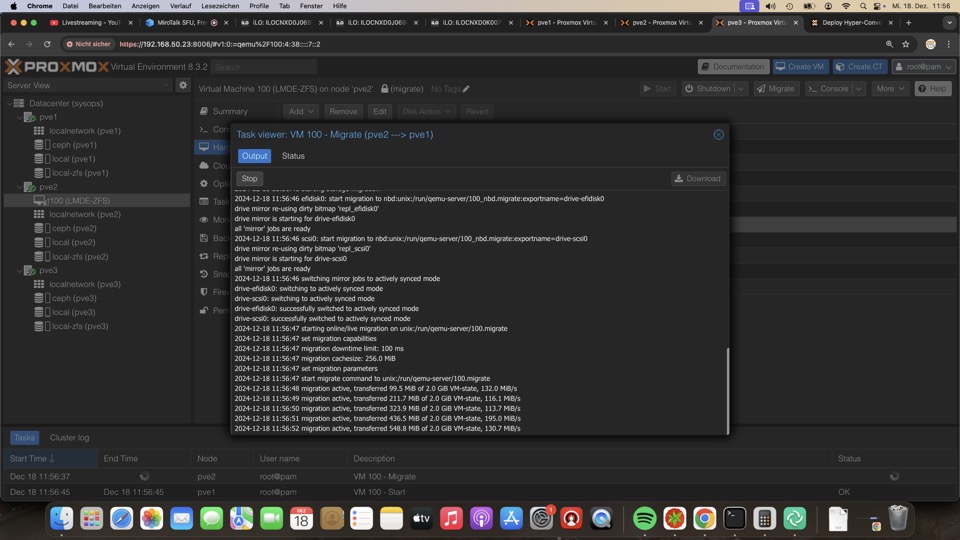
Klonen zwischen ZFS und Ceph
Proxmox kann mit Bordmitteln die meisten Formate konvertieren.
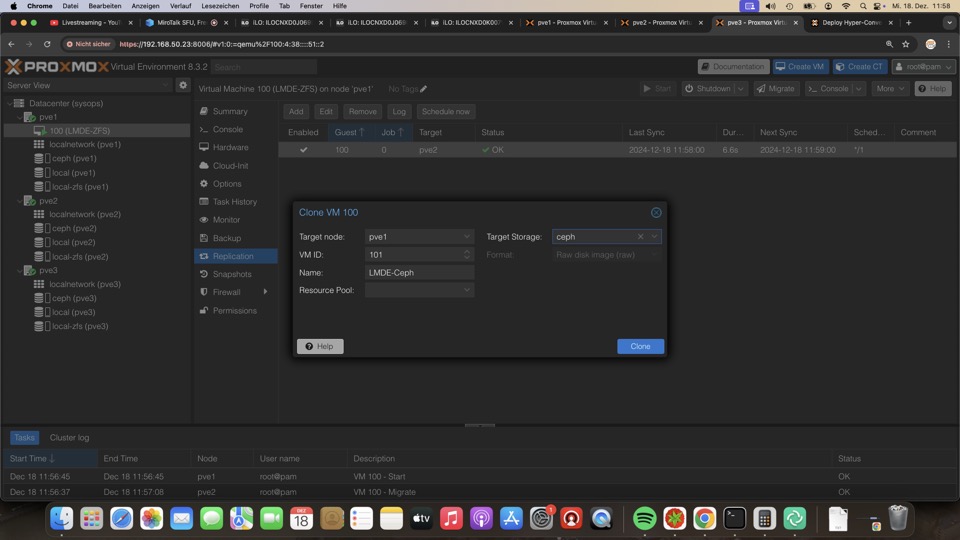
Qemu-Guest-Agent Installation
Dieses Paket für geordnetes Herunterfahren immer mitinstallieren und starten!
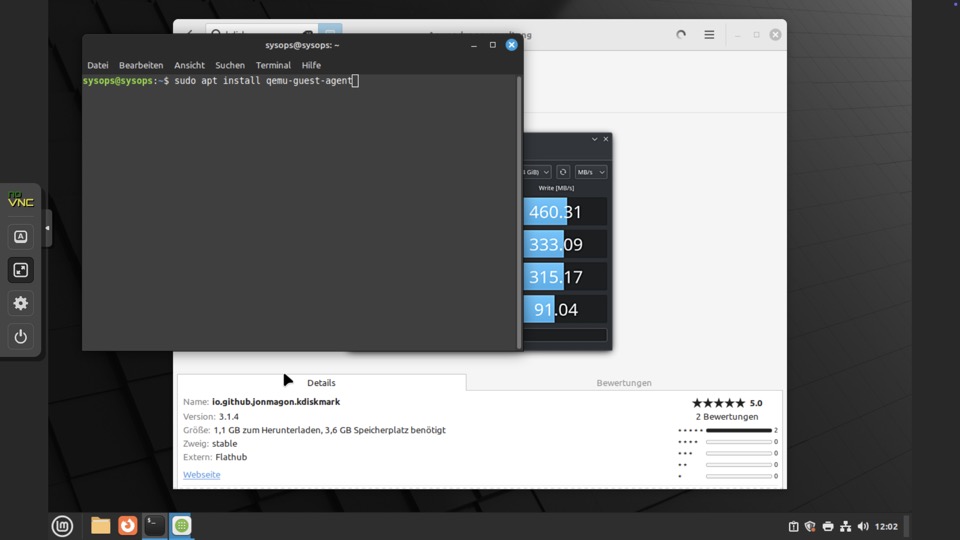
IO Leistung der Systeme bei diesen Voraussetzungen
ZFS ist dreimal schneller und auf zwei Kisten verfügbar
Wir gehen von der sechsfachen benötigten Leistung aus um Leistungsmässig an ZFS Raid1 zu kommen
Login für Root und PVE User mit zwei Faktor absichern!
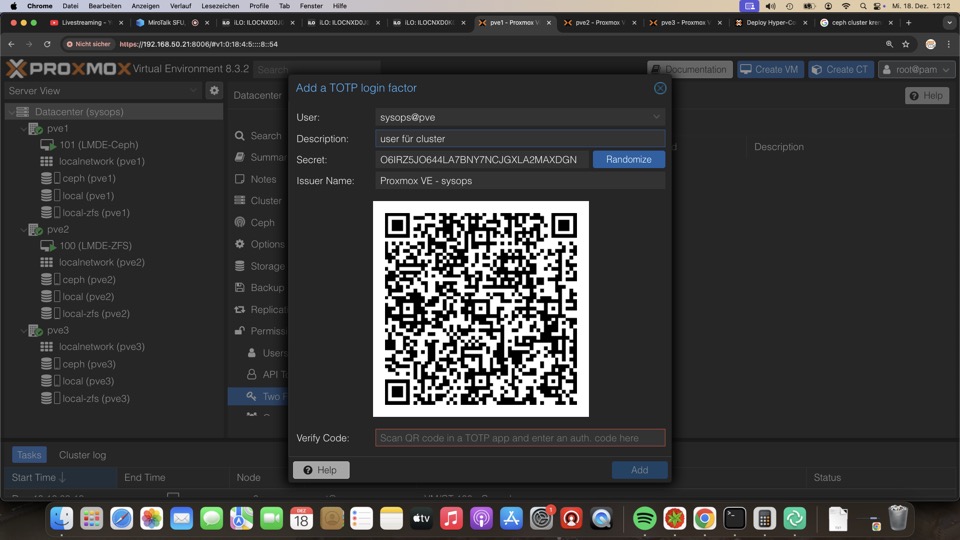
Weitere User benötigen entsprechende Rechte!
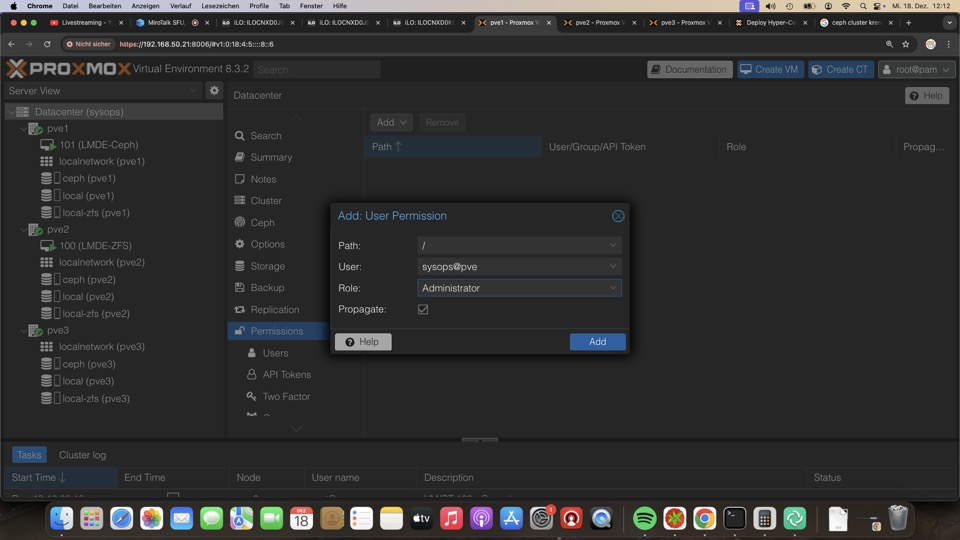
Login Realm ist Linux User oder Proxmox Userbasis
Es können in der GUI keine weiteren Linux/PAM User angelegt werden, jedoch GUI aktiviert
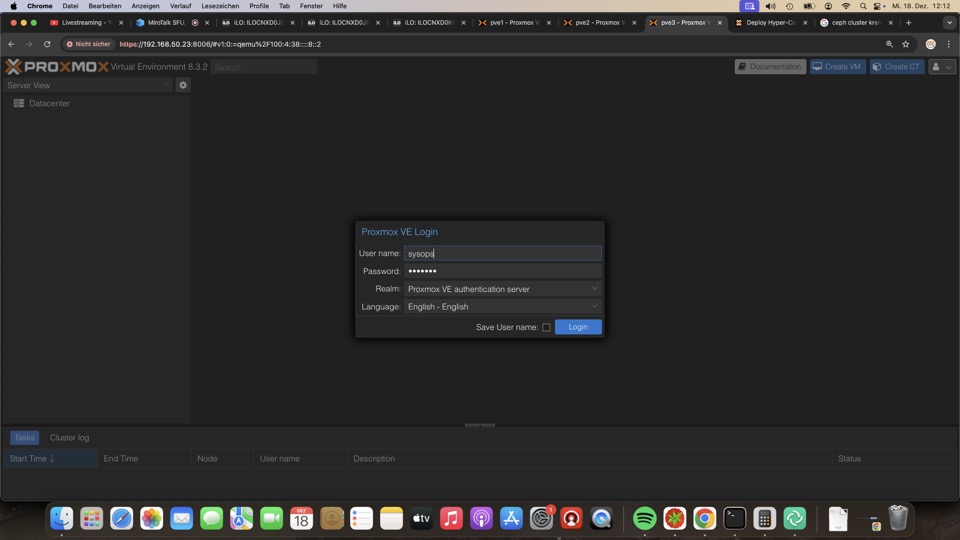
SSH Daemon gegen Passwort Login absichern
Eigene virtuelle Switche für VMs trennen das Verwaltungsnetz ab
Wenn die Resourcen vorhanden sind, dringend dafür sorgen daß Anwender und Gast VMs keinen Zugriff auf Proxmox VE, Switche und Firewalls haben
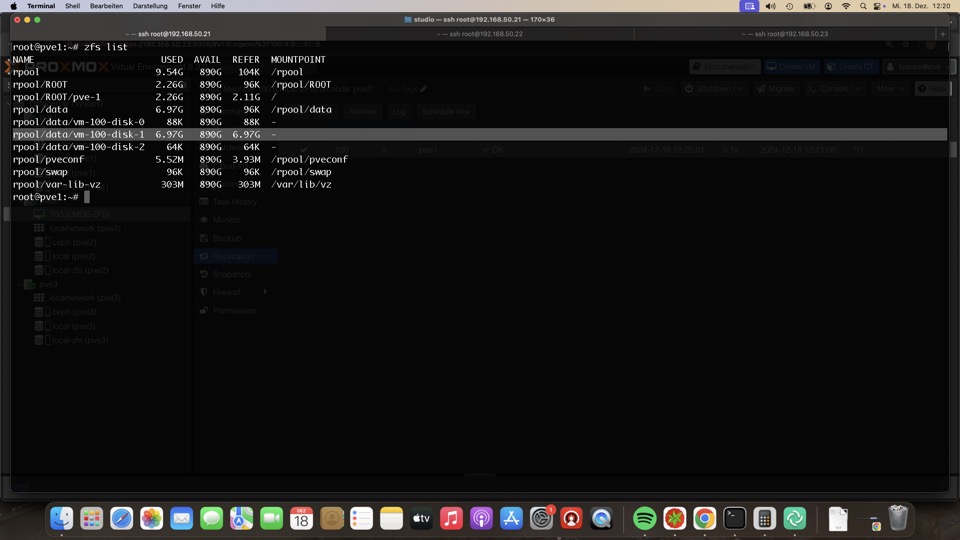
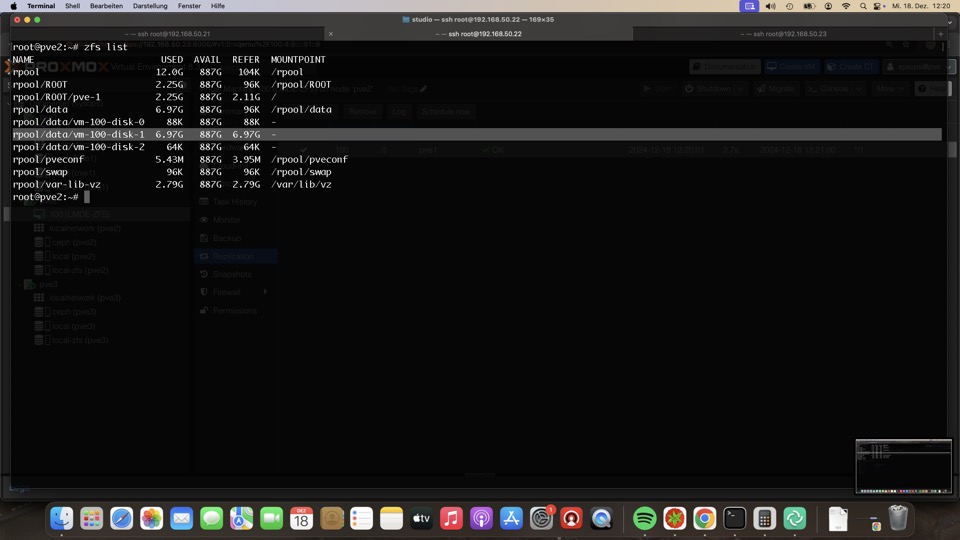
Ein Blick auf ZFS klärt nicht welche VM auf welchem Host aktiv ist!
PVE1 und zwei sind auf den ersten Blick nicht zu unterscheiden, auch nicht mit Snapshotauflistung
Unser erweitertes Ablagekonzept macht die Funktion von abgelegten Daten viel deutlicher. Mehr auf cloudistboese.de
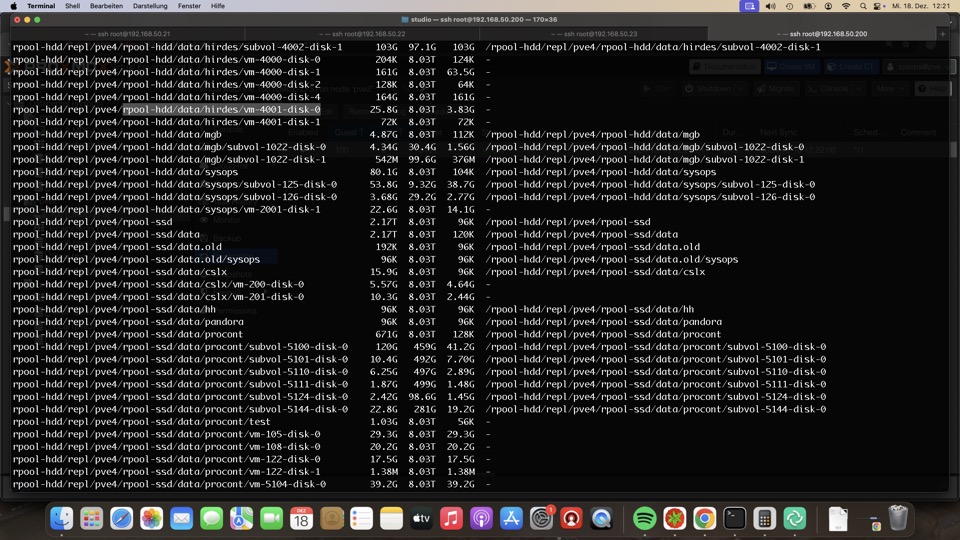
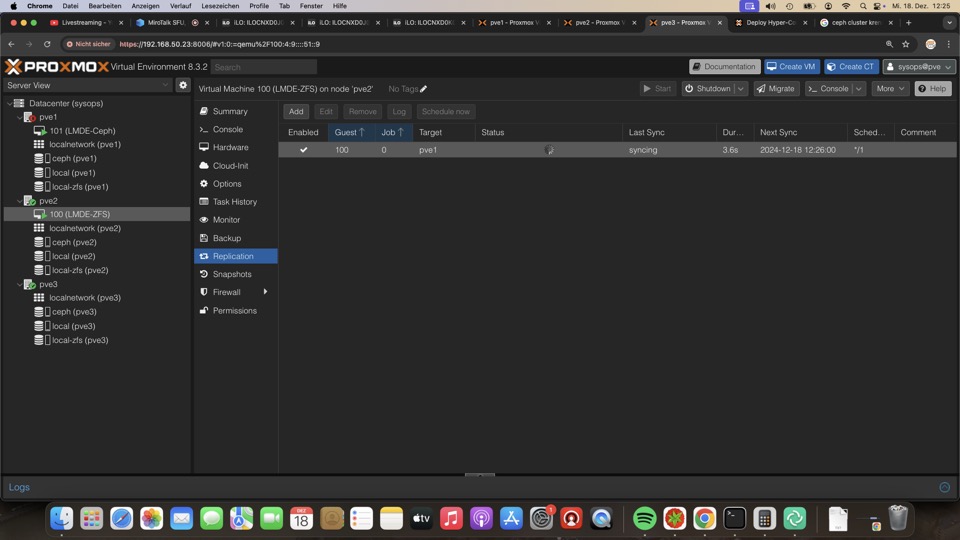
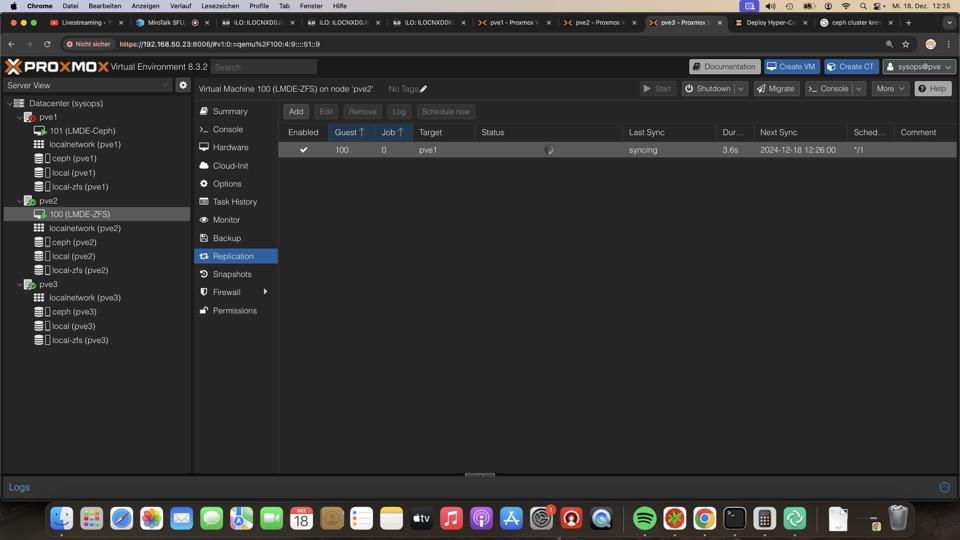
Prüfung der Replikationen muss mühselig pro VM vorgenommen werden
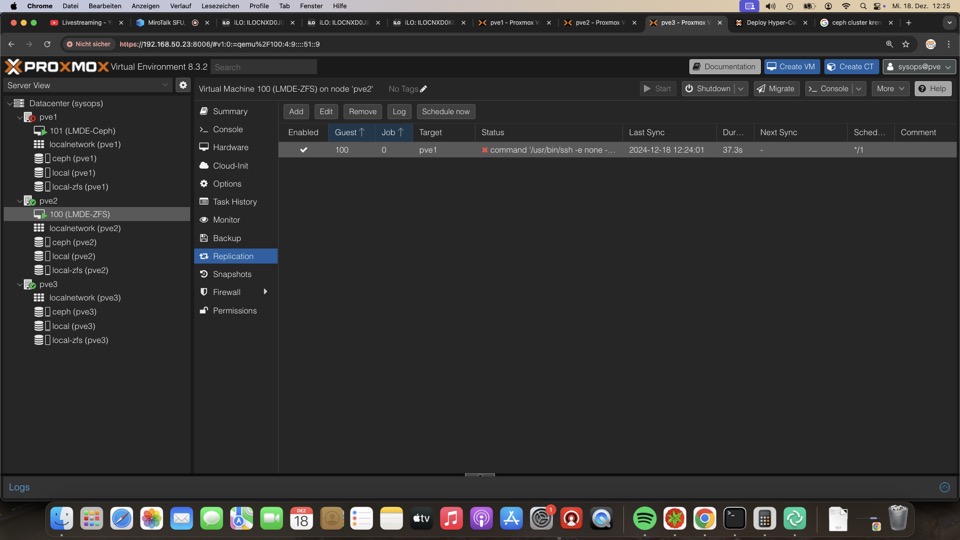
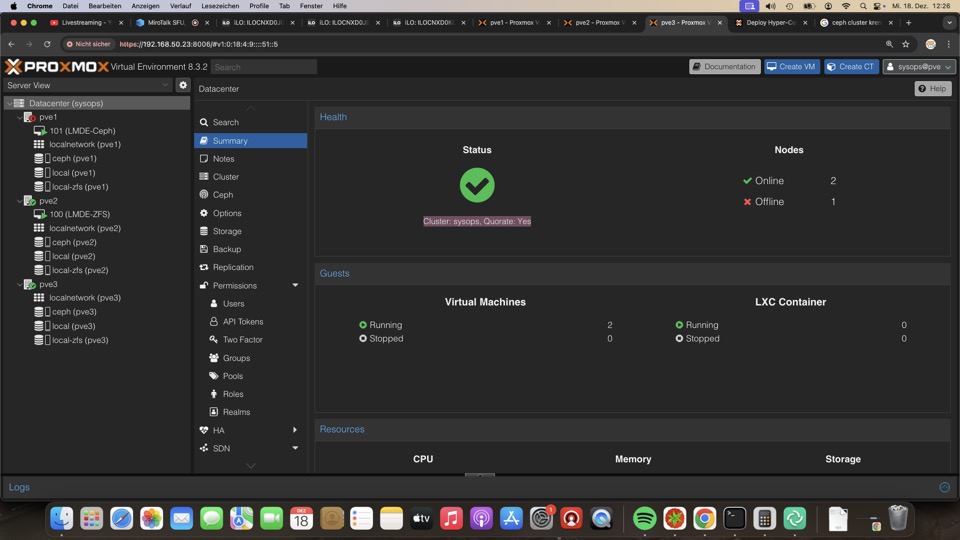
Leider zeigt das PVE Dashboard weder defekte Platten, noch Raids oder Replikationen in der Übersicht an. Hier wird später Check_MK oder CV4PVE für Übersicht sorgen müssen!
Postinstaller sichert komplette Konfiguration und dessen Historie mit Rsync und ZFS-Auto-Snapshot
Üblicherweise nutzen wir zfs-auto-snapshot gnadenlos auf alle Datasets und Volumes
Die Proxmox Konfiguration liegt jedoch in einer Datenbank und wird nach /etc/pve gemountet
Diesen Ordner sichern wir regelmässig nach /rpool/pveconf und bauen mit Autosnapshots eine Historie
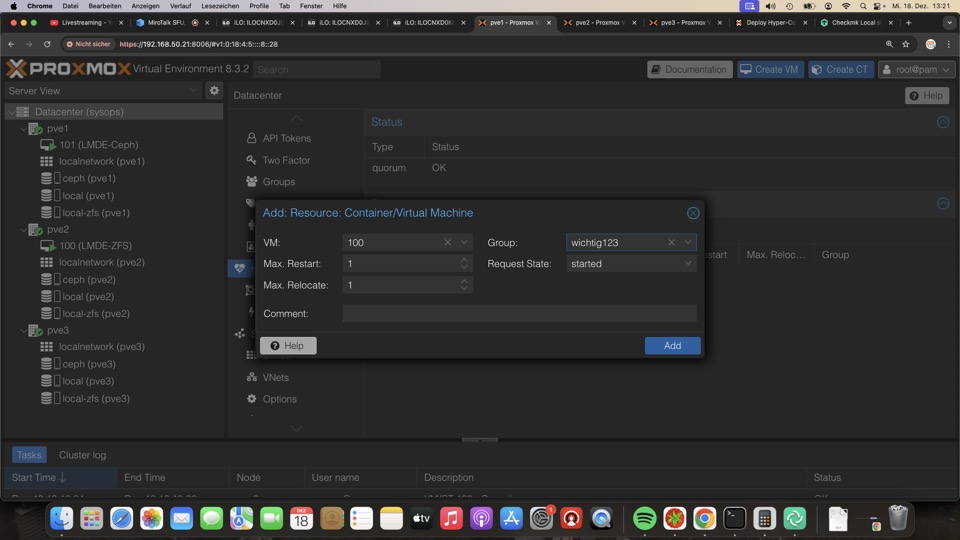
Hochverfügbarkeit einer VM / HA
Die HA Engine sorgt dafür daß VMs / LXC bei Ausfall eines Hosts auf einem anderen Host gestartet werden.
Der Übergang dauert mindestens zwei Minuten, wobei nur bei SAN oder CEPH kein Datenverlust entsteht
Bei ZFS verliert man dier die Replikationslücke!
Daher eignet sie sich am besten für Firewalls und Telefonanlagen
Die HA Gruppe definiert die gewünschte Ausführungspriorität, wobei höher mehr Prio hat
Prio 1 ist am niedrigsten

Die VMs werden den Gruppen zugewiesen und definieren unseren Wunschort und Zustand
Da PVE1 die höchste Priorität hatte wird VM 100 sofort dort hin migriert, die Replikation umgedreht

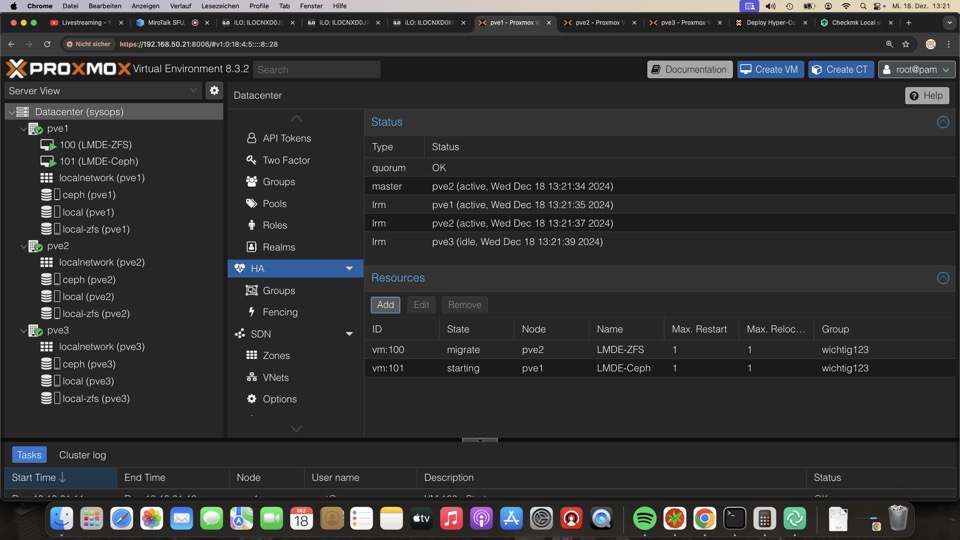
Wird ein Node neu gestartet, werden die VMs nicht automatisch umgezogen, sondern heruntergefahren.
Die Weboberfläche eines anderen Nodes muss dann geöffnet werden, die VMs vorher umgezogen werden!
Bei Ceph sollte es kein Problem sein einen Node neuzustarten, jedoch muss dafür der Cluster redundant gebaut sein. Sonst besser alle VMs stoppen
Manuelle und automatische Snapshots
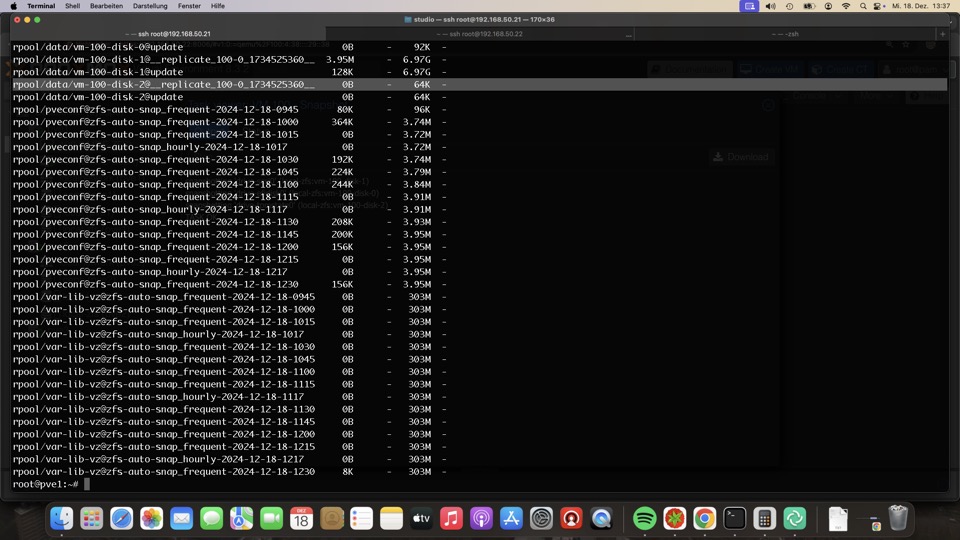
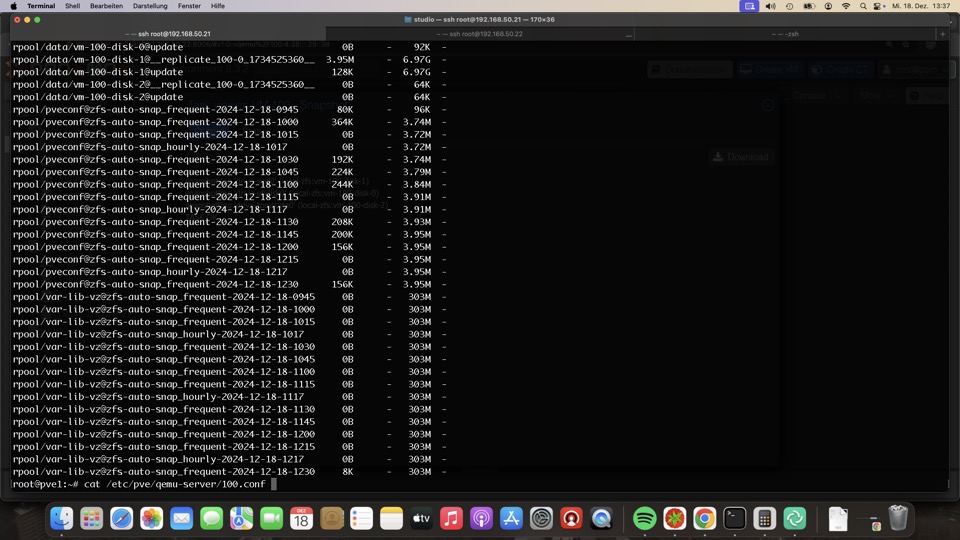
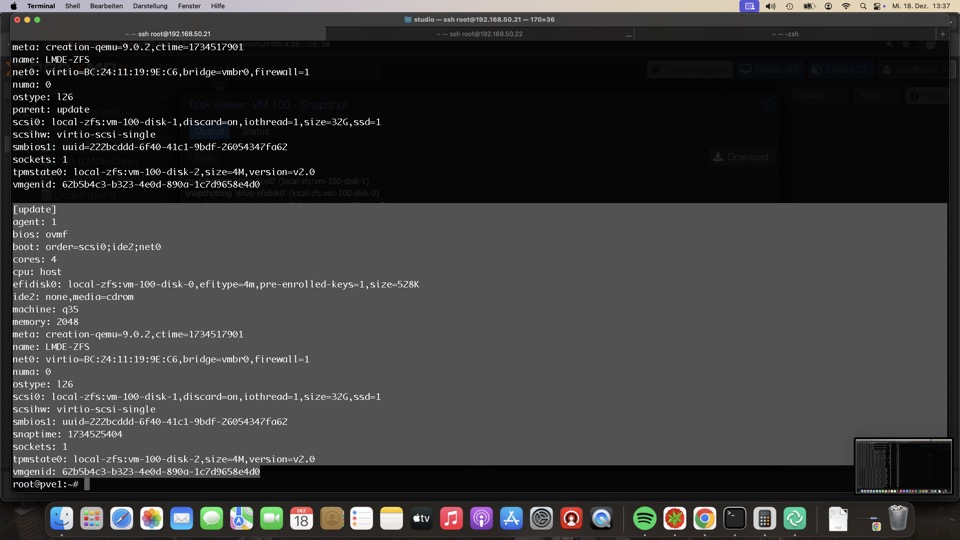
Manuelle Snapshots via GUI oder API werden mit dem passenden Datastoresnapshot ausgeführt, also ZFS, Ceph oder KVM
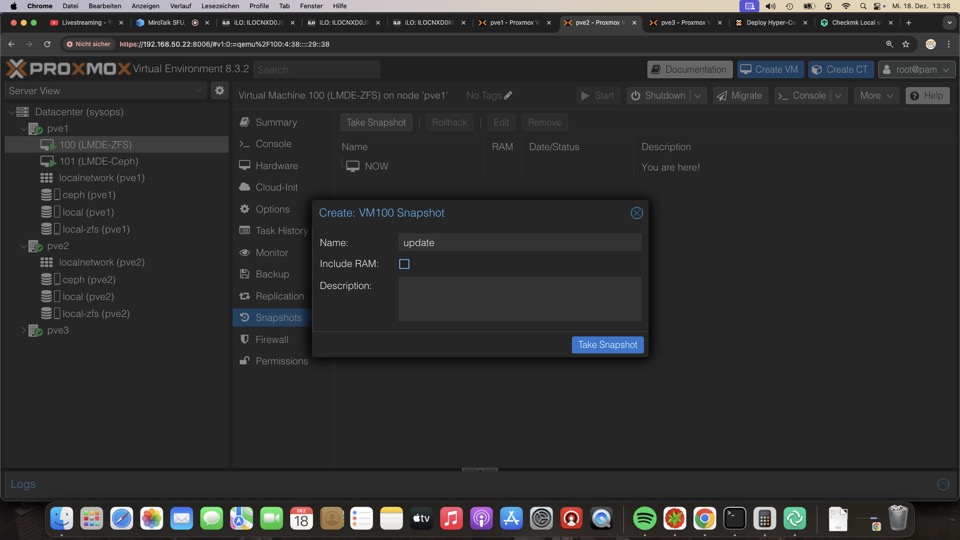
Bei ZFS werden diese Zustände mitrepliziert und die Konfigurationsdatei um diesen Zustand erweitert
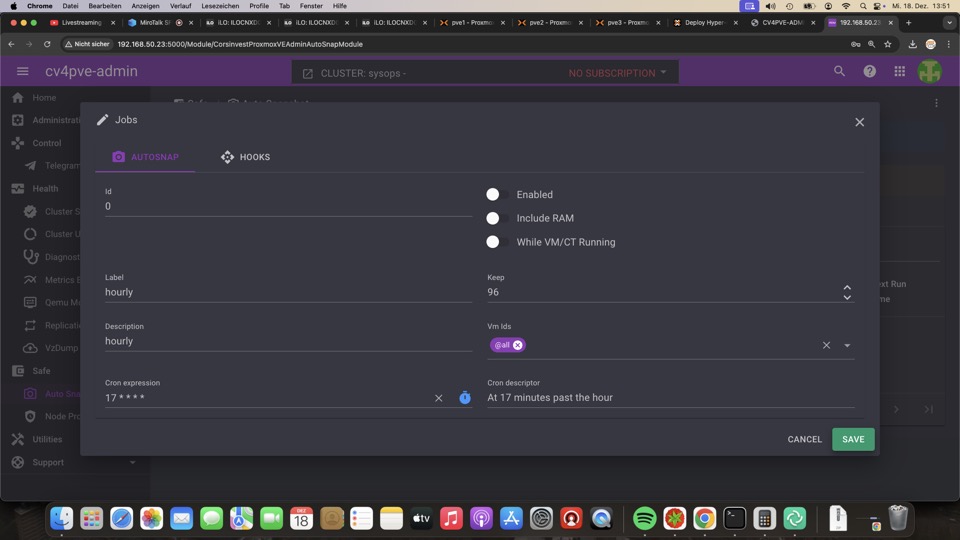
Automatische Snapshots Monitoring und Management mit CV4PVE-Admin
kann eine sinnvolle Alternative zu zfs-auto-snapshot sein und ergänzt wichtige, fehlende Einblicke der PVE GUI
Diese Anleitung scheint die sinnvollste, bitte auf eigene Maschine
Eigener PVE User plus gewünschte Rechte sind hier erklärt


Alle Replikationen mit Bordmitteln im Blick, nicht mehr jede VM muss aufgeklappt werden

Automatische Snapshots können hier definiert werden, jedoch muss das Teil auf laufen
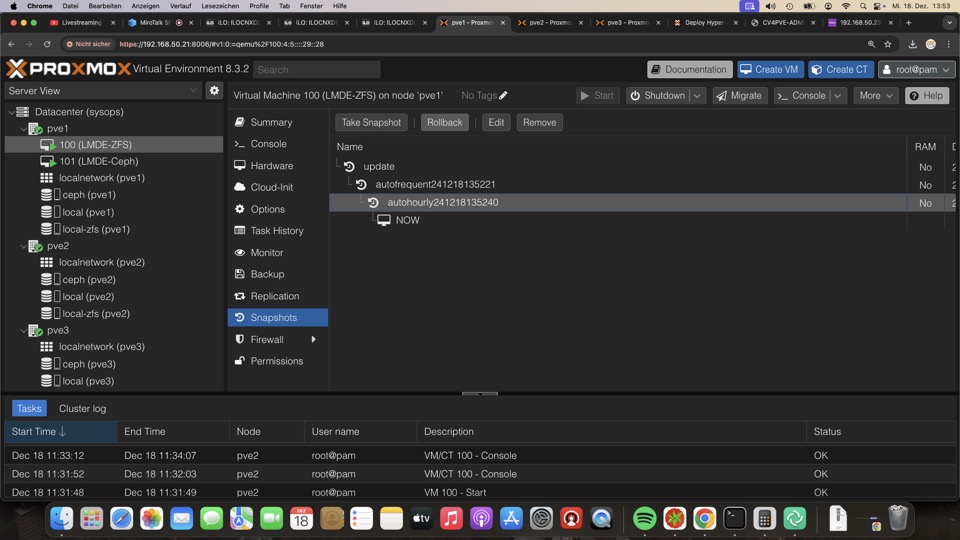
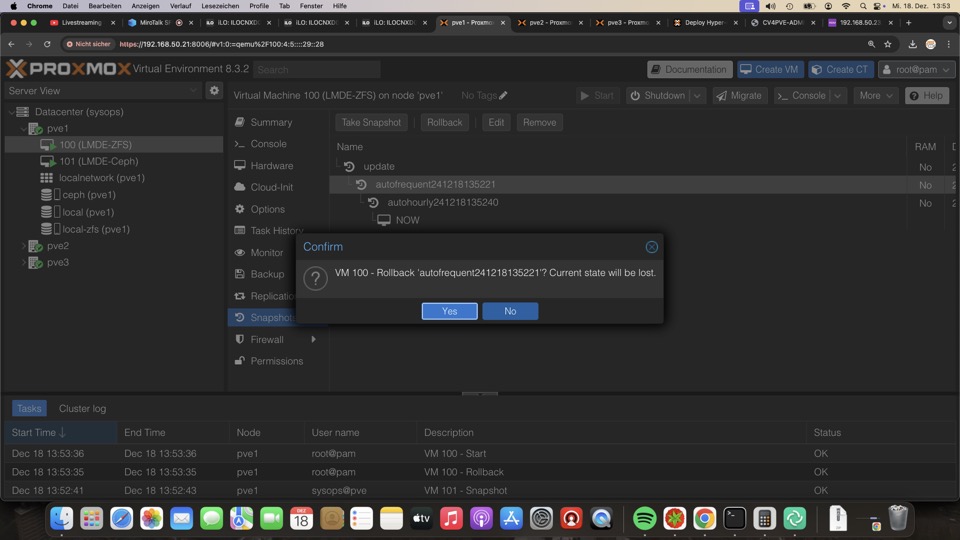
ZFS Snapshots können via GUI nur einzeln zurückgerollt werden, hier ist Ceph im Vorteil
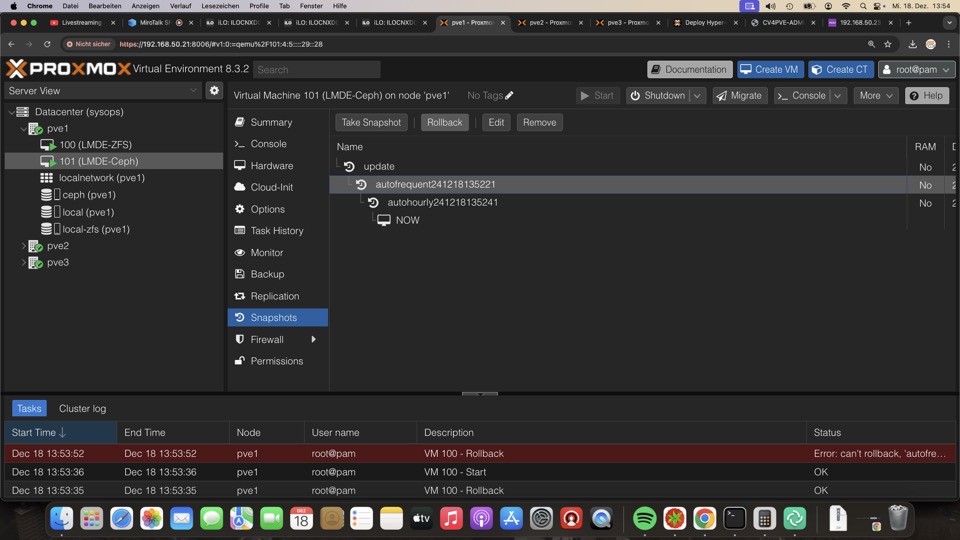
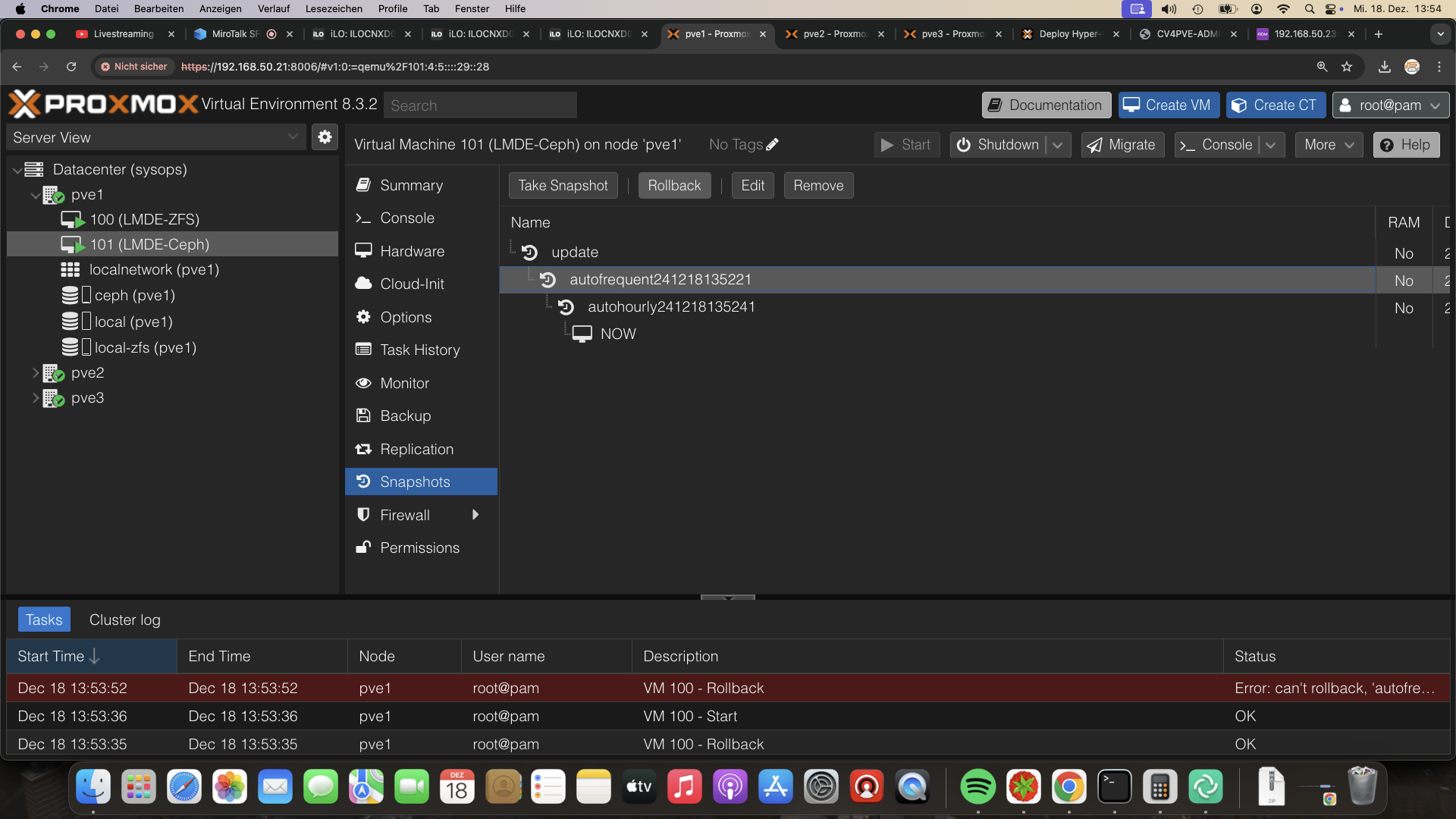
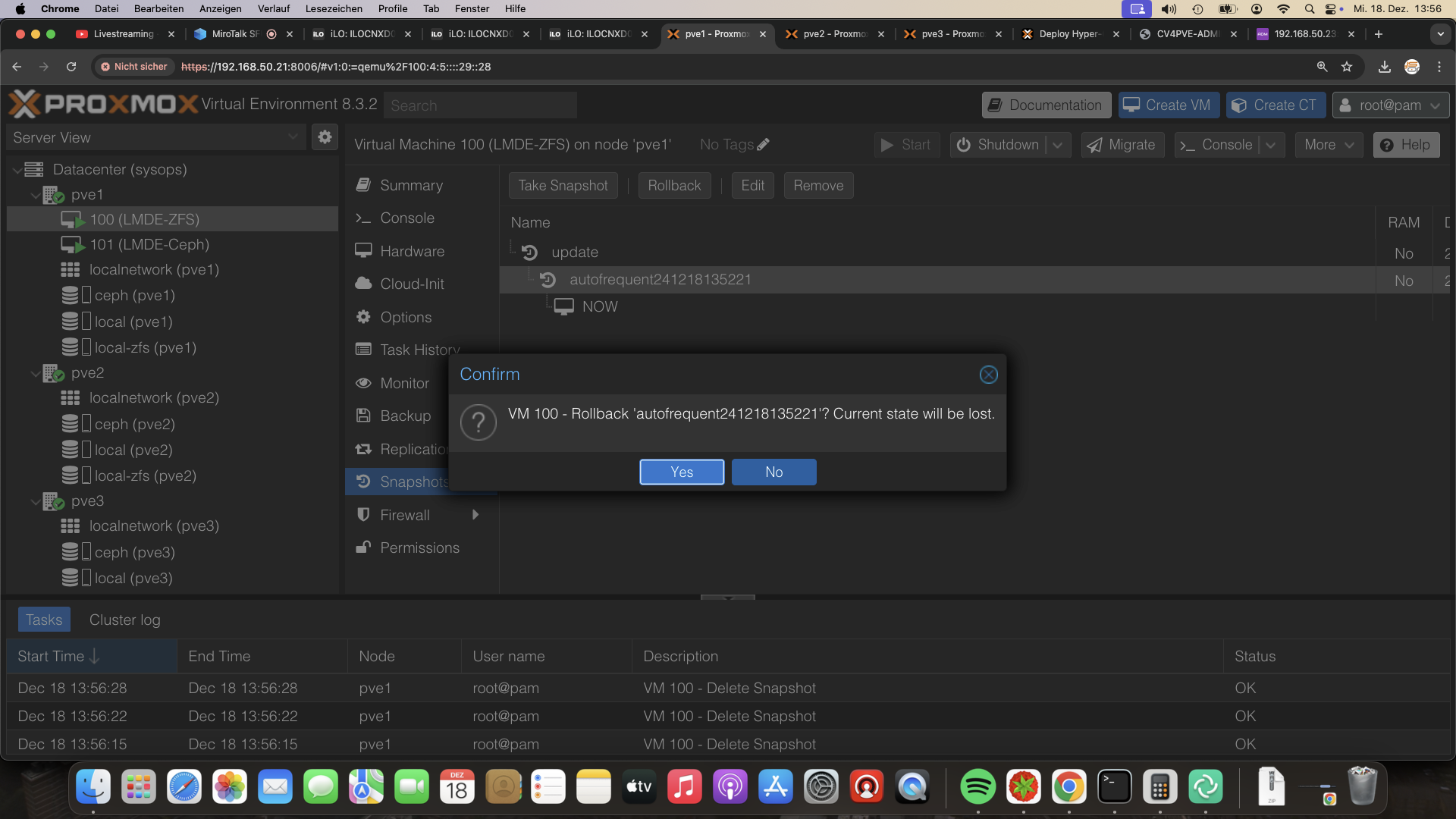
Replikation bricht nicht bei Rollback
Proxmox kann von HW Raid, ZFS, BTRFS, jedoch nicht von Ceph booten
Den Ceph Zustand kann man nicht mit Check_MK Bordmitteln prüfen
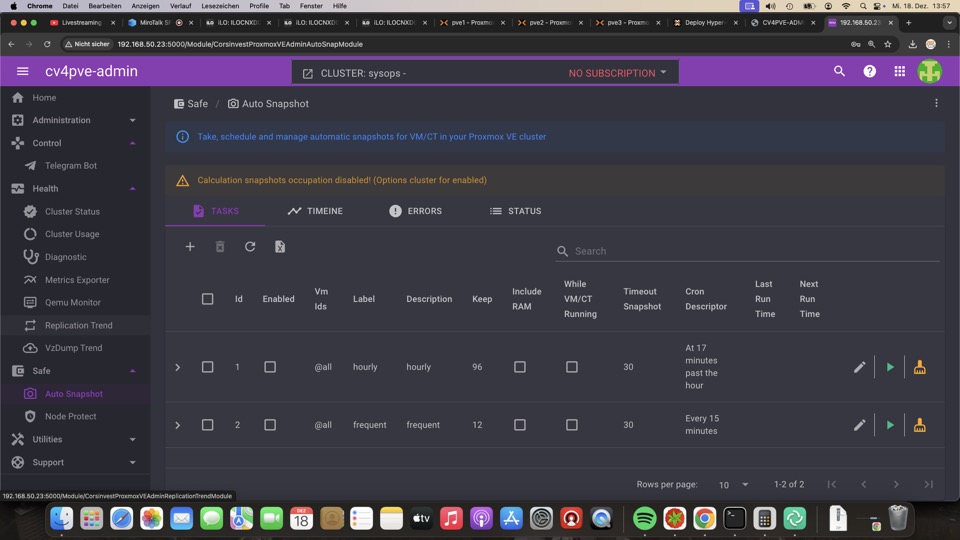
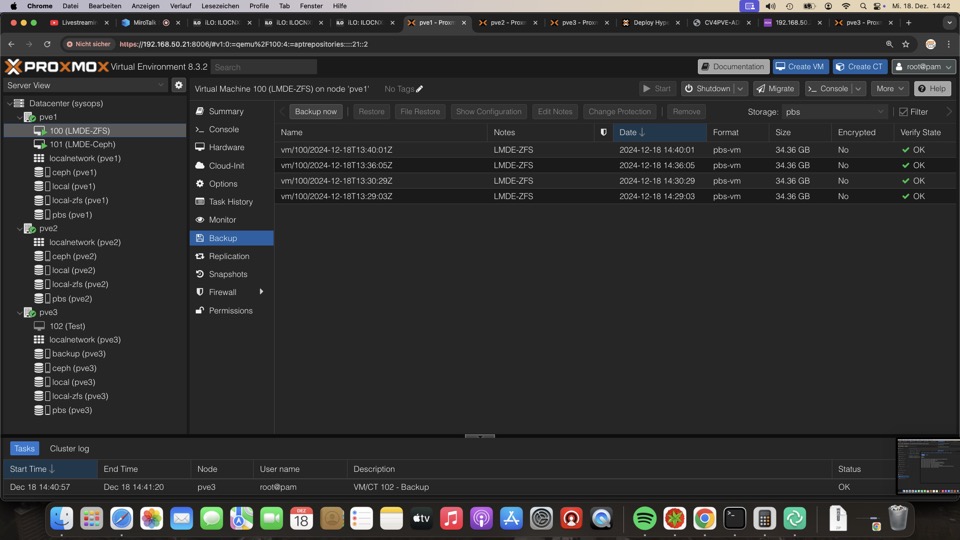
Datensicherung mit Proxmox Backup Server
Proxmox kann nativ erst mal nur eine Vollsicherung
Erst der Proxmox Backup Server bringt inkrementelle Backups und Management
Er kann auf einen bestehenden PVE installiert werden, alternativ auch als LXC
Die Repos fehlen jedoch hier
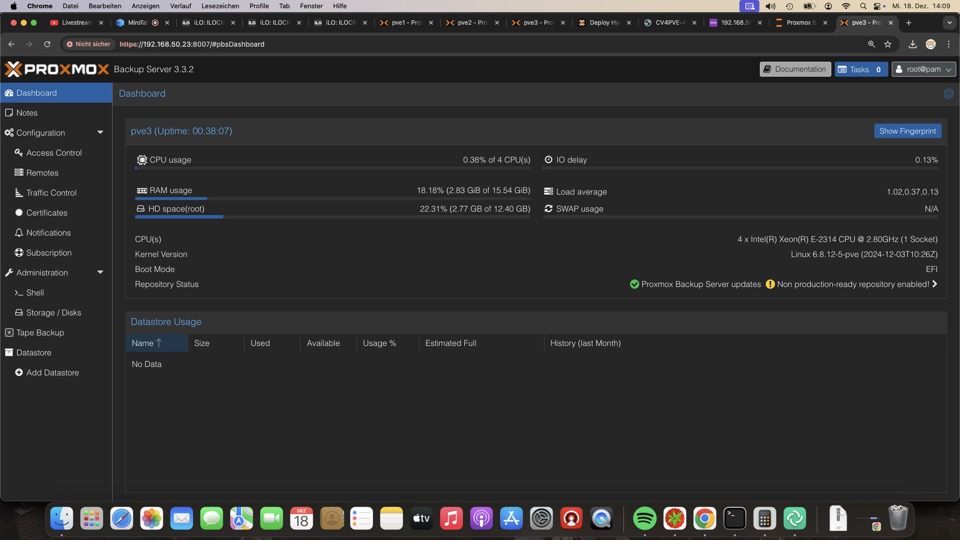
Hier wäre aktuell Bookworm
Zugriff in diesem Fall via PVE3 auf Port 8007 mit SSL
Das Dateisystem könnte mit BTRFS, ZFS oder Ext4 bereitgestellt werden, wobei Ext4 keine Snapshots zum Absichern von Backups beherrscht, dafür 100% Platzausnutzung
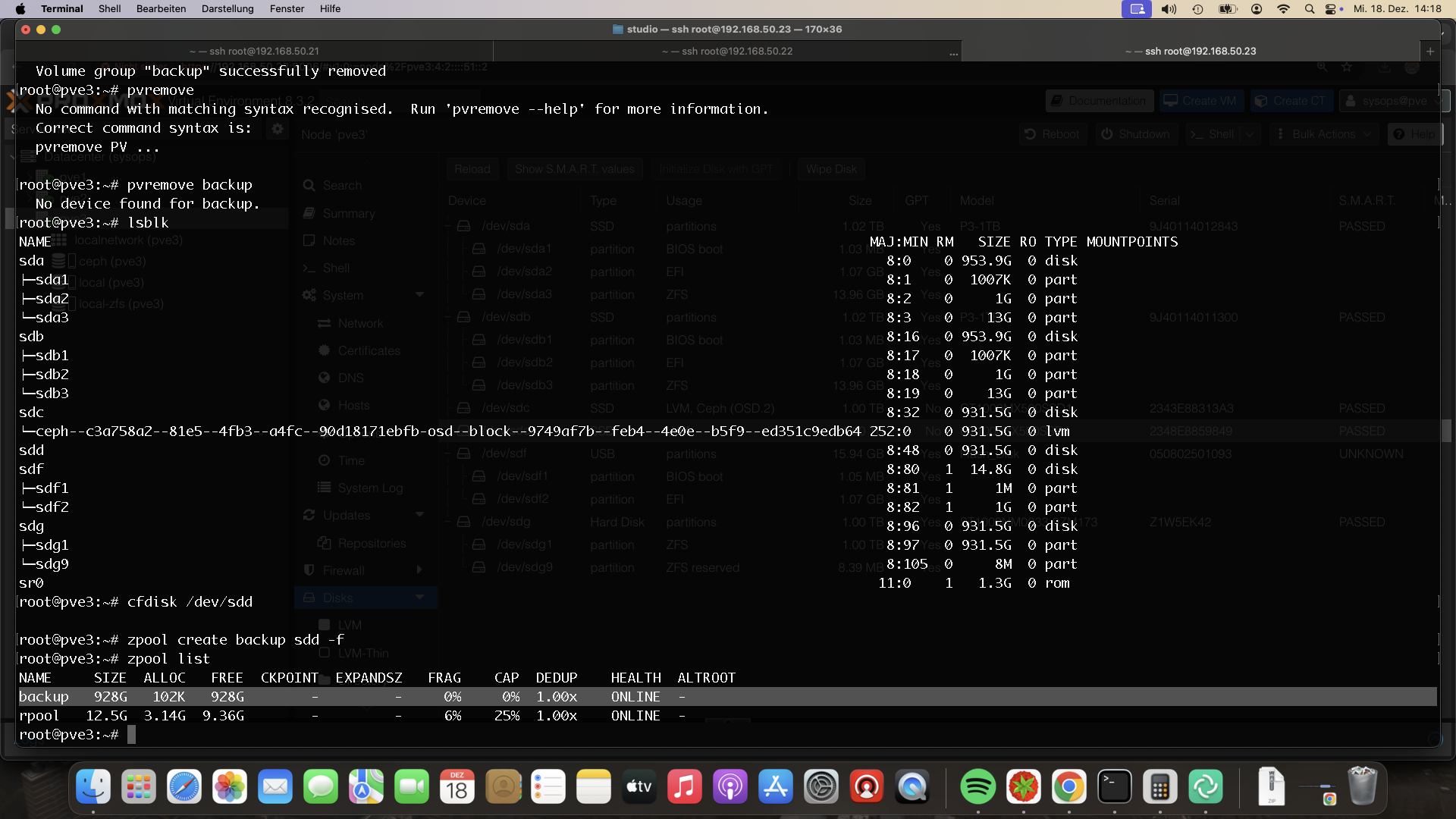
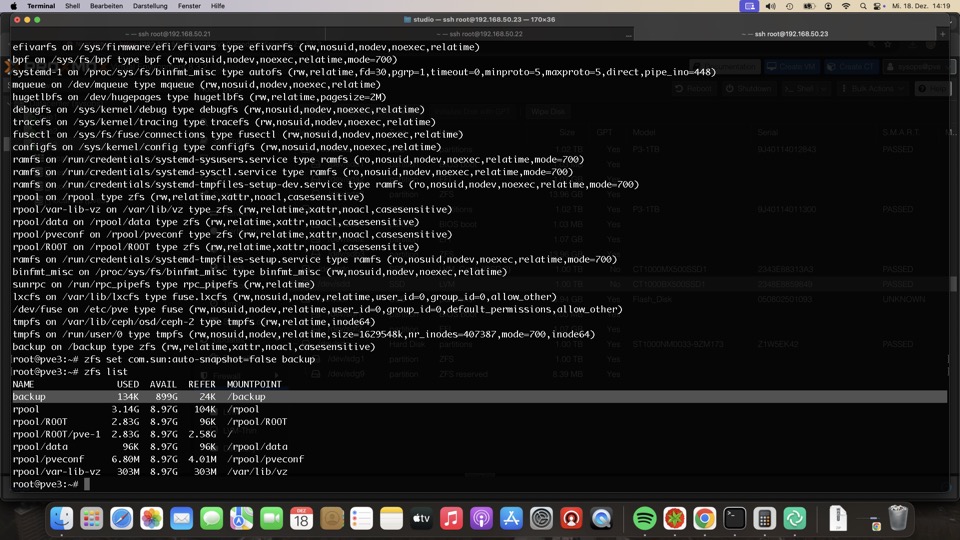
Der Backupstore wird als Mountpoint bereitgestellt. SMB performt hier sehr schlecht
Root User plus Backupuser werden mit 2fa abgesichert!
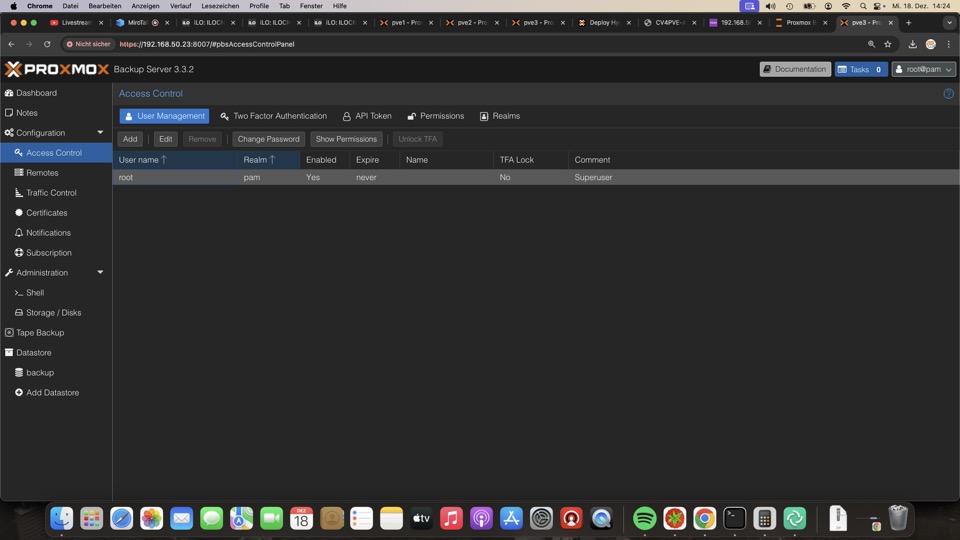
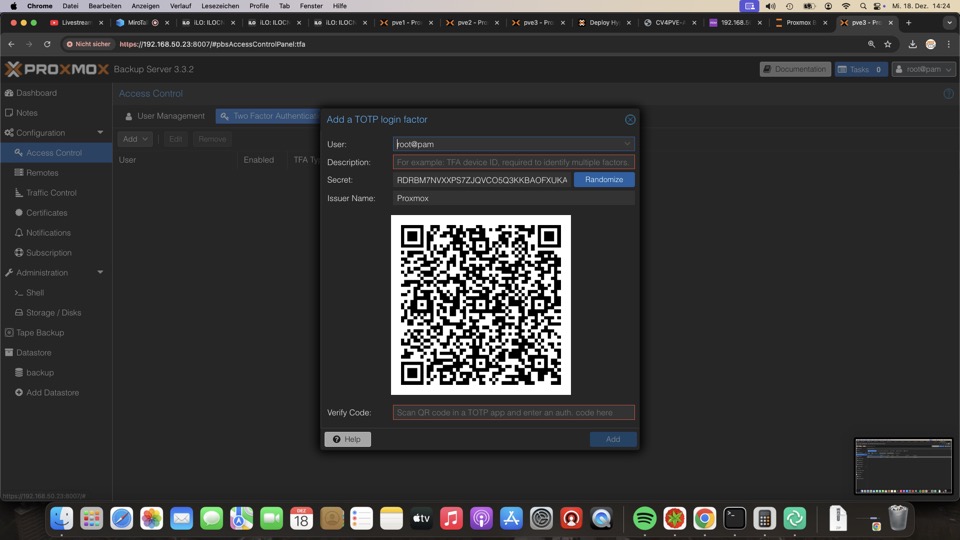
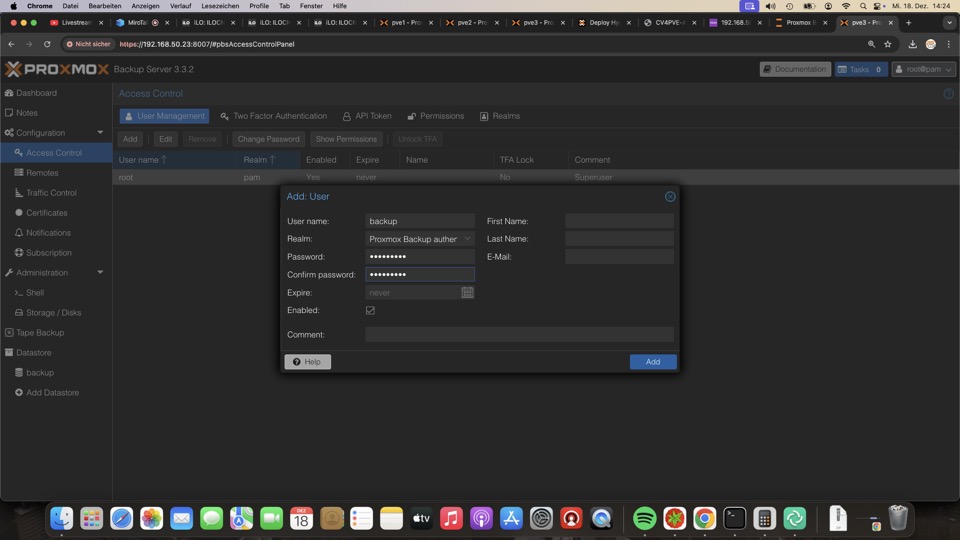
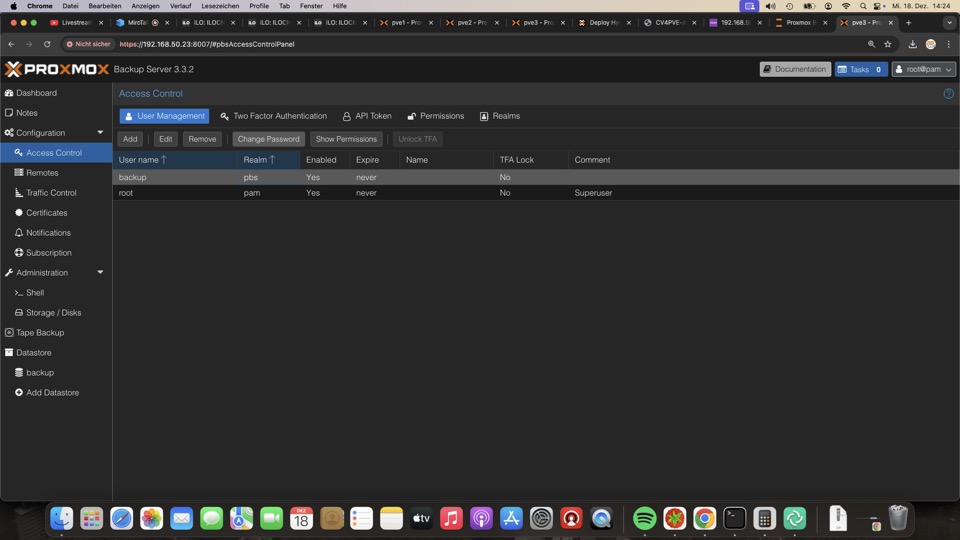
Für die Sicherung benötigen wir einen Token auf den Backupuser
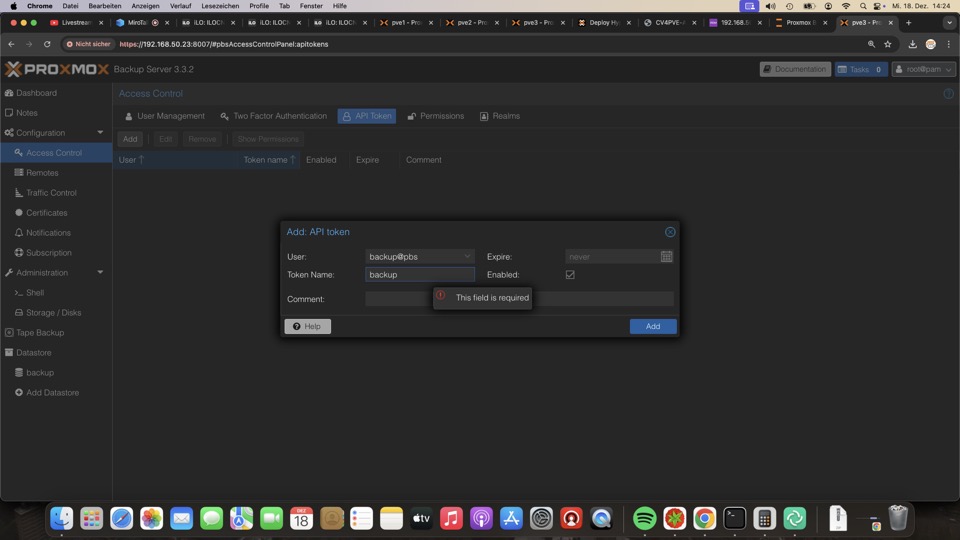
Backup Benutzer und -Token benötigen die Berechtigung Datastore Backup
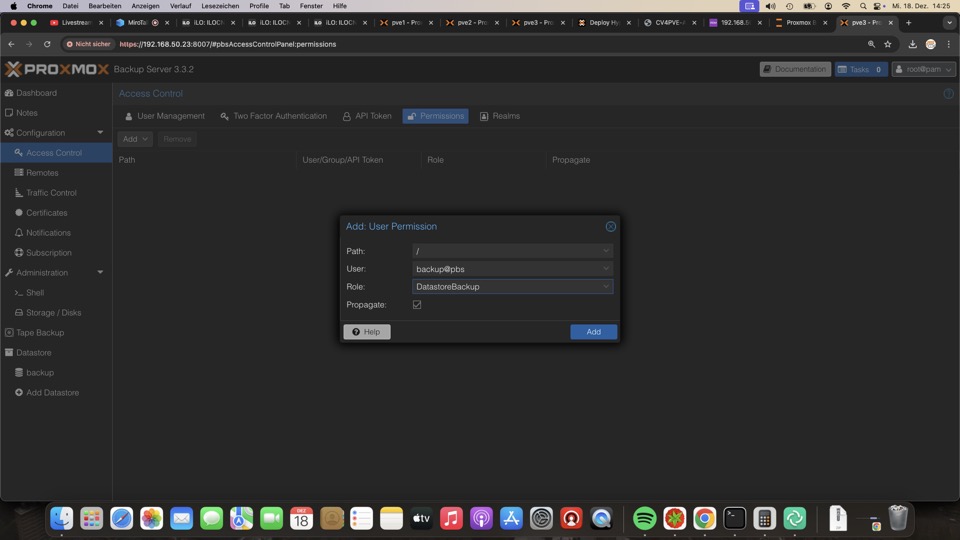
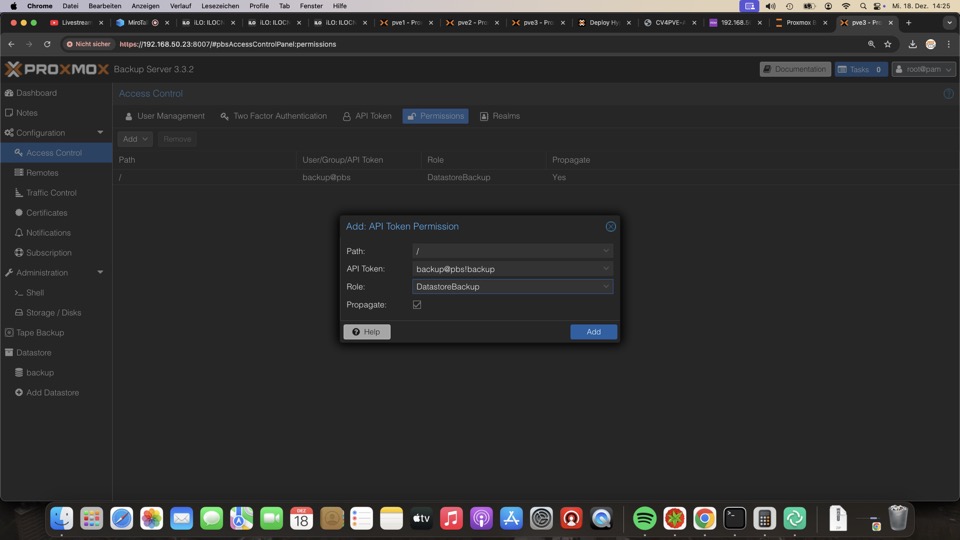
Für den Datastore in PVE benötigen wir mehrere Parameter
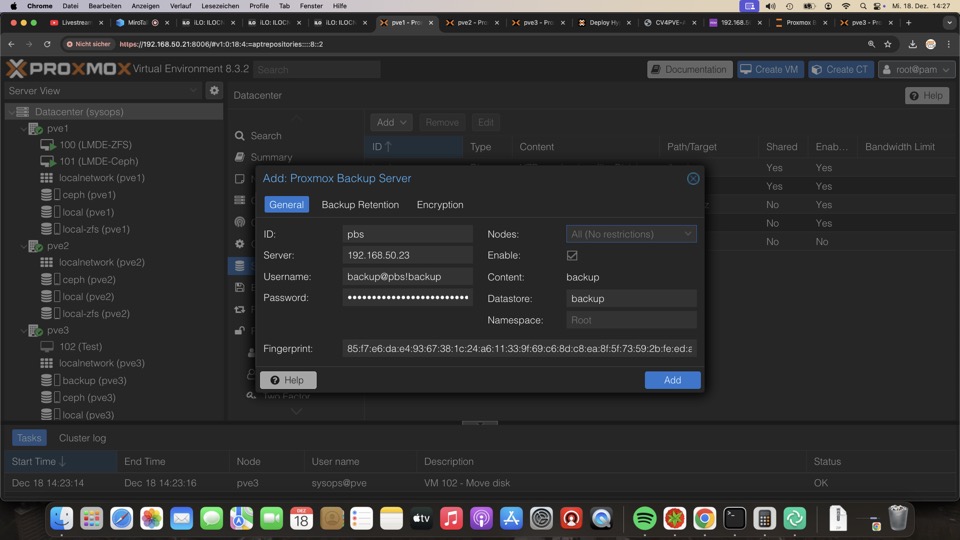
Oben den Datastorenamens seitens PVE, den Tokennamen wie sein Passwort.
Auf der Rechten Seite der Datastorename aus dem PBS und unten dessen Fingerabdruck, den wir auf der Startseite des PBS finden
Danach taucht der Backupstore in jedem PVE auf, wenn gewünscht
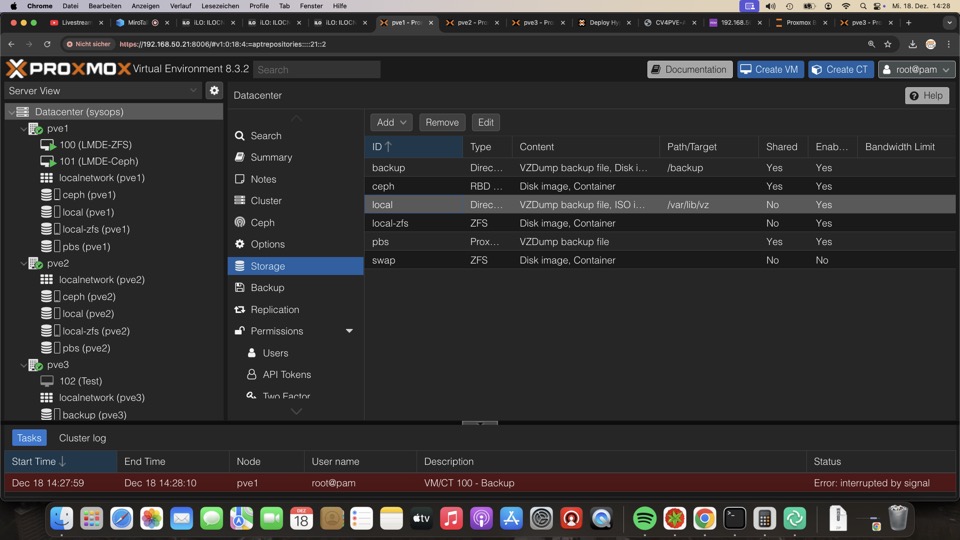
Achtung, das Bootvolume von PVE ist per Default auch als Backupstore definiert, weg damit!
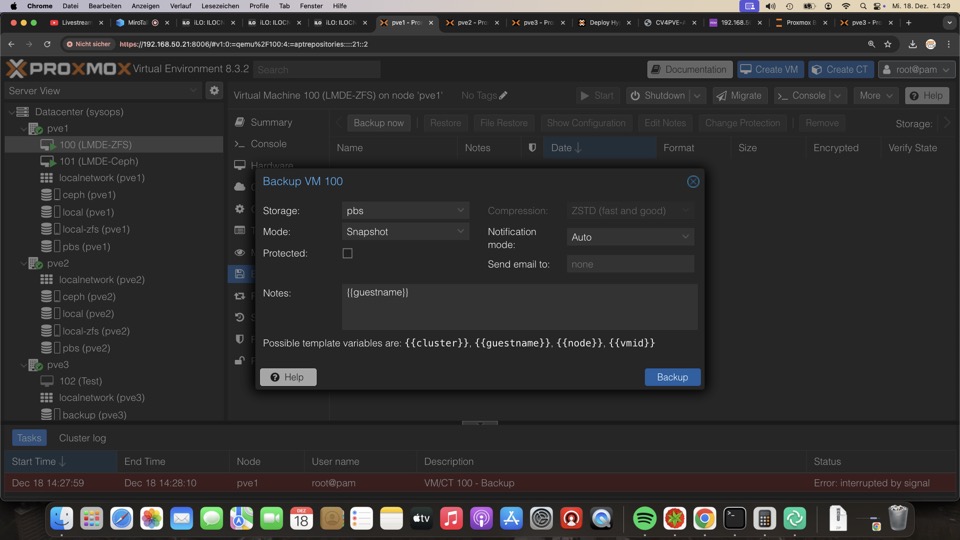
Erstes manuelles Backup zeigt den Dirty-Bitmap Status: created-new, was eine Vollsicherung bedeutet
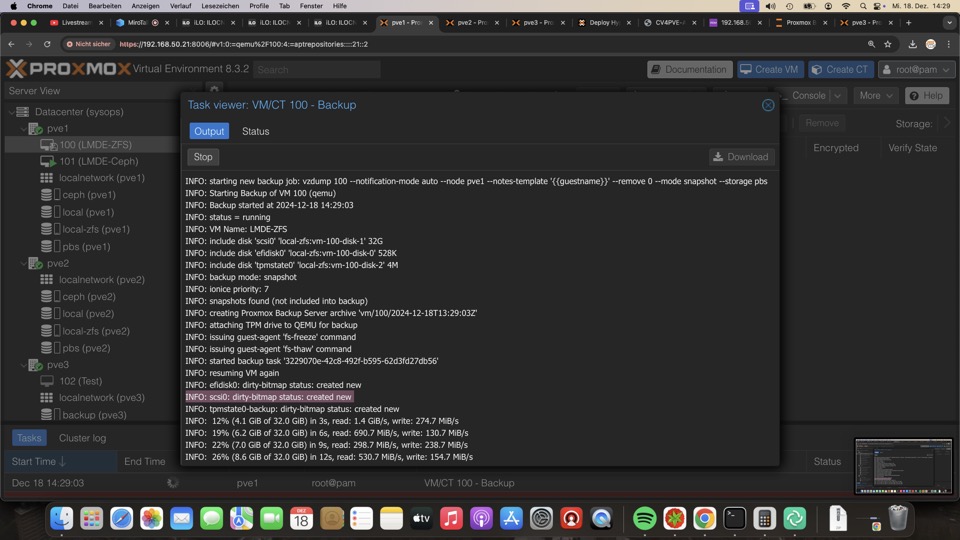
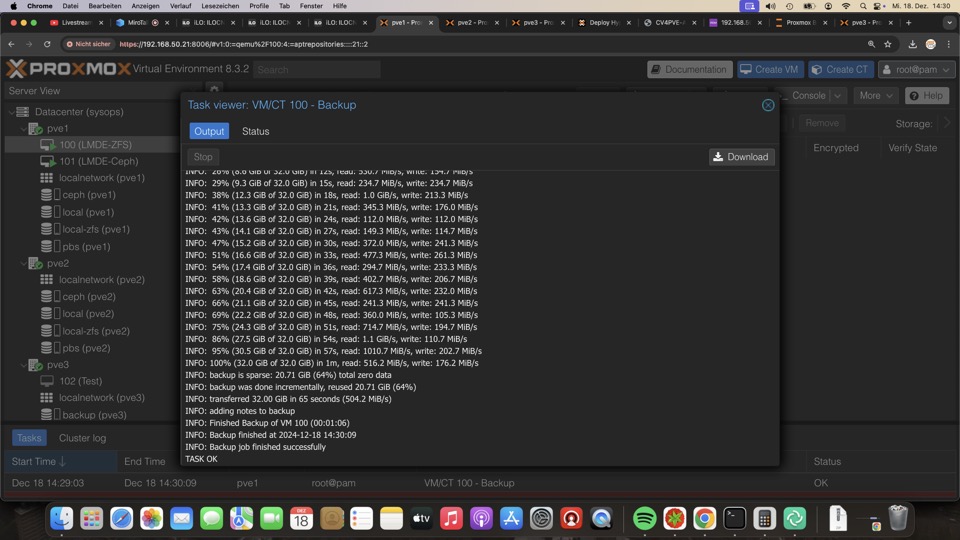
Die zweite Sicherung wird dann inkrementell durchgeführt, bis die VM gestoppt wird!!!
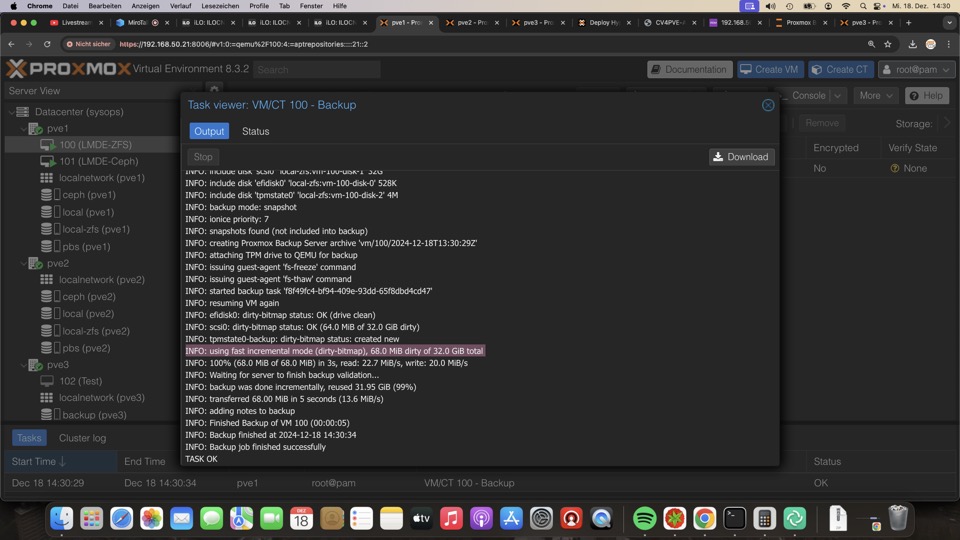
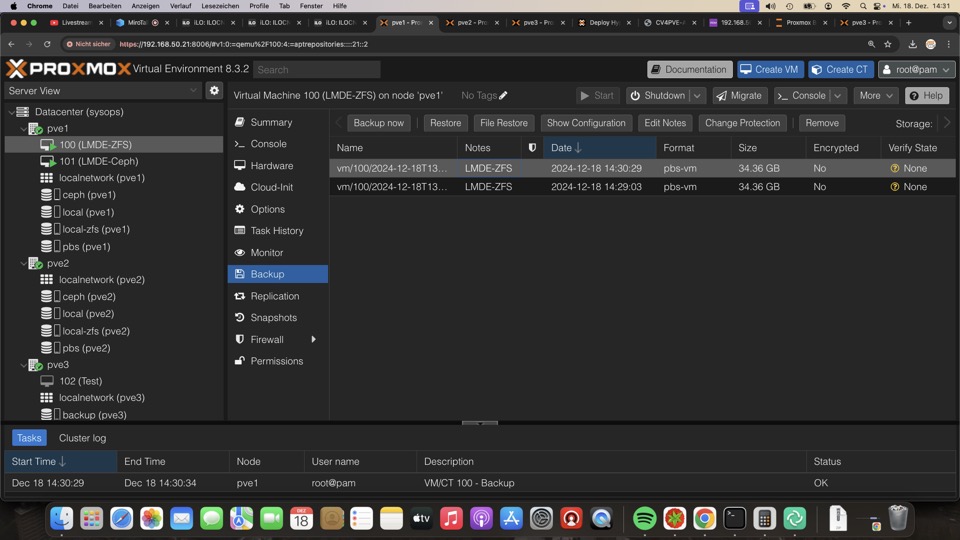
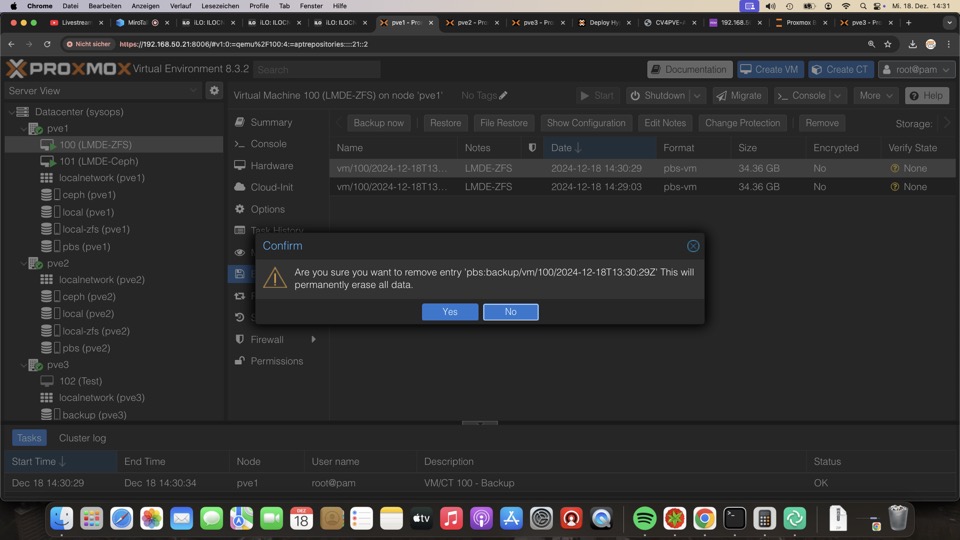
Löschen einer Sicherung ist gewollt nicht über PVE möglich, in PBS kann man das manuell durchführen oder automatisch.
Der Platz wird erst nach einem Prune lauf freigegeben!
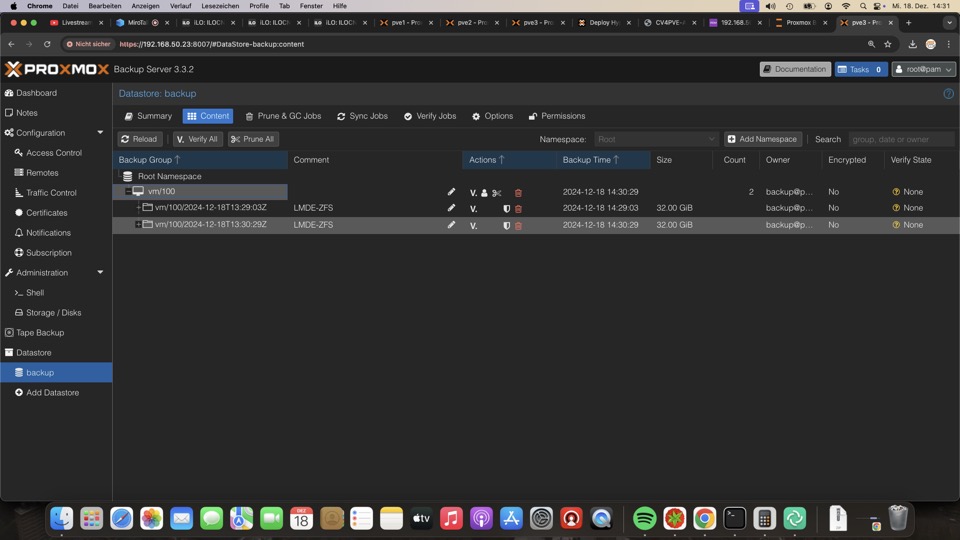
Nach einem Reboot des Hosts oder Stoppen des Gasts wird wieder eine Vollsicherung durchgeführt, jedoch nur neue Chunks auf das Ziel geschrieben. Dadurch geht das auch noch relativ flott. Siehe die MB angaben unten bei der Sicherung

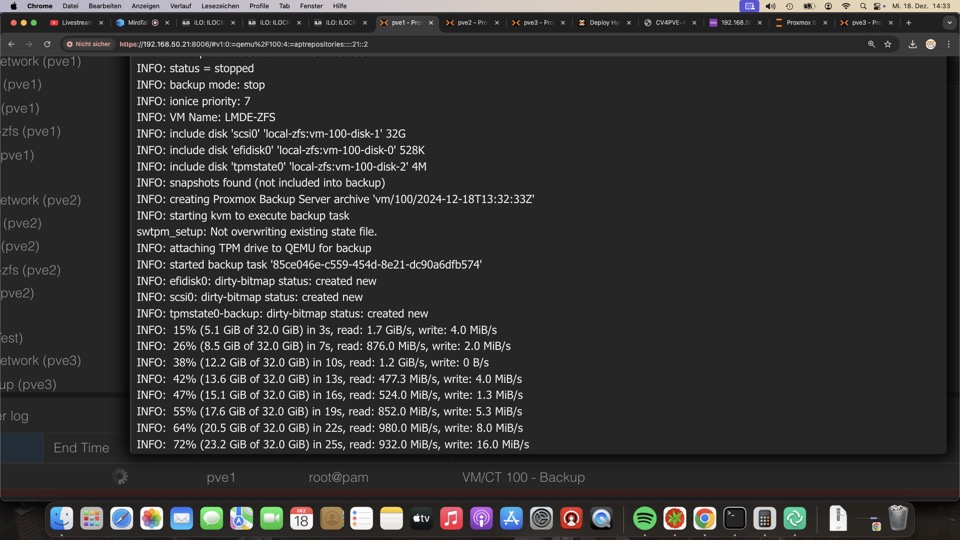
Für den automatischen Lauf immer VMs ausschliessen oder alles mitnehmen. Eine Auswahl der VMs führt zu Fehlern über die Zeit durch Unterlassung
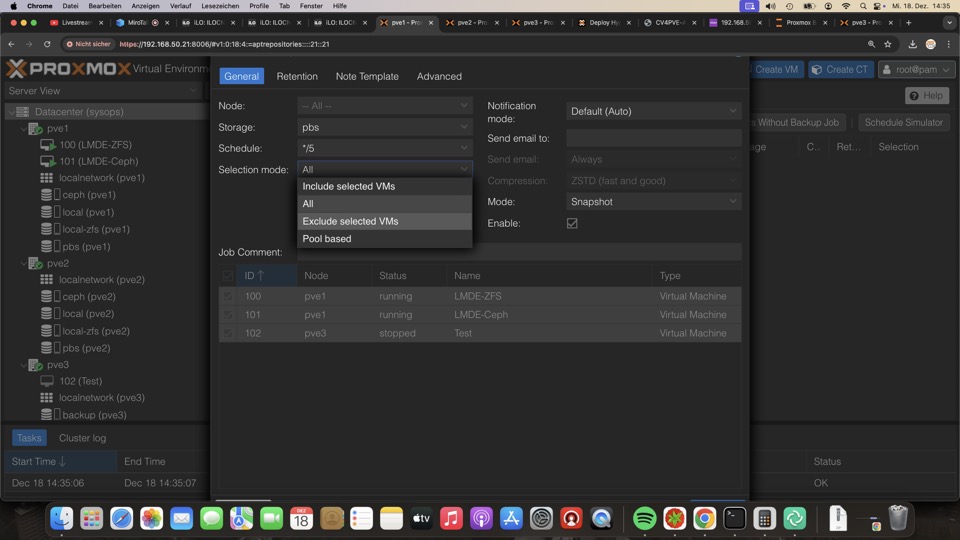
Die Retention, also das Aufräumen hier ist nicht sinnvoll, noch möglich
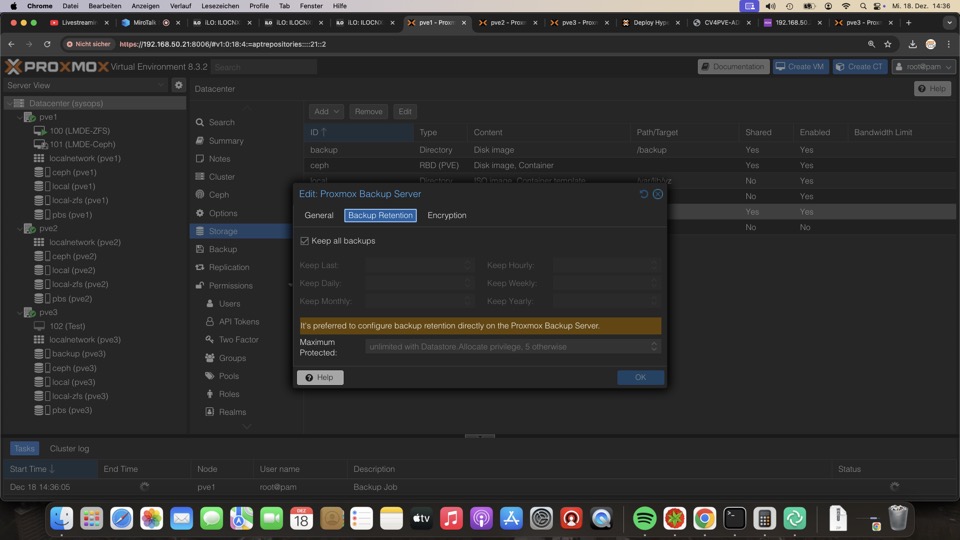
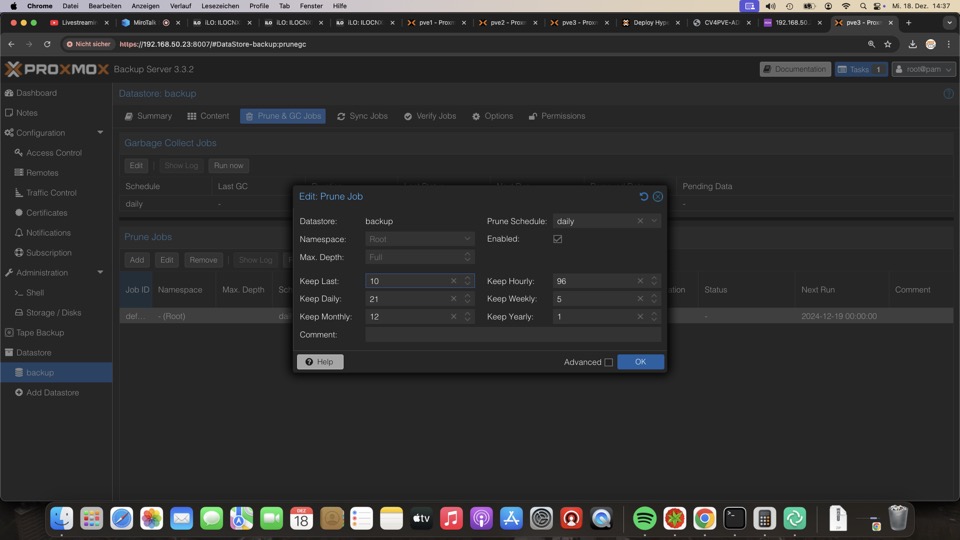
In Prunejobs regelst Du die Aufhebezeiten und die Ausführung der Regel, was aber nur für die Auswahl relevant ist. Der Vorgang geht relativ schnell
Der Simulator von Proxmox hilft dabei
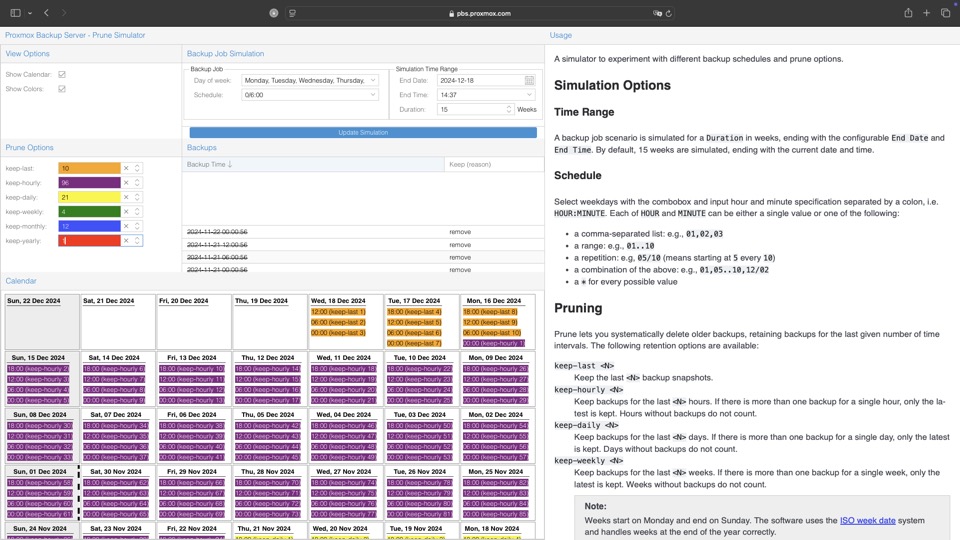

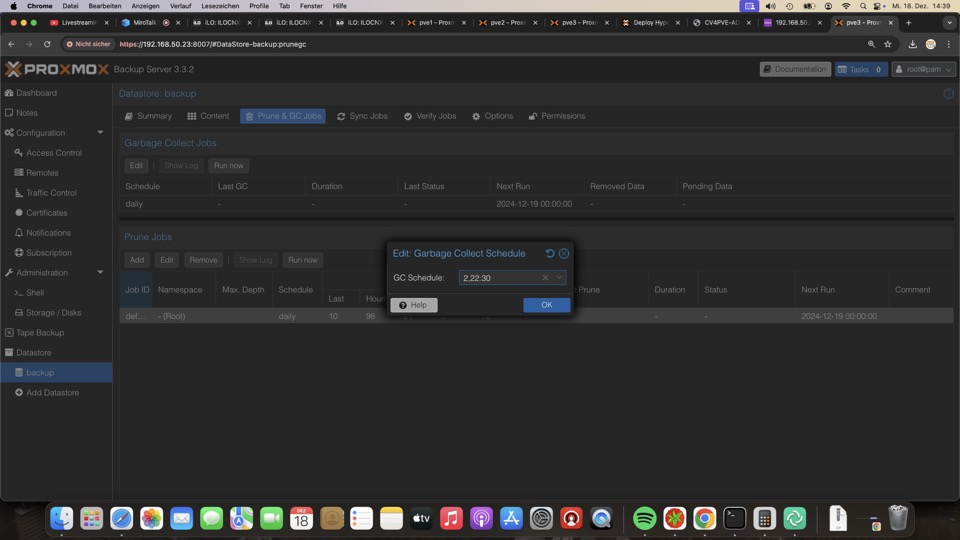
Die Garbage Collection räumt dann alle Junks auf die in keinem Backup mehr benötigt werden.
Der Vorgang hat hohe Last und dauert, also bei Stilstand ausführen
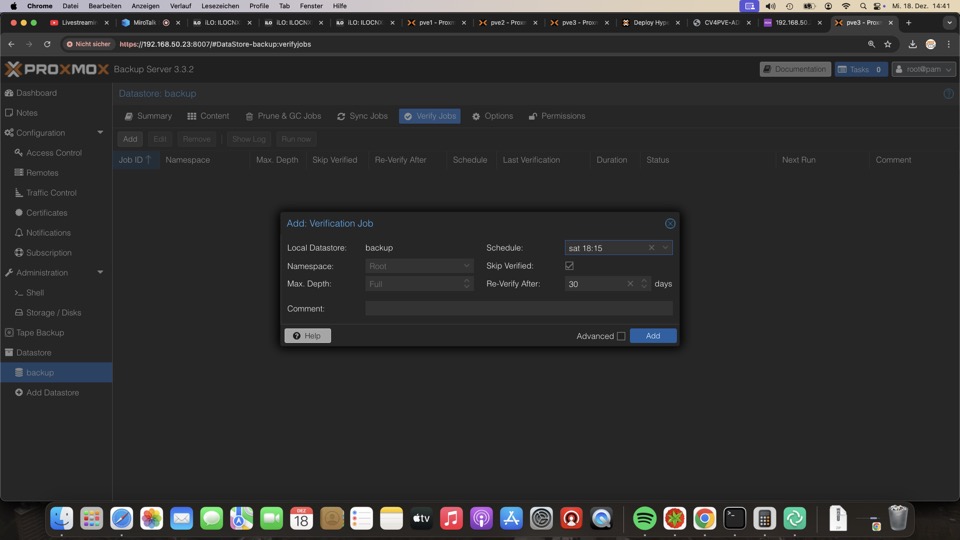
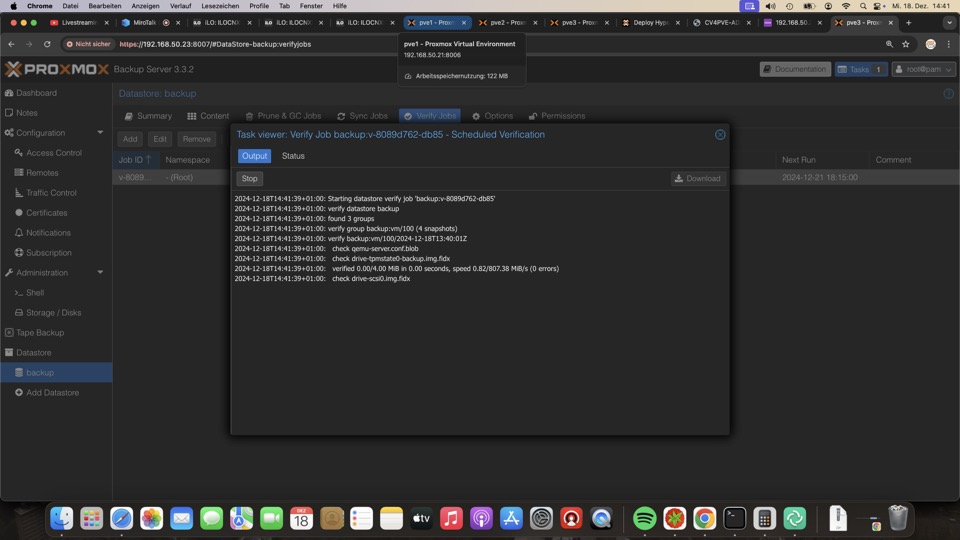
Der Verify Job überprüft regelmässig die Vollständigkeit der Junks und die Integrität der Backups. Der Erfolg wird in der Rechten Spalte in PVE und PBS angezeigt
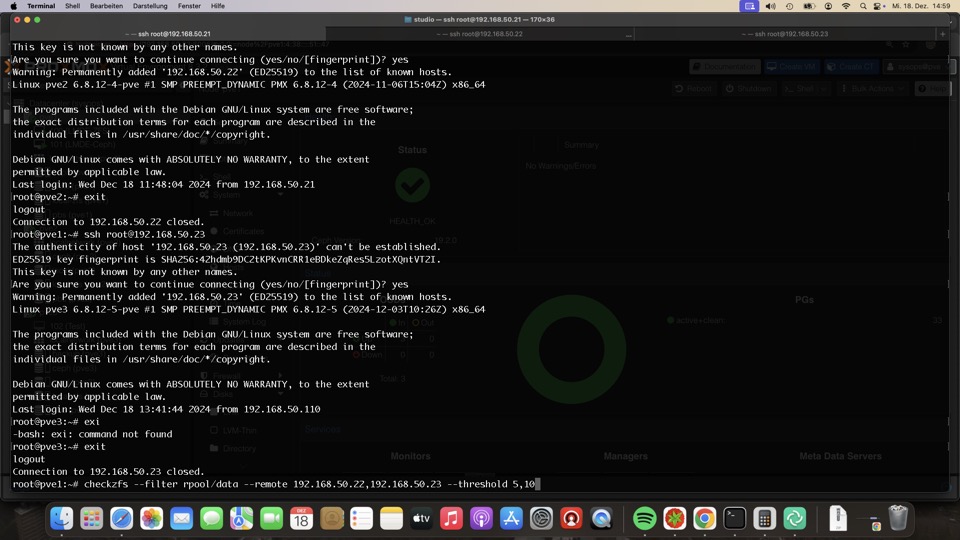
Optional Replikationskontrolle mit checkzfs von #Bashclub
Da unklar ist welcher Host gerade welche ZFS Maschine aktiv betreibt, bleibt uns nur den Vergleich aller Datastores gegeneinander.
Der Vorgang sollte nur ausgeführt werden wenn gerade keine Replikation läuf, sonst spuckt er Fehler
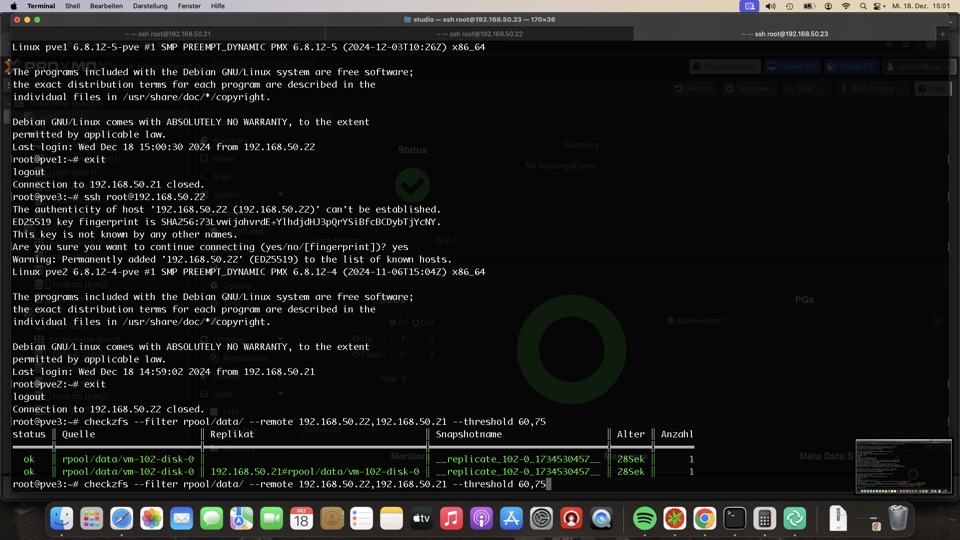
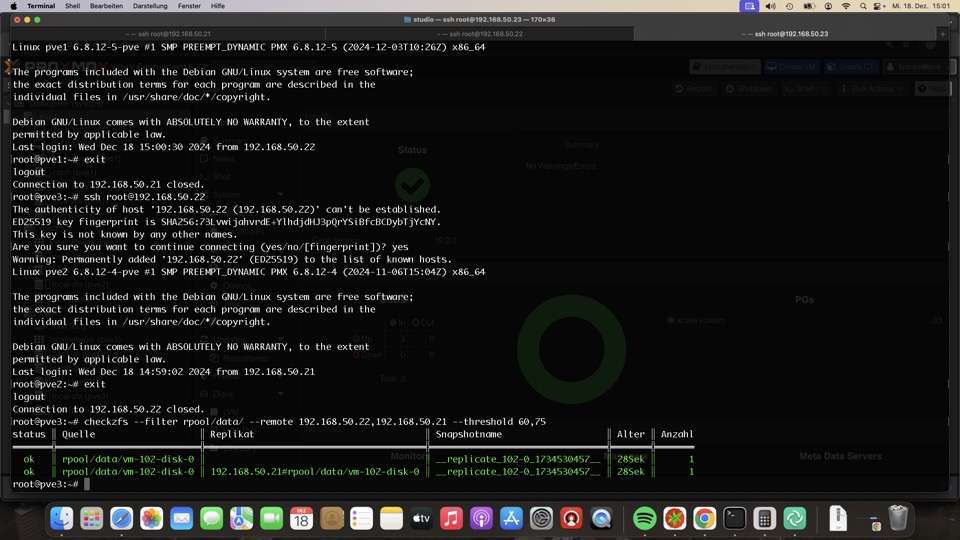
Für diesen Anwendungsfall ist eventuell CV4PVE einfacher, da es auch viele Teile vom Monitoring übernimmt
Vielen Dank für Ihre Aufmerksamkeit
Christian-Peter Zengel (sysops.tv)
Resourcen
https://aow.de/books/ubersicht-des-projekts/page/prospekt - Unser aktueller Prospekt
https://aow.de - Linkliste zu allen Projekten
https://cloudistboese.de - Schulungsportal, alle Kurse können kostenfrei wiederholt werden. Kurse meist online, auch vor Ort
http://youtube.com/sysopstv - Livesendung Montags und Donnerstags gegen 17:15h, Donnerstags Stammtisch online
ZFS Grundlagen am Beispiel Proxmox VE(Stand Januar 2025)
Der Verfasser des Artikels, Christian-Peter Zengel, hat zum Zeitpunkt des Artikels ca 15 Jahre Erfahrung mit ZFS und Proxmox. Er betreibt aktuell ca 150 Systeme mit Proxmox und ZFS
Das Einsatzgebiet geht von Standaloneinstallation bis zu ca 10 Hosts im Cluster. Es ist keine Ceph Expertise vorhanden!
Dieser Dokumentation basiert auf diesem online Kurse von cloudistboese.de
21. + 23.01.2025 (13.00 Uhr bis 17.00 Uhr) - ZFS Grundlagen
ZFS ist die perfekte Grundlage für kleine und mittlere Systeme um gegen Ausfälle, Dummheit anderer und Erpressungstrojanern ideal aufgestellt zu sein.
In diesem Kurs erhalten sie Grundkenntnisse für Systeme wie Proxmox, TrueNAS oder ähnliche Systeme.
Der Fokus liegt auf der Technologie und der permanenten Sicherheit im Umgang mit Daten, Linux und dem Terminal.
Themen:
- Begrifflichkeiten und Überblick
- Basisfunktionen von Proxmox und TrueNAS per GUI
- Erklärung und Beispiele Snapshots und Rollbacks
- Praxisbeispiele Replikation
- Prüfung der Replikationen
- Weitere Features die das Leben massiv erleichtern
Nach diesem Kurs bist Du bei Ausfällen und Datenverlust vor dem Schlimmsten geschützt und in Minuten wieder produktiv!
So erstellt Proxmox VE seinen ZFS Raid
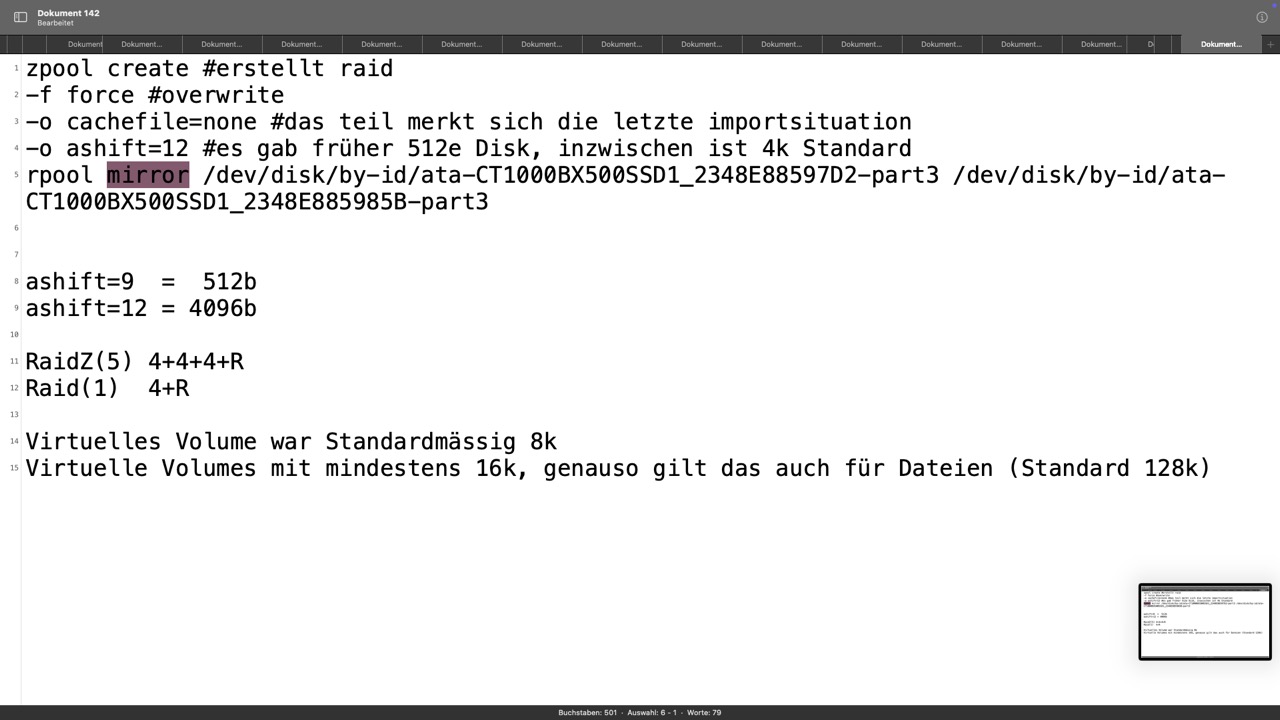
zpool create -f -o cachefile=none -o ashift=12 rpool mirror disk1 disk2
Destruktives Anlegen (-f), kein automatisches Importieren beim Start (-o cachefile=none)
-o ashift=12 ist für 4k Festplatten, ashit=9 für 512e Disks, wobei man mit 12 nichts verkehrt macht
rpool ist der Name vom künftigen Pool, mirror der Raidlevel und die Disks wurden zweifelsfrei über Ihre ID definiertOptionen für Raidlevel wären noch: ohne als Stripe, raidz, raidz2 oder raidz3, also Raid Level 5-7
Die ersten Zpool Manöver und die endlose Aktionsliste sieht man mit
zpool history
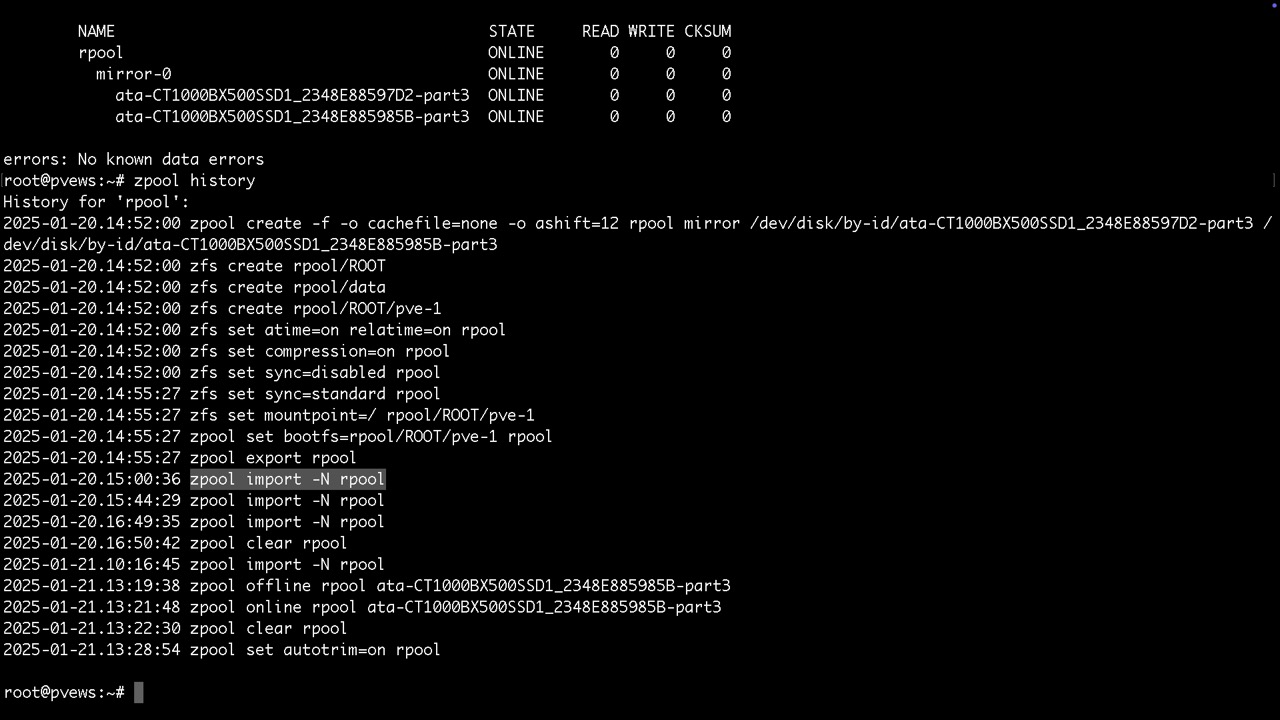
Manuelles Trimmen der SSDs um gelöscht Blöcke schner überschreiben zu können findet man unter /etc/cron.d
Ebenso wird nach diesem Zeitplan der sog. zpool scrub durchgeführt, der die Konsistenz der Redundanz prüft und ggf. korrigiert. Gefundene Fehler findet man dann mit zpool status
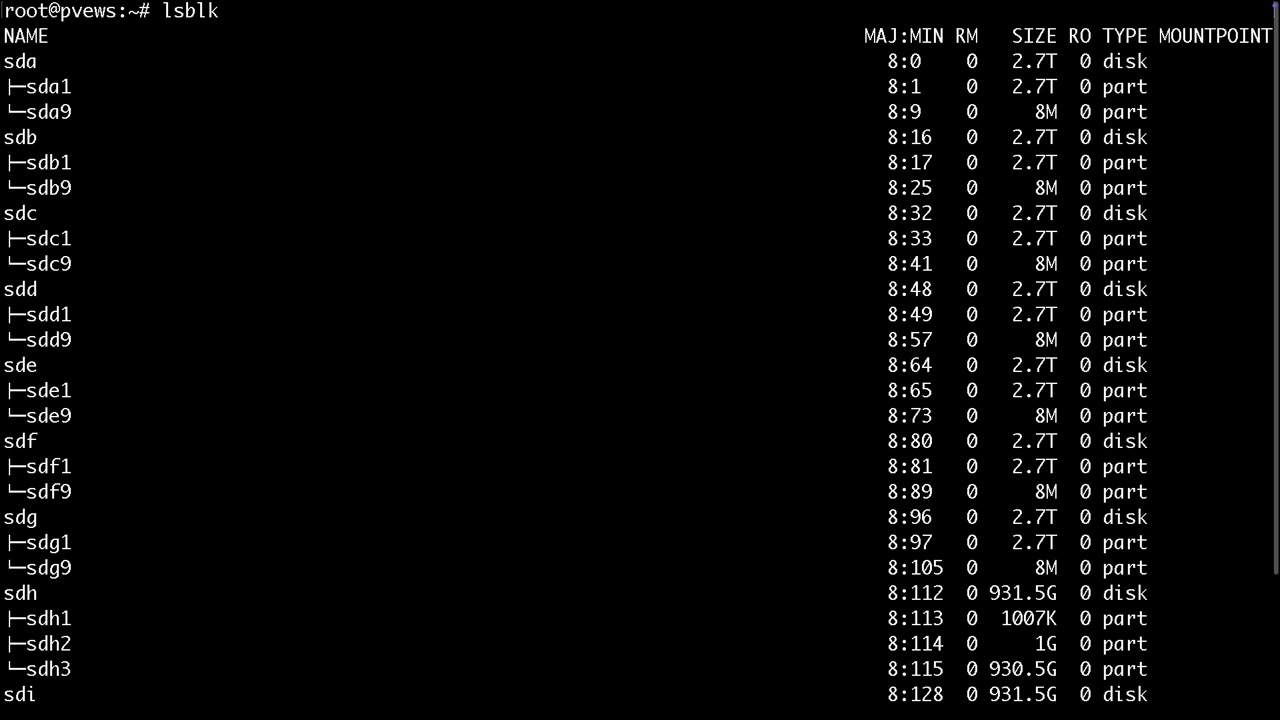
Zum identifizieren der Platten bieten sich neben der PVE GUI noch folgende Befehle an. Es wird dringend empfohlen bereits genutzte Platten via PVE GUI zu wipen
dmesg -Tw (live)
lsblk
ls -althr /dev/disk/by-id
Erstellen verschiedener Raidlevel und Ihrer Vorzüge
Mit ls -althr /dev/disk/by-id haben wir folgende Festplatten anhand ihrer aufgedruckten WWN Kennung identifiziert. Es ist dringend empfohlen bei HBAs sich die Slots und die Seriennummern beim Einbau zu notieren und in die Dokumentation aufzunehmen
wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
Stripe, also Raid0
zpool create -f test wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
Mirror, also Raid1
zpool create -f test mirror wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c
Striped Mirror, also Raid10
zpool create -f test mirror wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c mirror wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 mirror wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
RaidZ, also Raid 5, Nettoplatz x-1
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
RaidZ2, also Raid 6, Nettoplatz x-2
zpool create test raidz2 wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
RaidZ-0, also Raid 5-0, Nettoplatz x-2, in diesem Beispiel
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
oder mit Spare, wenn Du davon nicht booten musst
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 spare wwn-0x5000cca01a8417fc
Erweiterung eines RaidZ zum RaidZ-0
zpool add -n test raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
Erweiterung eines Raid durch Ersetzen mit größeren Platten
Die Platten müssen die Gleiche Geometrie hanben, also 4k zu 4k oder 512e zu 512e
Bei Raid 1 und 10 reicht es zwei Disks zu tauschen, bei RaidZx müssen alle Disks getauscht werden
Replace Vorgänge können auch laufen ohne die Redundanz zu brechen, wenn weitere Slots frei sind
Bei Erweiterung durch Austausch von großen und vor allem älteren Raid 10 prüfen ob in einem Mirror ggf. neue Platten getauscht wurden, diese sollten weiter im Betrieb bleiben, während ältere Paare getauscht werden können
Caches und Logdevices
Vorsichtig formuloiert, Lese- und Schreibcache
First Level Cache, sog. ARC kommt aus dem RAM und bekommt idealerweise ca. 1GB für 1TB Nettodaten
Second Level Cache wird als Cachedevice als Partition auf einer schnelleren Disk als der Pool hat bereitgestellt, z. B. am idealsten mit NVMe
zpool add test -n cache sdl
Logdevice (Writecache muss gespiegelt werden)Damit der Log auch genutzt wird muss man noch mit zfs set sync den cache aktivieren
zpool add test -n log mirror sdl
zfs set sync=always test
Arc wird mit "arcstat 1" ausgelesen, er wird bei der Installation festgelegt oder später unter /etc/modprobe.d/zfs.conf geändert. update-initramfs -u macht das dann persistent und aktiviert die Änderungen beim nächsten reboot.Zur Laufzeit ändert man den Firstlevelcahce mitCache- und Logdevices mit zpool iostat 1
echo 2147483648 > /sys/module/zfs/parameters/zfs_arc_max
echo 1073741824 > /sys/module/zfs/parameters/zfs_arc_min
free -h && sync && echo 3 > /proc/sys/vm/drop_caches && free -h
arcstat 1
Test der Leistung eines Pools
zfs create -o compression=off test/speed
cd /test/speed
dd if=/dev/zero of=dd.tmp bs=256k count=16384 status=progress
dd if=/dev/zero of=dd.tmp bs=2M count=16384 status=progress


Erweiterung der Funktionen des Pools
zpool status meldet neue Funktionen im ZFS und kann leicht und schnell mit
zpool upgrade -a
erledigt werden
Jedoch würde ich in jedem Fall empfehlen zu prüfen ob meine Notfall ISO diese Funktionen bereits unterstützt!
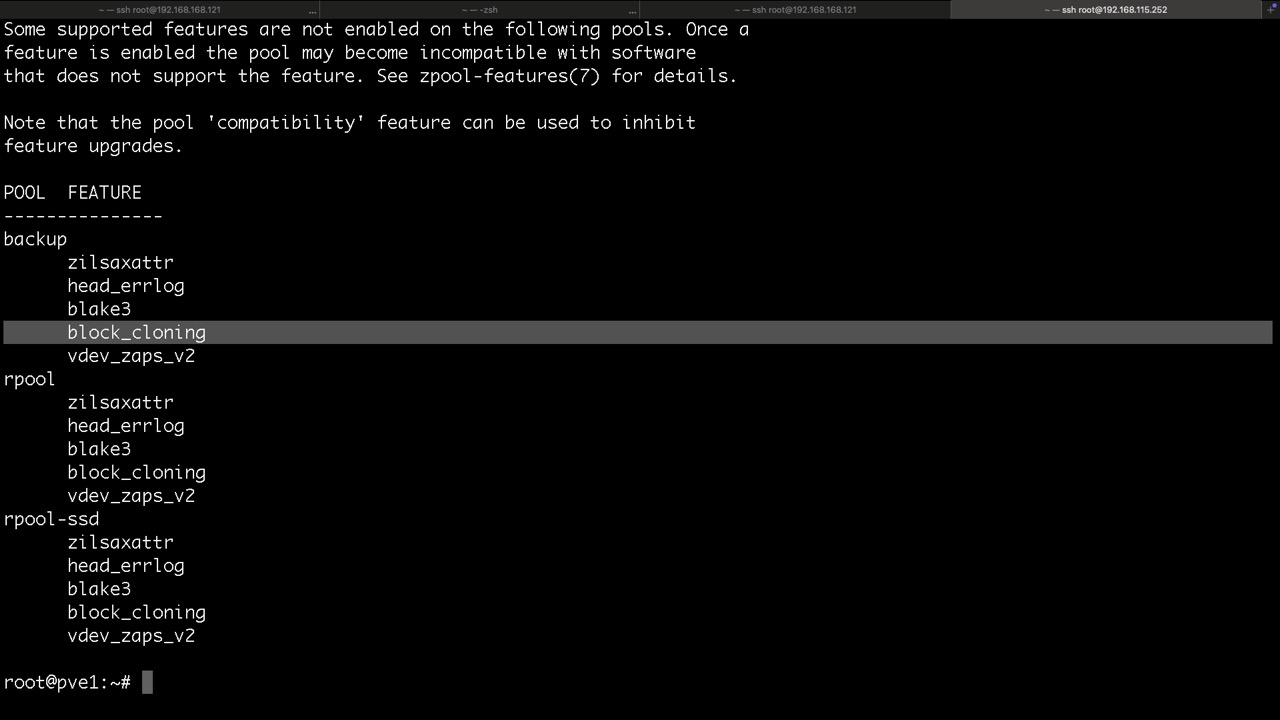
Für das Auslesen der Parameter von Pools, Volumes, Datasets und Snapshots gibt es den Parameter get
Bereitstellen und entfernen von Pools ohne löschen
zpool import #zeigt was es zum importieren, also bereitstellen gibt
zpool import poolname oder -a für alle importiert den Pool oder alle verfügbaren Pools
Am elegantesten importiert man den Pool über
zpool import -d /dev/disk/by-id
damit man hinterher nicht sda, sdb, sondern die Bezeichner im Status sieht
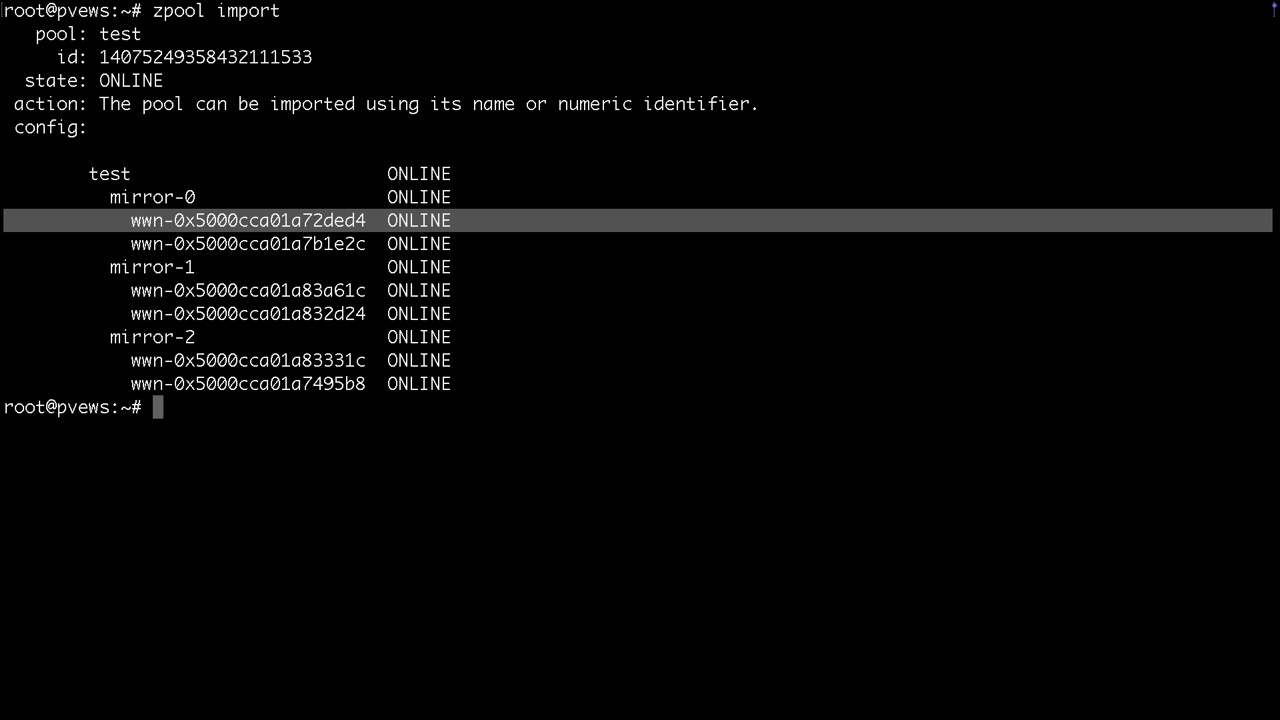
Nach der Bereitstellung würde man hier lediglich einen Mountpoint /test finden, bei TrueNAS /mnt/test. Dazu noch die Systemdatasets vom Proxmox selbst. Danach legen wir gleich mal ein Dataset namens dateisystem und ein Volume namens volume an.
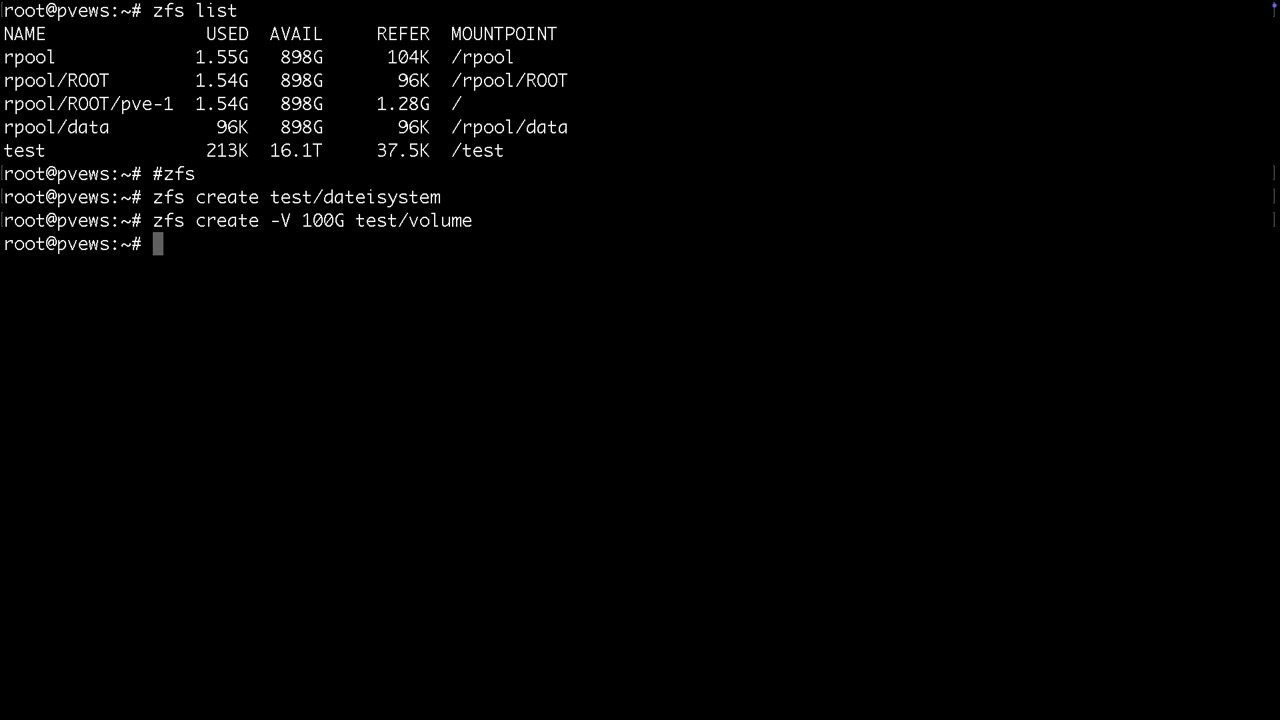
Datasets werden als Ordner gemountet und / oder /mnt
Volumes findet man unter /dev/zd... und zusätzlich mit vernünftigen Namen unter /dev/zvol/tankname/....
Datasets werden mit Linuxcontainern, Backupfiles, Vorlagen oder Serverdateien bespielt
Volumes verhalten sich wie eingebaute Datenträger, jedoch virtuell. Sie stehen nach dem Import des Pools bereit und können in einer VM genutzt werden. Manipulationen an Volumes zur Vorbereitung oder Datenrettung können jedoch ebenso auf dem PVE Host vorgenommen werden
Diese Schritte übernimmt üblicherweise der Installer in der VM und sollen nur aufzeigen wie diese ZVOLs genutzt werden

Proxmox legt seine Datasets für LXC so ab
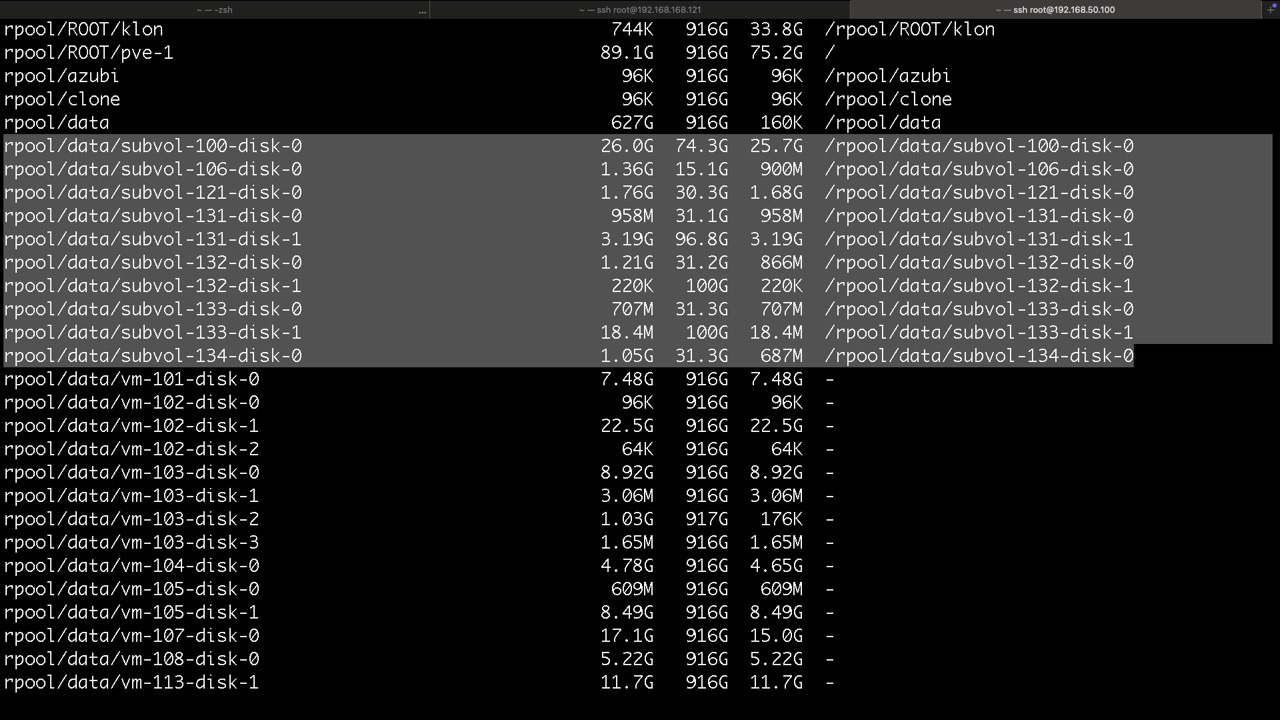
und so die ZVOLs für VMs mit KVM, hier findet man die virtuellen Disk und /dev/zvol...
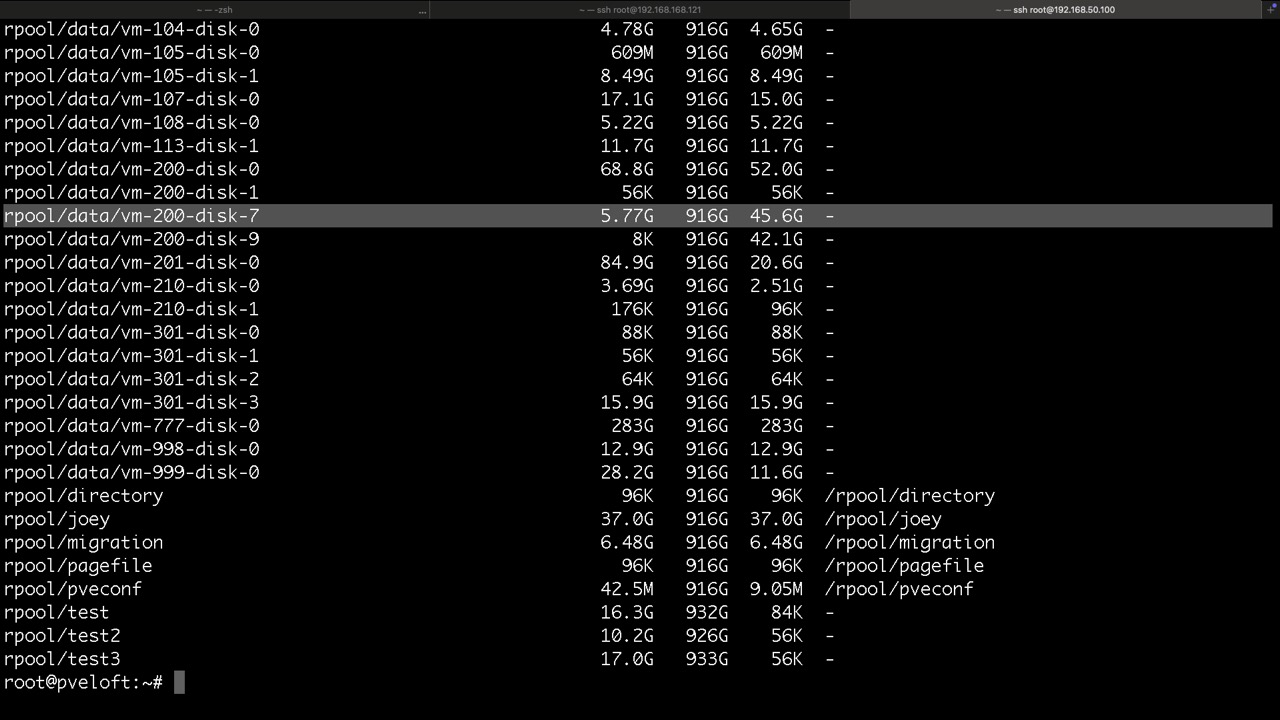
Thin- und Thickprovisioning für Datasets und Volumes
Am Beispiel von Proxmox VE via GUI wird hier eine Thinprovision Festplatte für VM 301 mit 32GB und einer Standardblockgröße von 16k erzeugt. 8k sind nur bei Raid1 und 10 möglich. Hakt man den Thinprovision Haken nicht an, wird beim Erzeugen noch die Option -o refreservation=32G ergänzt. Diese macht bei ZFS mit Autosnapshots aber keinen Sinn
zfs create -s -b 16k -V 33554432k rpool/data/vm-301-disk-4
rpool/data/vm-301-disk-4 56K 1.17T 56K - #hier kein Mount sonder unter /dev/zvol/...
Bei LXC werden Datasets genutzt und der Platz via Reservierung genutzt, wobei bei der genutzten Refquota auch die Snapshotaufhebezeiten den Nettoplatz verkleinern, daher größer dimensionieren, gerne mal doppelt so groß
zfs create -o acltype=posixacl -o xattr=sa -o refquota=33554432k rpool/data/subvol-106-disk-1
rpool/data/subvol-106-disk-1 96K 32.0G 96K /rpool/data/subvol-106-disk-1 #hostzugriff möglich
Virtuelle Diskimages wie QCOW2, VMDK oder RAW-Dateien legt man üblicherweise nicht in Datasets, bestenfalls für NFS oder iSCSI Server
Snapshots
Snapshots können jederzeit erstellt oder gelöscht werden. Die Datasets und Volumes befinden sich immer in einem Livezustand der sich durch die Vektorkette der eventuell vorhandenen Snapshots ergibt. Entfernt man einen Snapshot, so verändert sich der Weg der Vektoren. Das Ganze geschieht fast ohne Last!
ZFS selbst bringt weder Workflows für Snapshotting, noch Replikationen mit. Es stellt nur die Werkzeuge bereit
Snapshots generiert man bei Proxmox offiziell mit der GUI manuell oder für Replikationen, jedoch leistet dieser Workflow nicht genug.
Daher nutzen wir...
apt install zfs-auto-snapshot -y
ZFS-AUTO-SNAPSHOT legt seine Verknüpfungen in alle Cronordner. Proxmox VE weiß erst mal nichts davon. Zu berücksichtigen ist hier lediglich daß wir den Pool nicht über 80% befüllen wollen. Gehen wir darüber hinaus, müssen wir in den Cronordnern die Verknüpfungen anpassen um die Aufhebezeiten zu reduzieren.
nano /etc/crontab #kann angepasst werden, die viertelstündlichen finden sich unter cron.d!
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.daily; }
47 6 * * 7 root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.weekly; }
52 6 1 * * root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.monthly; }
cat /etc/cron.hourly/zfs-auto-snapshot
exec zfs-auto-snapshot --quiet --syslog --label=hourly --keep=96 // #also in dem Fall 96 Stunden
Wir empfehlen für den Start folgende Settings: Drei Monate, sechs Wochen, zehn Tage, 96h und 12 Viertelstunden
Damit kommt man auf ca. 2,5x- 3x so viele Daten wie belegt wären ohne Snapshots. Erfahrungswert.
Das wären pro virtueller Disk oder LXC Mountpoint etwa 127 Snaphots, bei 20 Disks über 2540.
Nicht davon abschrecken lassen, es geht auch easy fünfstellig, wenn die IO stimmt!
Die in PVE eingebaute Snapshotfunktion sollte nicht mit den Autosnapshots kombiniert werden.
Im Problemfall stoppen wir die VM, manipulieren was zu machen ist und starten sie wieder!
Der eigentliche Vorteil der Snapshots in der GUI ist die Notierung der VM Definition zur Zeit der Erstellung, was wir über ein Backup im hauseigenen Postinstaller kompensieren. Dort findet man die Historie der PVE Config
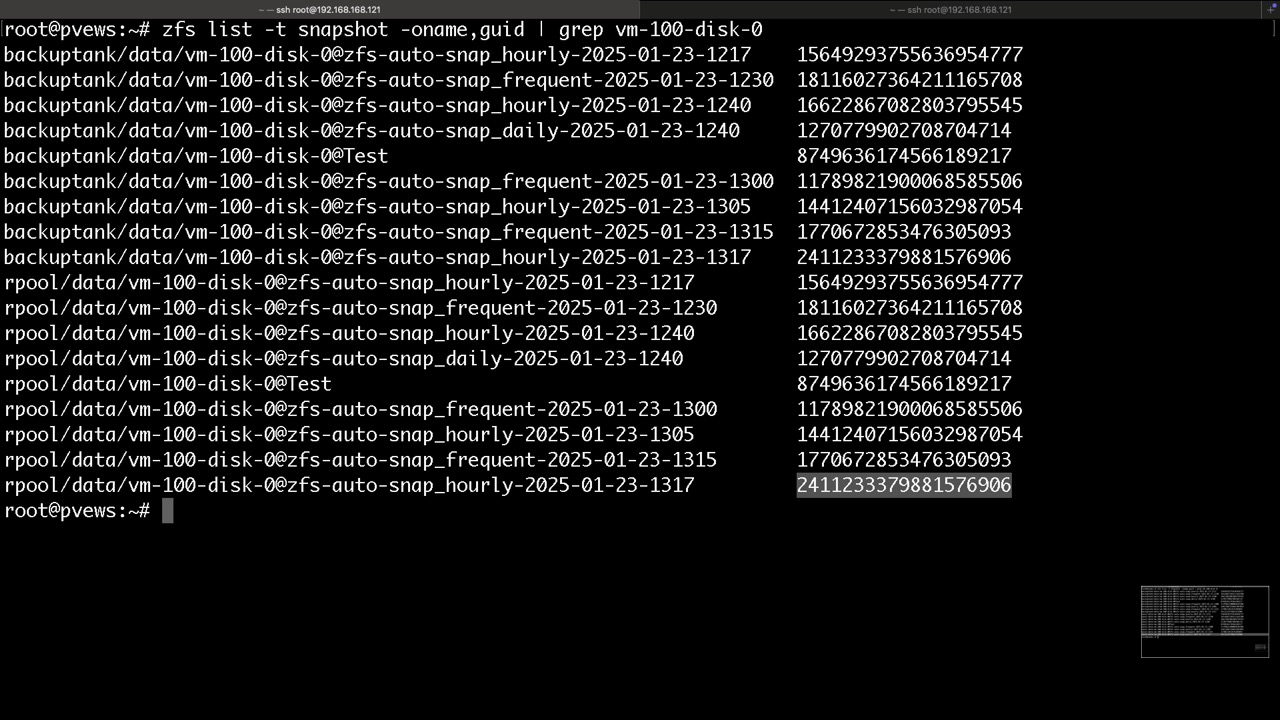
Kleines manuelles Beispiel, was für uns aber Z-A-S übernimmt
Snapshot
zfs snapshot tank/sub/datasetodervolume@snapshotname
Auflisten
zfs list -t snapshot tank/sub/datasetodervolume
VM oder LXC ausmachen
Rollback
zfs rollback -r rpool/data/vm-100-disk-0@Test #danach ist alles neuere weg!
VM oder LXC starten
Dynamik von Snapshots
Wir unterscheiden zwei Sorten von Datennutzung
- Zunehmende Datennutzung wie bei einem NAS
- Es kommt nur was dazu und wird selten gelöscht
- Viele Snapshots auf lange Zeit ändern nichts an der Gesamtnutzung des Pools
- Replikation außer Haus kann in kleinen Schritten passieren, da die Gesamtübertragung gleich groß ist
- Rotierende Datennutzung wie bei einem Datenbankserver
- Daten verändern sich permanent, wenig Zuwachs
- Viele Snapshots auf lange Zeit ändern brachial viel an der Gesamtnutzung des Pools
- Replikation außer Haus sollte in einem Schritt, ohne Zwischensnapshots passieren, da die Gesamtübertragung sonst ein vielfaches größer sein kann
- Nur essenzielle Wiederherstellungspunkte sollten aufgehoben werden um das System nicht unnötig zu befüllen
Dynamik von Snapshots
Dank ZFS kann man langfristig Replikationen inkrementell vornehmen, jedoch dauert die erste Replikation natürlich länger, wenn schon Datenbestand da war
Übliche Vorgehensweise einer Datenübertragung
PC NTFS>SMB> Datei > SAMBA Server BTRFS LVM > EXT4 Datei = Konsistent? Bitrod?
Zu viele Köche verderben die Köchin
Funktion von Snapshotreplikation
Von ZFS zu Datei, was wenig Praxis findet
zfs send tank/dataset@snapshot > datei.zfs
zfs recv tank < datei.zfs
Von ZFS zu ZFS, was üblich ist
zfs send | zfs recv #laufen immer gleichzeitig
zfs send rpool/data/vm-100-disk-0@Test | zfs recv -dvF backuptank
#überträgt den Zustand Test auf ein lokalen weiteren Pool, wobei das zfs Tool immer doppelt läuft
Pushreplikation
zfs send -pvwRI rpool/data/vm-100-disk-0@Test rpool/data/vm-100-disk-0@zfs-auto-snap_hourly-2025-01-23-1317 | zfs recv -dvF backuptank
#Fortschritt, Infos, Rohdaten plus Historie, ideal für verschlüsselte Volumes, erspart das De- und Komprimieren
Workflow
- Erzeugen eines Datasets oder Volumes
- Snapshot auf Dataset oder Volume ausführen
- Übertragung des Snapshotzustands auf Ziel, optional mit Zwischenständen
Trojanerproblem: Wer auf Quelle sitzt kann Pushziele löschen
Lösung: Pullreplikation, ähnlich Backupsoftware, Transport SSH, Daten ZFS
Quelle |> Pullserver
zfs recv | ssh root@quelle zfs send #Pull Replikation via SSH
Von PVE zu PVE, was uns zu wenig ist
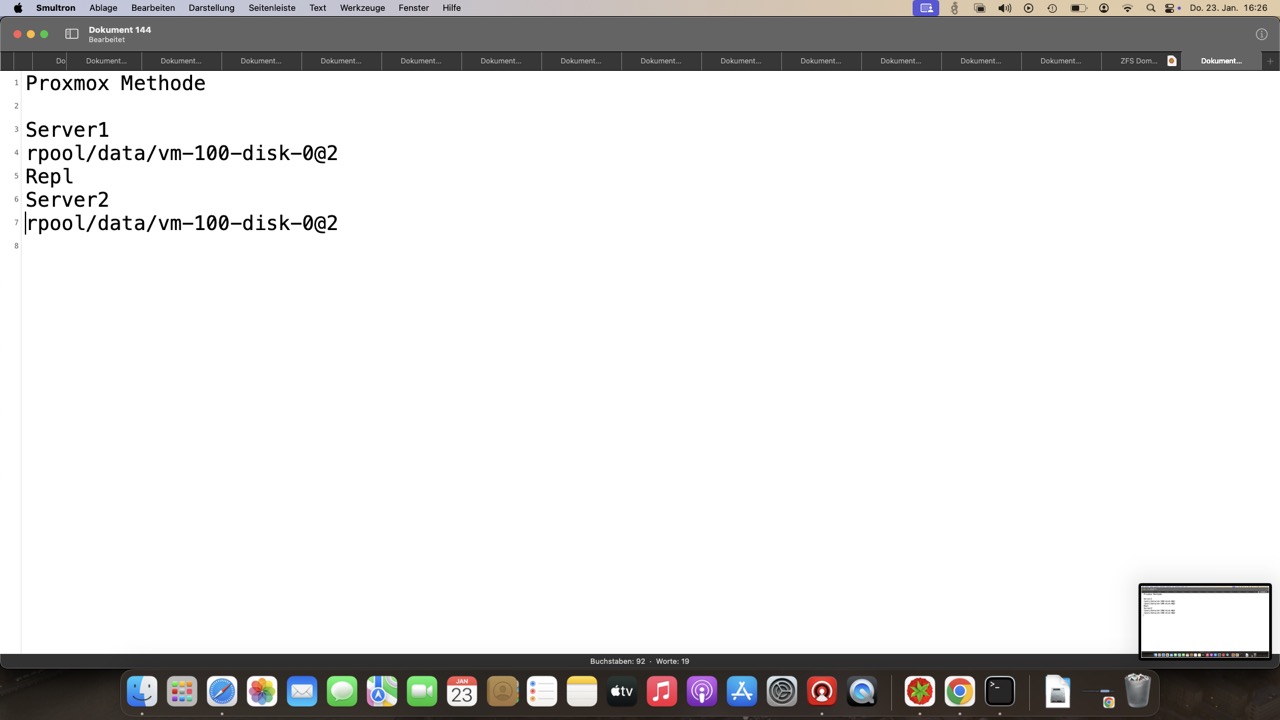
Proxmox baut selbst keine Notfallpunkte auf und nutzt ZFS nur als Transport, nimmt jedoch manuelle und automatisierte Snapshots mit, auch von Z-A-S!
Weitere Kopien per ZFS sind nur per Pushverfahren möglich, was ideal für Angreifer ist wenn sie alles löschen möchten. Ein Backupserver ist hier unverzichtbar, bei Pullreplikation gehts ggf. auch ohne. Außer Haus ist es nicht möglich ein ZFS Replikat zu senden, da sich der Partner im lokalen Cluster befinden muss!
Nondestruktiver Rollback nach Trojanerbefallt bei Forensikbedarf
OPNsense Migration Legacy zu Instance, ohne neues Ausrollen von Konfigurationen
Sicher habt ihr schon die Meldung der OPNsense Firewall unter OpenVPN / Legacy gesehen
This component is reaching the end of the line, official maintenance will end as of version 26.1
Die Migration zur Instanz ist nicht sonderlich kompliziert, jedoch gibt es zwei Fallstricke.
- Deaktiviert den alten Server
- Falls Shared Key verwendet wurde, unter Static Key diesen Text übernehmen, Mode Auth
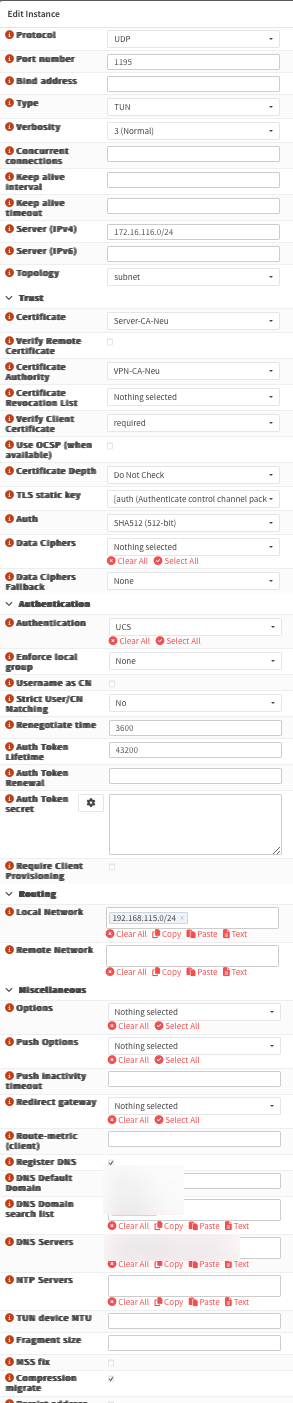
- Konfiguriert eure neue Instanz mit mindestens diesen Einstellungen
- Role: Server
- Enabled: yes
- Port Number: wie bisher, z. B. 1194
- Type: TUN
- Server IP: Hier den alten Wert von IPv4 Tunnel Network übernehmen, z. B. 172.16.1.0/24
- Toplolgy: subnet
- Certificate: hier den alten Eintrag von Server Certificate übernehmen
- Certificate Authority: hier den alten Eintrag von Peer Certificate Authority übernehmen
- Dann links oben Advanced Mode einblenden
- Unter TLS static key den vorher angelegten Key auswählen
- Auth: den alten Wert von Auth Digest Algorithm übernehmen, z. B. SHA256
- Autentication: den vorherigen Serveranbieten, z. B. DC, UCS, Zamba auswählen, wenn vorhanden
- Renegotiate Time: 3600
- Auth Token Lifetime: 43200
- Local Network: den alten Wert von IPv4 Local Network auswählen
- Falls vorher bei Compression etwas ausgewählt war, selbst Disabled, dann Compression migrate unter Advanced anklicken
- Weitere Parameter falls benötigt
Der technische Stand dieser Dokumentation ist von April 2025 und funktioniert mit der Version OPNsense 25.1.4_1-amd64.
Die Business Edition 24.10 verfügt noch nicht über den Compression Migrate. Daher muss die Version Business 25.x abgewartet werden!
Beispiel
cz
Backup und Replikation trojanersicher für Proxmox VE mit Miyagi Workflow
Was wir uns Wünschen
Für eine Datensicherung wünschen wir uns drei Kopien der Daten an mindestens zwei Standorten, mit zwei Methoden.
Zusätzlich ist die Kontrolle ohne Fehlerquote ein Muss!
Unsere Lösung erzeugt auf einem oder mehreren Systemen
- Natives Proxmox Backup ohne Löschmöglichkeit auf der Quelle (Restoreversprechen)
- Natives ZFS Replikat (Restoregarantie)
- Lückenloses Monitoring ohne Fehlerquote oder Aufwand
- Serialisierung der Sicherungen für bessere Leistung
- Automatisierung von Updates, Backupwartung und -verifizierung und Herunterfahren des Sicherungsservers
- Zentrales Dashboard für Funktion und Sicherung aller Systeme
- Schnelle Wiederherstellung durch Proxmox Backupserver oder Starten von replizierten Systemen
Als Ergebnis finden wir eine Backuphistorie für mehrere Monate bis Jahre und Replikate von ca. 14 Tagen bis drei Monate

# Auf dem Zielserver sollte das dann so aussehen
# Unsere Proxmox Backups mit fünf Tagen Snapshot gegen Kompromittierung
zfs list
rpool/pbsstore 4.9T 30.4T 4.62T /rpool/pbsstore
#PVE mit LXC Container
rpool/repl/lwpve2/rpool/data/subvol-100-disk-0 168G 34.8G 165G /rpool/repl/lwpve2/rpool/data/subvol-100-disk-0
rpool/repl/lwpve2/rpool/data/subvol-102-disk-0 918M 31.1G 872M /rpool/repl/lwpve2/rpool/data/subvol-102-disk-0
#PVE mit KVM
rpool/repl/lwpve3/rpool3/data/vm-301-disk-0 267K 41.0T 169K - (finden sich unter /dev/zvol/rpool....)
rpool/repl/lwpve3/rpool3/data/vm-301-disk-1 40.6G 41.0T 26.7G - (finden sich unter /dev/zvol/rpool....)
rpool/repl/lwpve3/rpool3/data/vm-301-disk-2 277G 41.0T 214G - (finden sich unter /dev/zvol/rpool....)
Die Backups benötigen für die Wiederherstellung den Zeitpunkt, den Platz und Zeit, während die ZFS Replikate sofort Startfähig sind und in Potenter Hardware produktiv gehen können.
Die Aufhebezeiten für Backups und Replikaten können selbst festgelegt werden.
Überlegungen zu Proxmox VE
Proxmox VE ist primär nur ein überschaubares Frontend für KVM und LXC Virtualisierung.
Es ist natürlich denkbar alte VMware- und HyperV Lösungen auf Proxmox umzustellen.
Nutzt man Proxmox mit Hardware Raid oder SAN, verliert man im Vergleich zu den kommerziellen Lösungen eine Menge Komfort.
Natürlich ist die Hochverfügbarkeit und das schlanke Design ein Gewinn im Vergleich zu den kostenintensiven Lösungen des Mittbewerbs.
Proxmox lebt vor allem durch die im Hintergrund integrierten Lösungen KVM, LXC, SDN und vor allem ZFS und Ceph.
ZFS und Ceph schicken Hardware Raids und SANs auf die Ersatzbank und sind nunmehr oft obsolet.
Lösungen mit Ceph werden primär eingesetzt wenn im Härtefall kein Bit Daten verloren gehen darf, was allerdings mit einem vier- bis sechsfachen Kostenaufwand einhergeht.
Mit ZFS erreicht man realistisch eine Sicherung unter fünf Minuten oder besser, wenn notwendig. Nur weil bei einem Server das Licht ausgeht, sind noch lange die Daten nicht weg!!!
Bei eher nicht zu erwartenden Problemen mit einem Ceph Cluster müsste man eventuell von vorne starten.
Kleinere Installationen von ca. ein bis drei Proxmox Servern sollten daher mit ZFS installiert und untereinander repliziert werden.
Die Replikation mit Bordmitteln sieht jedoch nur den Transport und keine Historie der Systeme vor.
Da heutzutage SSDs und Festplatten nicht mehr von vorne bis hinten beschrieben werden, sondern zufällig, macht es Sinn die komplette Lebenszeit den kompletten Platz auszunutzen.
Von Dummheit, Fahrlässigkeit bis zum Trojaner
Vor Umstellungen und Maßnahmen führt der Admin üblicherweise einen Snapshot aus. Gerade VMware ist die absolut im Nachteil gegen die meisten Systeme, da Konsolidierung der Snapshots nach Tagen schon den Betrieb lahmlegen kann. Daher ist eine hohe Anzahl von Snapshots im HyperV und VMware keine Option.
Hier kommt ZFS ins Spiel.
Durch die auf Vektoren basierende Arbeitsweise von ZFS sind permanente Snapshots kein Nachteil für den Betrieb.
Wir empfehlen folgende Vorgehensweise.
Installation einer Snapshot Engine wie zfs-auto-snapshot oder CV4PVE (Web GUI für PVE)
Alle Programme inklusive Proxmox VE erstellen dieselbe Qualität an Snapshots, wobei zfs-auto-snapshot von Proxmox unentdeckt arbeitet.
Hierbei ist nur zu beachten, dass das System nicht über 80% belegt wird. Für den Fall der Überlastung können wir die Aufhebezeiten reduzieren.
Unser Vorschlag belegt üblicherweise ca. 2,5 mal so viel Platz wie die Nutzdaten.
Hier die optimalen Einstellungen aus unserer Praxis:
- 12 Snapshots alle 15 Minuten für drei Stunden für schnelle Hilfe
- 96 Stunden für vier Tage, besonders sinnvoll für Ostern, Weihnachten, Krankheit
- 21 Tage für drei Wochen
- 6 Wochen für ein feineres Raster in die Vergangenheit
- 3 Monate für unentdeckte Fehler
Für alles über drei Monate nutzen wir die tägliche Sicherung mit Proxmox Backup Server
Proxmox Backupserver Segen und Fluch
Proxmox Backup Server ist ein ideales Sicherungswerkzeug für virtuelle Maschinen und Linux Container auf Proxmox VE.
Das Design sieht vor daß hier Sicherungen von Proxmox VE nach Proxmox Backupserver geschoben werden, was Raum für Trojaner und Hacker bietet.
Es ist extrem wichtig, dem Backupuser im Server einen API Key bereitzustellen, der nur Sicherungs- und Widerherstellungsrechte besitzt.
Zwei Faktor Login, so wie die Deaktivierung des SSH Logins per Passwort sind absolut notwendig!
Der Backupserver kann nicht wissen wann ein Proxmox VE System seine Sicherung anliefert. Daher muss er permanent laufen.
Selbst ein Anschalten des Backupservers vor der geplanten Sicherung erlaubt ein Herunterfahren nach der Sicherung nicht, da es technisch nicht vorgesehen ist.
Ebenfalls ist das Monitoring der Backups nicht vorgesehen und mit Zabbix oder Check_MK nur mühselig einzurichten.
Die Mailbenachrichtigung ist unzureichend bis unbrauchbar. Ebenfalls fehlt ein Dashboard für Backup, Festplattenzustand oder Raid-Probleme.
Wir benötigen einen weiteren Computer, an einem anderen Ort, mit zwei weiteren Kopien in zwei Methoden der Sicherung
Proxmox VE bietet die Möglichkeit nativ mit dem Backupserver zu sichern und mit ZFS ein startfähiges Replikat nativ zu erstellen.
Backups bieten hier ein Wiederherstellungsversprechen, während ZFS eine Wiederherstellungsgarantie bietet
Voraussetzungen für den Miyagi Workflow
- Proxmox VE Server 8.4 oder neuer mit ZFS Raid 10 (empfohlen) oder RaidZ (langsamer)
- Optional zfs-auto-snapshot oder CV4PVE Snapshotmanager
- Computer mit möglichst viel Platz, z. B. HPE Microserver mit ECC, 4 x 20TB HDD oder vergleichbare Systeme von Terramaster ohne ECC mit 16 GB RAM (nicht empfohlen)
- Proxmox Backup Server 3.4 oder neuere ISO zur Installation mit ZFS Raid 10 (empfohlen) oder RaidZ (langsamer)
- Optional alter PC mit Synology iSCSI Freigabe
- Dafür Cronjob beim booten
- @reboot iscsiadm --mode node --targetname "iqn.2xxxx" --portal "10.ipsyn...:3260" --login && zpool import -f iscsi
- @reboot iscsiadm --mode node --targetname "iqn.2xxxx" --portal "10.ipsyn...:3260" --login && zpool import -f iscsi
- Bashclub Postinstaller für checkzfs und zsync Tool auf beiden Systemen https://github.com/bashclub/proxmox-zfs-postinstall
- Optional Check_MK Agent auf PVE und PBS
Installation Proxmox Backup und Einstellungen
- PBS: Inhalt von .ssh/id_rsa.pub wird per Web GUI in PVE .ssh/authorized_keys ergänzt
- Einmaliger Login per SSH von PBS zu PVE um den Hostkey zu speichern
- Konfiguration von PBS
- Kein NFS für PBS nutzen!!!
- Optional beim booten ein Synology oder ähnliches iSCSI LUN einbinden, falls keine neuen Platten angeschafft wurden
- Auf der Shell optimierten ZFS Pool und Dataset erstellen, falls nicht nativ installiert wurde
- Optional mit iSCSI
- iscsiadm --mode node --targetname "iqn.2xxxx" --portal "10.ipsyn...:3260" --login
- iscsiadm --mode node --targetname "iqn.2xxxx" --portal "10.ipsyn...:3260" --login
- Bei direkten Platten Raid erstellen
- zpool create -f iscsi /dev/sdx -o autoexpand=on
- zfs create iscsi/pbsstore -o recordsize=1M -o com.sun:auto-snapshot=false
- mit lsblk finden wir die Festplatten namen, alternativ unter /dev/disk/by-id (empfohlen=
- Optional mit iSCSI
- Bei nativ installiertem PBS wie folgt den Store anlegen
- zfs create rpool/pbsstore -o recordsize=1M -o com.sun:auto-snapshot=false
- In Proxmox Backupserver neuen Store anlegen
-
- bei iSCSi nach /iSCSI/pbsstore
- nativ nach /rpool/pbsstore
- Purge, Garbage Collegtion und Verifyjobs anlegen auf 1. Tag im Jahr und deaktivieren, wir regeln das!
- Benutzer backup@pbs mit guten Passwort und 2FA anlegen
- API Key backup@pbs!backup anlegen, Passwort und Name notieren
- Permission für "/" Datastore Backup für User backup@pbs und API Key backup@pbs!backup anlegen.
-
- In Proxmox VE, also der Quelle
- Neuen Datastore Typ Proxmox Backup Server

- Ausführung eines Tests der Datensicherung direkt aus einer VM
- Neuen Datastore Typ Proxmox Backup Server
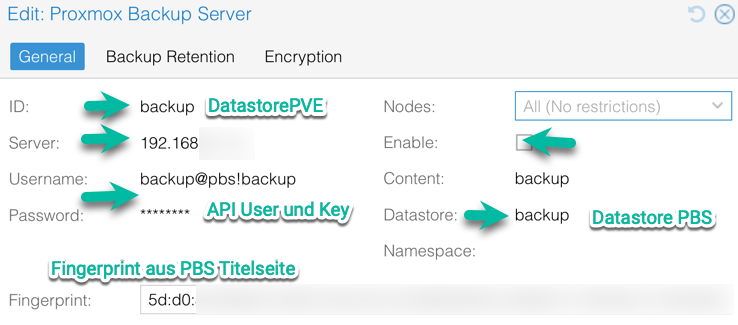
Achtung: Proxmox VE hat als default den Store "local" auf Typ Backup stehen, dringend deaktivieren!
Installation Miyagi
- Auf Proxmox Backupserver
- apt install git open-iscsi
-
git clone -b dev https://github.com/bashclub/miyagi-pbs-zfs.git cd miyagi-pbs-zfs cp config.example ipdeinespve.conf nano ipdeinespve.conf - Miyagi Script sichert einen PVE mit maximal zwei ZFS Pools auf ein Ziel, für mehr einfach mehrere Configs!
-
SSHPORT='22' #SSH Port, eventuell extern geändert BACKUPSERVER=yes #Soll Backup ausgeführt werden MAINTDAY=6 #1 Montag bis 7 Sonntag, am besten Samstags, da Sonntags Scrubs laufen SHUTDOWN=yes #Ausschalten nach Beendigung (empfohlen) UPDATES=yes #Updates PBS SOURCEHOST='dein pve ip' # IP vom Proxmox VE System das gesichert werden soll #Replikation mit ZFS ZFSROOT='rpool/data' Standard ZFS Pool von Proxmox VE mit ZFS ZFSSECOND='rpool-hdd/data' #Optional zweites ZFS auf HDD ZFSTRGT='rpool/repl' #Das ist der Proxmox Backup Server mit ZFS installiert #Falls Sonntags der ZFS Scrub läuft, besser stoppen ZPOOLSRC=rpool #Erster Pool PVE ZPOOLDST=rpool #Erster Pool PBS #ZSYNC für ZFS Replication vom github.com/bashclub ZPUSHTAG=bashclub:zsync #Markiert auf der Quelle mit diesem Wert rekursiv die Datasets und Volumes ZPUSHMINKEEP=3 #Standardwert zum Anfügen, nicht ändern ZPUSHKEEP=14 #Bei täglicher Sicherung wären das 14 Tage! ZPUSHLABEL=zsync #Name vom Snapshot für die Replikation, dieser muss auf beiden Seiten erscheinen ZPUSHFILTER="daily,weekly,monthly" #Falls zfs-auto-snapshot auf Quelle genutzt wird, können wir diese Snapshots mitnehmen! #Backup PBSHOST='IPPBS' #IP Adresse des Proxmox Backup Servers BACKUPSTORE=backup #Datastorename für Backups auf PVE BACKUPSTOREPBS=backup #Datastorename für Backups auf PBS BACKUPEXCLUDE='99999' #Weglassen von VMs oder LXCs mit Komma getrennt, nicht leer lassen! - Danach Testlauf
- /root/miyagi-pbs-zfs/pbs-zfs-daily.sh -c /root/miyagi-pbs-zfs/192....conf
- Ausgabe sollte Replikation und später Backup anzeigen
- Shutdown
- Kontrolle Testlauf
- PBS-Sicherung
- In Proxmox VE unter Cluster / Datastores den Backup Store wieder aktivieren!
- In den VMs/LXCs oder im Store selbst schauen ob Backups vorhanden sind
- ZFS-Replikation
-
- auf PBS in Shell
- checkzfs --sourceonly
- oder
checkzfs --source ippve --filter rpool/data --threshold 1500,2000 -- columns +message
- auf PVE in Shell
-
cat /var/lib/check_mk_agent/spool/*
-
- auf PBS in Shell
-
- Check_MK Monitoring
- Auf PVE per Service Discovery
- Service Discovery abwarten oder starten

Zeigt den Status des letzten Backups-

Zeigt alle Quelldatasets und -Volumes ohne Fehlerquote, wenn Quelle korrekt angegeben
Status geht auf Unknown wenn innerhalb eines Tages keine neuen Daten kommen!
- Service Discovery abwarten oder starten
- Ausgeschalteten Miyagi Server kontrollieren
- Neuen Host mit Namen miyagi-quelle-ziel in Check_MK anlegen, ohne Agent und API, mit

- Service Discovery abwarten oder starten

-
Nun können wir den ausgeschalteten Server im Blick behalten. Kommen innerhalb eines Tages keine neuen Daten, geht das System auf Unknown
- Auf PVE per Service Discovery
- PBS-Sicherung

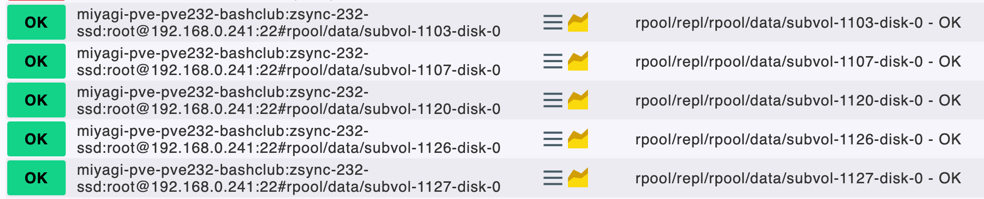

Migration Univention Corporate Server & Kopano nach Zamba AD & Mailcow
Nachdem viele kleinere Kunden nur den Domaincontroller benötigen, jedoch UCS + Kopano für den Betrieb nutzen, kann UCS bei vielen Kunden nun ersetzt werden.
Das Upgrade auf UCS 5.2 zeigt erneut, dass sich der Aufwand eines Upgrades nicht mehr mit dem Nutzen eines Domaincontrollers rechnet.
Updates von Mailcow und Zamba AD Controller laufen künftig in wenigen Minuten, nicht mehrere Stunden
Kunden die Keycloak und eine supportete Umgebung wünschen bleiben bitte bei Univention!!!
Entsprechende Kurse finden Sie auf cloudistboese.de unter Mailcow und Domaincoltroller ablösen!
Systemvoraussetzungen
- Bestehender Univention Corporate Server im AD Modus
- Kopano oder vergleichbare Groupware mit IMAP
- Proxmox VE >8.x mit Linux Container mit installiertem GIT
Installation zweiter Domaincontroller
Installation auf Proxmox im z. B. /root Ordner
git clone -b dev https://github.com/bashclub/zamba-lxc-toolbox
cd zamba-lxc-toolbox
cp conf/zamba.conf.example conf/zamba.conf
In der zamba.conf folgende Parameter an das System anpassen
LXC_TEMPLATE_STORAGE="local" #LXC Template Store
LXC_ROOTFS_SIZE="32" #DCs Root Size
LXC_ROOTFS_STORAGE="rpool-data" #or local-zfs #DCs Root Store
LXC_SHAREFS_SIZE="100" #DCs Root Backup Size
LXC_SHAREFS_STORAGE="rpool-data" #or local-zfs #DCs Backup Store
LXC_HOSTNAME="zmb-ad"
LXC_DOMAIN="windomain.local"
LXC_IP="10.0.0.254/24"
LXC_GW="10.0.0.1"
LXC_DNS="10.0.0.4" #your old UCS IP, If Windows Step Down to Level 2008R2 first!
LXC_BRIDGE="vmbr0"
LXC_PWD='Admin123'
ZMB_REALM="WINDOMAIN.LOCAL"
ZMB_DOMAIN="WINDOMAIN"
ZMB_ADMIN_USER="administrator"
ZMB_ADMIN_PASS='Admin123'
Die installation des LXCs als zweiten DC starten wir mit
bash install.sh -i 100 #für Container 100
Im Menü wählen wir Zamba-AD-Join
Nach der Installation können wir in den Container gelangen mit
pct enter 100
su -
wbinfo -u
wbinfo -g
Empfehlung: In Proxmox den alten UCS DNS Server entfernen
Dort Finden wir im Idealfall alle User und Gruppen, was den Erfolg bestätigt
Folgende Anpassung in der smb.conf macht das Leben leichter
vi /etc/samba/smb.conf
[global]
ldap server require strong auth = no
dns forwarder = 1.1.1.1 1.0.0.1
It was DNS
An dieser Stelle erhalten alle Computer mit festen IPs den neuen DNS-Server, der alte DNS Server vom UCS kann jetzt raus.
Im DHCP Server ersetzen wir ebenfalls den DNS Server mit dem neuen DC, der alte DNS Server vom UCS kann raus
Installation Mailcow
vi conf/zamba.conf.example conf/zamba.conf
Die Installation der Mailcow benötigt keine spezielle Anpassung im unteren Bereich außer dem LXC_HOSTNAME und den Netzwerkeinstellungen
bash install.sh -i 101 #für Container 101
Im Menü wählen wir Mailcow
Nach der Installation von Mailcow
pct enter 100
su -
cd /opt/mailcow-dockerized
apt install jq
./update.sh
Danach rufen wir das Mailcow Webinterface mit der Admin Seite auf
Folgende Schritte sind unerlässlich
- Admin Passwort ändern - System / Konfiguration / Administrator bearbeiten
- Alle Domänen eintragen und Schwellwerte beachten! - E-Mail / Konfiguration / Domains
- Benutzer in der AD anlegen, z. B. bind-mailcow - Windows Active Directory und Benutzer oder UMC
- LDAP in Mailcow konfigurieren - System / Konfiguration / Zugang / Identity Provider
- Identity Provider: LDAP
- Host: IP neue ZMB-AD
- Port: 636 (Active Directory)
- Benutze SSL: an
- Ignoriere SSL Fehler: an
- Base DN: CN=Users,DC=windomain,DC=local
- Username Feld: mail
- Attribute Feld: mail
- Bind DN: CN=bind-mailcow,CN=Users,DC=windomain,DC=local
- Bind Passwort: wurde oben angelegt
- Attribute Mapping / Standardvorlage / Default
-
Benutzer beim Login erstellen: an
-
Vollsynchronisation: an
-
Importiere Benutzer: an
-
Sync / Import interval (min): 1 (für den Anfang)
- Erfolg Kontrollieren - Mailboxen Mailbox
- Mails Synchronisieren - E-Mail / Synchronisationen / Neuen Sync Job erstellen
- Host: IP Kopano
- Port 993
- Benutzername: Windows Login name
- Elemente ausschließen (Regex) Inhalt entfernen, zu gefährlich
- Lösche Duplikate im Ziel (--delete2duplicates) nur so lange die Mails noch auf Kopano laufen, danach raus!
-
Kopano hat per default IMAP deaktiviert, daher ggf. in der server.conf mal nach disable suchen
oder
In UMC im User unter Kopano IMAP aktivieren (Aktiviere Kopano Funktionen) - Erfolg der Synchronisation im Dialog und dessen Logs kontrollieren
- Kalendereinträge der Benutzter exportieren
-
http://kopano:8080/caldav/<user>/<f older-name>/Calendar/task folder in user’s store. Make sure the calendar/task folder already exists. http://kopano:8080/caldav/<user>/<s ub-folder>/Self created subcalendar in the user’s own store. Location through actual subfolders in Zarafa is irrelevant. http://kopano:8080/caldav/<other-us er>/<folder-name>/Shared calendar/task folder of other user http://kopano:8080/caldav/public/<f oldername>/Calendar/task folder in the public folder http://kopano:8080/caldav/<user>/Default calendar of the current user. Although this works for most clients, this URL is not recommended. - Die exportierten Dateien können im Mailcow SoGo Frontend oder Mailclient direkt importiert werden
-
- Export Kontakte
- geht über alten Mailclient, da dein Carddav Server vorhanden
- Python Script mit MAPi
Dieses Script exportiert alle Kontakte in Unterordner pro User, da kein Card DAV in Kopano steckt
-
sudo apt install python3-kopano
mkdir export
wget https://raw.githubusercontent.com/bashclub/trmm-scripts/refs/heads/main/kopano-export-contacts.py
python3 kopano-export-contacts.py
-
- Import Kontakte
- Outlook hatte mit dem Export Probleme und der Verarbeitung, sprich Daten fehlten
- SOGO importiert Kontakte nur einzeln
- EM-Client war am Ende die beste Wahl für den Import der .VCF Dateien am Stück per Drag&Drop
- Anbindung des EM-Client für Import oder Nutzung
- https://kunde.dyndns.org/SOGo/dav/user@domain.de/Contacts/personal/
- Anbindung des EM-Client für Import oder Nutzung
- Aliase finden und anlegen
-
univention-ldapsearch -LLL | grep @ | grep mailAlternative
- Aliase eintragen - E-Mail -Aliasse / Alias hinzufügen
-
- Weiterleitungen finden
- univention-ldapsearch -LLL | grep mailForward # Listet Weiterleitungen
- Weiterleitung wird im SoGo Webfrontent unter E-Mail konfiguriert, nicht in Mailcow!!!
- Mailcow online stellen
- NAT Ports setzen, z. B. auf OPNsense als Alias
- p_mailcow 80 443 465 993 4190
- h_mailcow 10.0.0.253
- Port Forwarding
- any > WAN IP > p_mailcow > h_mailcow
- NAT Ports setzen, z. B. auf OPNsense als Alias
- Mailcow neu starten
pct enter 100
su -
rm /opt/mailcow-dockerized/data/conf/nginx/redirect.conf
cd /opt/mailcow-dockerized
docker compose down
# Optional bei PMG Einsatz greylisting aus
# vi /opt/mailcow-dockerized/data/conf/rspamd/local.d/greylist.conf
enabled = false;# Optional vi /opt/mailcow-dockerized/mailcow.conf
SKIP_LETS_ENCRYPT=n
SKIP_HTTP_VERIFICATION=y
docker compose up -d
- Kontrolle ob Letsencrypt HTTP Challenge funktioniert
-
docker compose logs --tail=200 -f acme-mailcow
-
- Alternativ eigenes Zertifikat unter
/opt/mailcow-dockerized/data/assets/ssl
- cert.pem
- key.pem
- DNS Werte beim Provider anpassen oder kontrollieren - E-Mail / Domains / DNS
Abschluss der Arbeiten
- Synchronisationen nach Erfolg deaktivieren
- Optional PMG auf Mailcow verweisen
- Alten Univention Corporate Server abschalten
- Takeover Active Directory
-
pct enter 100
-
su -
samba-tool fsmo transfer --role=all -Uadministrator
samba-tool domain demote --remove-other-dead-server=UCS
rm /etc/cron.d/sysvol-sync
-
- Bereinigung
- RSAT DNS Konsole nach alten Fragmenten durchsuchen und entfernen
- Optional Metadata Cleanup
- Anpassung von bestehenden an UCS angebundenen LDAP Clients
- Bind User pro Rolle anlegen, an keinen PC Anmelden wählen
- Dialog des LDAP Clients besuchen und folgende Werte ändern
- IP = neuer ZMB-AD
- Port 7389 zu 636 mit SSL
- UID zu sAMAccountName
- Bind DN uid zu cn ändern
Proxmox Mail Gateway
-
/opt/mailcow-dockerized/data/conf/rspamd/local.d/greylist.conf
-
enabled = false;
- docker compose restart rspamd-mailcow
-
- Konfiguration / Routing / Networks
- ipvompmg:26
- greylisting aus
- ipvompmg:26
- In allen Maildomains die PMG nutzen
- Senderabhängige Transport Maps
- ID 1: ipvompmg:26
- Im Proxmox Mail Gateway
- Configuration / Mailproxy
- Relay Domaoin
- Transport zur Mailcow, kein MX
- Configuration / Mailproxy
- Beim DNS Provider PMG Settings überschreiben teile den Mailcow Empfehlung
Mailpiler
- Identische Installation, siehe LXC Toolbox zuvor
- Empfang aus dem Archiv
- system / konfiguration / einstellungen / weiterleitungs-hosts
- ip vom Mailpiler eintragen
- system / konfiguration / einstellungen / weiterleitungs-hosts
- BCC an das Archiv
- system / konfiguration / routing / transport
- Ziel piler.windoimain.local
- Next Hop 10.0.0.x
- e-mail / konfiguration / adressumschreibung / bcc-maps
- mapping pro domain eintragen (1x eingehend, 1x ausgehend)
- pro Maildomäne Empfängerabhängig und Senderabhängig
- Lokales Ziel: sysops.tv
- BCC-Ziel piler@piler.windomain.local
- Domain: sysops.tv
- Lokales Ziel: sysops.tv
- pro Maildomäne Empfängerabhängig und Senderabhängig
- mapping pro domain eintragen (1x eingehend, 1x ausgehend)
- system / konfiguration / routing / transport
- Kontrolle im Mailpiler unter /var/log/mail.log
- LDAP Anpassung wäre in config-site.php im Piler möglich, jedoch nicht für Aliase!
Dubletten bei mehrfachem Kopano Sync
Leider ist die IMAP Kompatibilität bei Kopano eher auf der niedrigen Seite.
Finden sich etliche Mails offensichtlich doppelt oder dreifach, führt man den zweiten Befehlt auf der Kopanoseite mehrfach aus.
apt install kopano-migration-imap #identisch imapsync
kopano-migration-imap --delete2duplicates --host1 mailcowhost --host2 10.0.0.8 --user1 user@domain.de --password1 mailcowpassword --user2 user@domain.de --password2 mailcowpassword --ssl1 --ssl2 --dry # dry für Vorabtest
Virtuelle Maschine mit Windows 10 Bios auf Proxmox zu Windows 11 mit UEFI umstellen
Windows 11 Migration Bios zu UEFI
Win11 Upgrade BIOS -> UEFI ist keine einfache Aufgabe
Auch wenn es Workarounds gibt, möchten wir für virtuelle Windows 11 Maschinen die maximale Lebensspanne an Upgrades. Daher passen wir das System im Bereich Partitionstabelle, TPM und virtuelle Hardware an
Systemplatte erweitern
In Proxmox großzügig die Platte, wenn Thin Provisioning aktiviert ist, erweitern.
Danach die Partition in Windows vergrößern, da wir am Ende Platz für eine EFI Partition benötigen!
BCD neu schreiben
bcdboot c:\windows /s c: /f allWin Part als aktiv markieren
diskpart
select disk 0
select part 2
activeDisk zu GPT konvertieren
mbr2gpt.exe /convert /allowFullOS /disk:0VM Shutdown und neu konfigurieren

-
BIOS OVM (UEFI) # Bei VM Start mit ESC in die Einstellungen gehen und Secure Boot deaktivieren!
-
TPM 2.0 State hinzufügen
-
EFI Disk hinzufügen
-
Optional vorm ersten Boot alle Disks mit detach entfernen und mit IDE wieder hinzufügen, danach Bootreihenfolge nicht vergessen
-
Optional und empfohlen: virtio-iso mounten für aktuelle Treiber CD
VM einschalten
-
Bei VM Start mit ESC in die Einstellungen gehen und Secure Boot deaktivieren!
-
Wenn Inaccessible Boot Device, dann booten mit F8 unsignierten Treibern aktivieren
Shutdown
- Disks wieder auf SCSI stellen, wie oben beschrieben
VM Starten
- Windows 11 ISO einlegen
- Windows 11 Upgrade starten
Stand der Technik nach DSGVO am Beispiel Kopano - Was sagt ChatGPT?
Auf Nachfrage interessierte mich die Meinung von ChatGPT zum Thema Übergangsfristen für abgelaufene Software, wie z. B. Kopano u. Ä. Nicht immer schafft man rechtzeitig die Migration auf aktuelle Systeme, meist wegen der Absprachen und Termin- und Kostengespräche mit Kunden
Nach der Datenschutz-Grundverordnung (DSGVO) gibt es keine ausdrücklichen Übergangsfristen für die Pflicht, Serversoftware auf dem Stand der Technik zu halten. Die Verordnung trat am 25. Mai 2018 in Kraft und gilt seither unmittelbar in allen EU-Mitgliedstaaten.
Was bedeutet "Stand der Technik" laut DSGVO?
Die DSGVO verlangt in Art. 32 Abs. 1 von Verantwortlichen und Auftragsverarbeitern geeignete technische und organisatorische Maßnahmen, um ein dem Risiko angemessenes Schutzniveau zu gewährleisten. Dabei ist „der Stand der Technik“ ein zentrales Kriterium.
Das bedeutet konkret:
-
Sicherheitslücken in Server- oder Anwendungssoftware müssen zeitnah geschlossen werden.
-
Der Einsatz nicht mehr unterstützter oder veralteter Software (z. B. alte PHP-Versionen, Windows 7, EOL-Linux-Distributionen) ist nicht zulässig, wenn dadurch Sicherheitsrisiken entstehen.
Gibt es trotzdem Spielräume oder Fristen?
Zwar gibt es keine festen Fristen in der DSGVO, aber:
-
In der Praxis kann bei Updates oder Umstellungen ein kurzer Zeitraum zur Umsetzung toleriert werden – solange ein Risikoanalyse- und Migrationsplan dokumentiert ist.
-
Bei Audits oder Vorfällen ist entscheidend, ob du als Verantwortlicher:
-
Risiken erkannt hast,
-
Maßnahmen geplant und priorisiert hast,
-
dokumentieren kannst, warum du etwas wie schnell umgesetzt hast.
-
Beispiele:
| Software | Stand der Technik? | Kommentar |
|---|---|---|
| Ubuntu 20.04 | Ja (bis 2025) | Unterstützt, wenn regelmäßig aktualisiert |
| Windows Server 2012 R2 | Nein (EOL) | Nicht mehr sicher, nicht DSGVO-konform |
| Apache 2.2 | Nein | Veraltet, seit Jahren nicht mehr unterstützt |
| Nextcloud (aktuelle LTS-Version) | Ja | Regelmäßige Updates, DSGVO-konform |
Fazit:
-
Keine Übergangsfristen – aber Planung und dokumentierte Risikobewertung sind wichtig.
-
Veraltete Software = hohes Bußgeldrisiko bei Datenschutzverstößen.
-
IT-Sicherheitsrichtlinien (z. B. vom BSI oder ISO 27001) helfen bei der Definition des „Stands der Technik“.
Wenn du willst, kann ich dir eine Checkliste zur DSGVO-konformen Server-Softwarepflege erstellen.
Das Problem mit Kopano Groupware unter Univention Corporate Server (UCS) 5.0 liegt mittelfristig vor allem beim Thema "Stand der Technik" im Sinne der DSGVO – insbesondere in Bezug auf:
🔧 1. Veraltete Softwarebasis von Kopano
-
Kopano Core (insbesondere
kopano-server,kopano-webapp,kopano-spoolerusw.) wird seit längerer Zeit kaum weiterentwickelt. -
Sicherheits- und Bugfix-Updates erscheinen selten oder gar nicht mehr regelmäßig.
-
Einige Komponenten (z. B.
kopano-webmeetings,kopano-dagent,kopano-z-push) sind teilweise nicht mehr kompatibel mit aktuellen PHP-Versionen, was ein Sicherheitsrisiko darstellt.
➡️ Risiko: Wenn Sicherheitslücken bekannt werden und keine Updates folgen, ist der „Stand der Technik“ nicht mehr gegeben.
📦 2. Eingeschränkte oder fehlende Wartung im UCS App Center
-
Kopano war lange im UCS App Center verfügbar, wurde aber teilweise nicht mehr aktiv gepflegt.
-
Mit der Umstellung auf UCS 5.0 wurden viele Altpakete nicht migriert oder sind nur mit manuellem Aufwand nutzbar.
-
Kopano4UCS, ein Community-Projekt, hat zwar Lösungen bereitgestellt, diese gelten nicht als offizieller Supportpfad.
➡️ Risiko: Kein garantierter Support, keine klare Roadmap, und Integration in UCS nur noch teilweise gepflegt.
🔒 3. Unklare Sicherheitsgarantie & Datenschutzfolgeabschätzung
-
Nach DSGVO musst du jederzeit nachweisen können, dass deine Systeme sicher sind.
-
Bei Kopano ist eine fundierte Datenschutzfolgeabschätzung (DSFA) kaum möglich, wenn:
-
keine Sicherheitsupdates veröffentlicht werden,
-
unklar ist, wie Daten verschlüsselt übertragen oder gespeichert werden,
-
keine aktuellen Dokumentationen verfügbar sind.
-
➡️ Risiko: Du trägst die volle Haftung bei Datenpannen – auch wenn die Ursache eine nicht gewartete Drittsoftware ist.
📆 4. Abhängigkeit von veralteten Komponenten
-
PHP, MariaDB/MySQL, Apache-Versionen, auf die Kopano setzt, sind oft nicht mehr im Mainstream-Support.
-
Anpassungen an moderne Umgebungen (z. B. systemd, PHP 8.2+, OpenLDAP unter UCS 5.0) erfolgen nicht zuverlässig.
➡️ Risiko: Du bleibst auf alten Softwareständen – was DSGVO-widrig ist.
✅ Fazit: Wo ist mittelfristig das Problem?
| Bereich | Risiko | DSGVO-Auswirkung |
|---|---|---|
| Sicherheitspatches fehlen | Hoch | Kein „Stand der Technik“ |
| Keine Updates über App Center | Mittel | Wartung erschwert |
| Keine klare Produkt-Roadmap | Hoch | Planbarkeit & DSFA unmöglich |
| Technische Abhängigkeiten | Mittel bis hoch | Zunehmende Inkompatibilität |
🔄 Empfehlung
Wenn du Kopano (noch) nutzt:
-
Erstelle eine Risikoanalyse und dokumentiere die Abhängigkeit.
-
Plane mittelfristig die Migration (z. B. auf Open-Xchange, EGroupware, Nextcloud Groupware + Mailcow).
-
Prüfe Alternativen mit aktivem Hersteller-Support und Sicherheitszertifizierungen.
Wenn du möchtest, kann ich dir eine Migrations-Checkliste oder Alternativen zu Kopano unter UCS zusammenstellen.
Information zur Sicherung und Wiederherstellung von Windows 10/11-Systemen
Information zur Sicherung und Wiederherstellung von Windows 10/11-Systemen
Bitte nehmt zur Kenntnis, dass die Sicherung und der Ersatz (z. B. Austausch der Hardware) eines Windows 10- oder Windows 11-PCs inzwischen sehr problematisch sein kann.
Hintergrund
Neue Windows 11-Systeme verschlüsseln die Festplatte standardmäßig.
Der Verschlüsselungsschlüssel ist dabei an die Hardware (Trusted Platform Module, TPM) gebunden.
Das bedeutet:
-
Beim Umbau der Festplatte oder bei einer Wiederherstellung auf einem neuen PC (z. B. über URBackup) kann das System nicht entschlüsselt werden.
-
Diese Basisverschlüsselung ist ohne die ursprüngliche Hardware nicht aufhebbar (Stand heute).
Mögliche Vorgehensweisen
1. Kein Bedarf an Verschlüsselung (z. B. PC steht in verschlossenen Räumen)
-
Prüfen, ob eine Verschlüsselung aktiv ist:
-
Deaktivieren der Verschlüsselung:
-
Alternative: Falls Verschlüsselung gewünscht ist → BitLocker über Einstellungen → System → Speicher → BitLocker aktivieren und den Wiederherstellungsschlüssel sicher aufbewahren.
2. Bedarf an Verschlüsselung (z. B. bei mobilen Geräten)
-
Prüfung wie oben:
-
Diese Verschlüsselung ist an die jeweilige Hardware gebunden.
-
Empfehlung: BitLocker aktivieren und den Wiederherstellungsschlüssel unbedingt sichern.
→ Nur mit diesem Schlüssel ist eine vollständige Wiederherstellung möglich.
3. Zentrale Sicherung der BitLocker-Schlüssel über Gruppenrichtlinie (GPO)
In einer Active-Directory-Umgebung können BitLocker-Wiederherstellungsschlüssel automatisch im AD gespeichert werden.
Dies ermöglicht eine zentrale Verwaltung und Wiederherstellung der Schlüssel, auch wenn ein Benutzer den lokalen Key verliert.
Einrichtung (Kurzfassung):
-
GPO öffnen →
Computerkonfiguration → Administrative Vorlagen → Windows-Komponenten → BitLocker-Laufwerkverschlüsselung -
Unter Betriebssystemlaufwerke Richtlinie aktivieren:
„Wiederherstellungsinformationen in Active Directory Domain Services speichern“ -
Optional: Speicherung erzwingen, bevor Verschlüsselung beginnt.
-
Anwendung prüfen mit
gpupdate /force.
Hinweis: In Azure AD-Umgebungen werden die Schlüssel standardmäßig im Benutzerkonto im Azure-Portal hinterlegt.
Hinweise zur Datensicherung
-
Plattensicherung (Image-Backup): Wiederherstellung nur mit vorhandenem Schlüssel möglich.
-
Dateisicherung: z. B. mit URBackup oder ähnlichen Tools.
-
Proxmox Backup Server: Rücksicherung ist nur komplett möglich, da einzelne Dateien aus verschlüsselten Systemen nicht direkt extrahiert werden können.
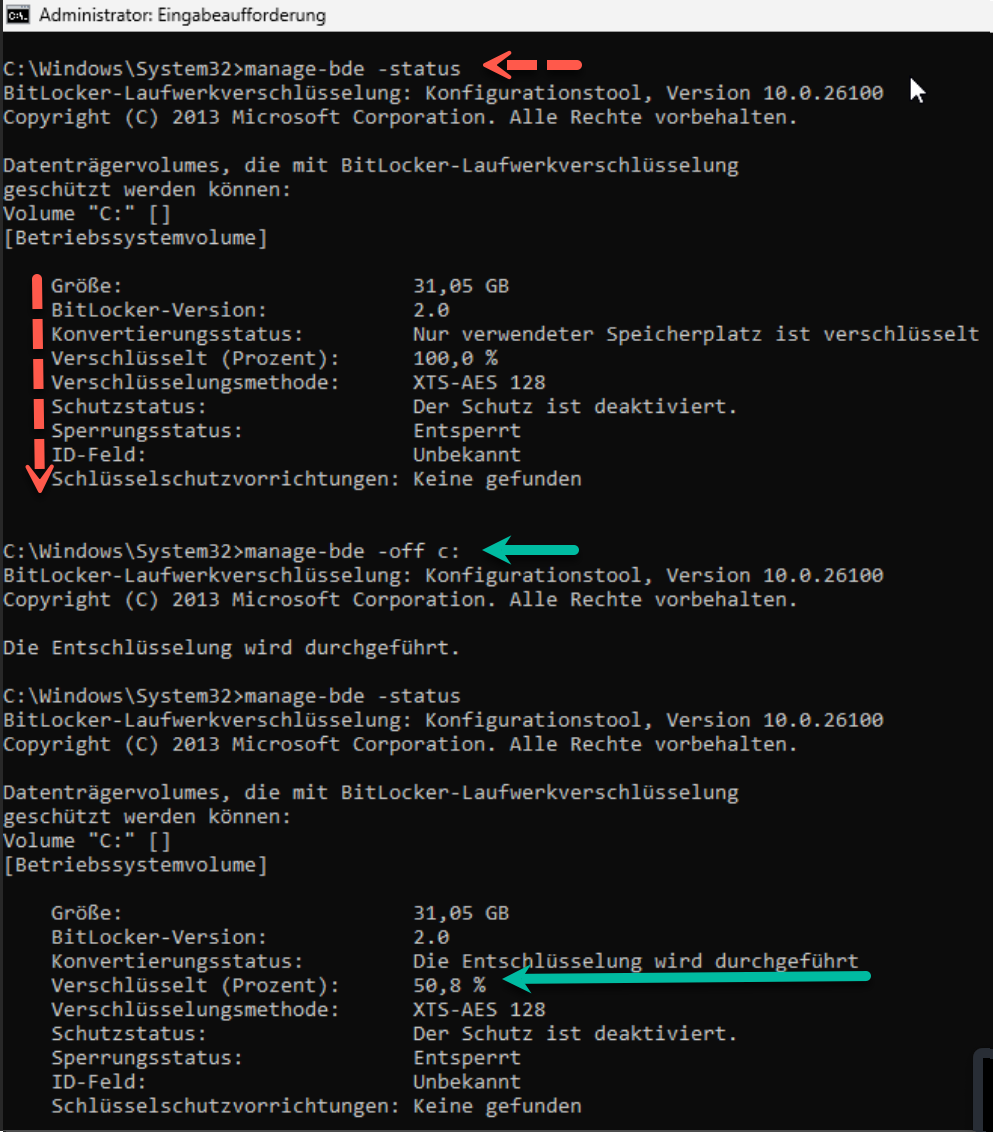
ZFS Grundlagen am Beispiel Proxmox VE(Stand Dezember 2025)
Der Verfasser des Artikels, Christian-Peter Zengel, hat zum Zeitpunkt des Artikels ca 18 Jahre Erfahrung mit ZFS und Proxmox. Er betreibt aktuell ca 150 Systeme mit Proxmox und ZFS
Das Einsatzgebiet geht von Standaloneinstallation bis zu ca 10 Hosts im Cluster. Es ist keine produktive Ceph Expertise vorhanden, jedoch wird intensiv an einer Hauslösung gearbeitet.
In der Praxis zeigt sich aber ZFS einfacher, vielseitiger, schneller und günstiger als CepH zu sein.
Dieser Dokumentation basiert auf diesem online Kurse von cloudistboese.de
24. + 26.11.2025 (13.00 Uhr bis 17.00 Uhr) - ZFS Grundlagen (Onlinekurs)
Diese Kurse sind ca alle sechs Monate online buchbar. Das Wiederholen der Onlinekurse, wie auch der Zugriff auf Aufzeichnungen sind kostenlos!

ZFS ist die perfekte Grundlage für kleine und mittlere Systeme um gegen Ausfälle, Dummheit anderer und Erpressungstrojanern ideal aufgestellt zu sein.
In diesem Kurs erhalten sie Grundkenntnisse für Systeme wie Proxmox, TrueNAS oder ähnliche Systeme.
Der Fokus liegt auf der Technologie und der permanenten Sicherheit im Umgang mit Daten, Linux und dem Terminal.
Themen:
- Begrifflichkeiten und Überblick
- Aufbau von Raids mit zpool
- Basisfunktionen am Beispiel von Proxmox VE
- Erklärung und Beispiele Snapshots und Rollbacks
- Praxisbeispiele Replikation
- Prüfung der Replikationen
- Weitere Features die das Leben massiv erleichtern
Nach diesem Kurs bist Du bei Ausfällen und Datenverlust vor dem Schlimmsten geschützt und in Minuten wieder produktiv!
Erstellung eines Raids mit zpool
So erstellt Proxmox VE seinen ZFS Raid
zpool create -f -o cachefile=none -o ashift=12 rpool mirror disk1 disk2
Destruktives Anlegen (-f), kein automatisches Importieren beim Start (-o cachefile=none)
-o ashift=12 ist für 4k Festplatten, ashit=9 für 512e Disks, wobei man mit 12 nichts verkehrt macht
rpool ist der Name vom künftigen Pool, mirror der Raidlevel und die Disks wurden zweifelsfrei über Ihre ID definiertOptionen für Raidlevel wären noch: ohne als Stripe, raidz, raidz2 oder raidz3, also Raid Level 5-7
Im aktuellen Kurs verwenden wir einen älteren Supermicro Server mit 24 Einschüben plus zwei NVMe, damit wir alles abbilden können. Die Verwendung bereits benutzter Disks, die teilweise nicht getestet wurden, wird bald die Notwendigkeit von ZFS bestätigen! Die NVMe sind nach ca zwei bis drei Jahren Cachebetrieb schon am Ende ihrer Laufleistung!
Daher immer Enterprise NVMe und natürlich ECC RAM benutzen, das spart eine Menge Ärger!
Sollten sich dennoch Daten auf Ihren Datenträgern befinden taugt die Wipe Funktion in PVE gut zur Wiederinbetriebnahme belegter Disks, es sei denn es war etwas mit LVM oder CepH auf den Disks.
Solche Datenträger sollte man z. b. mit nwipe extern erst mal löschen.
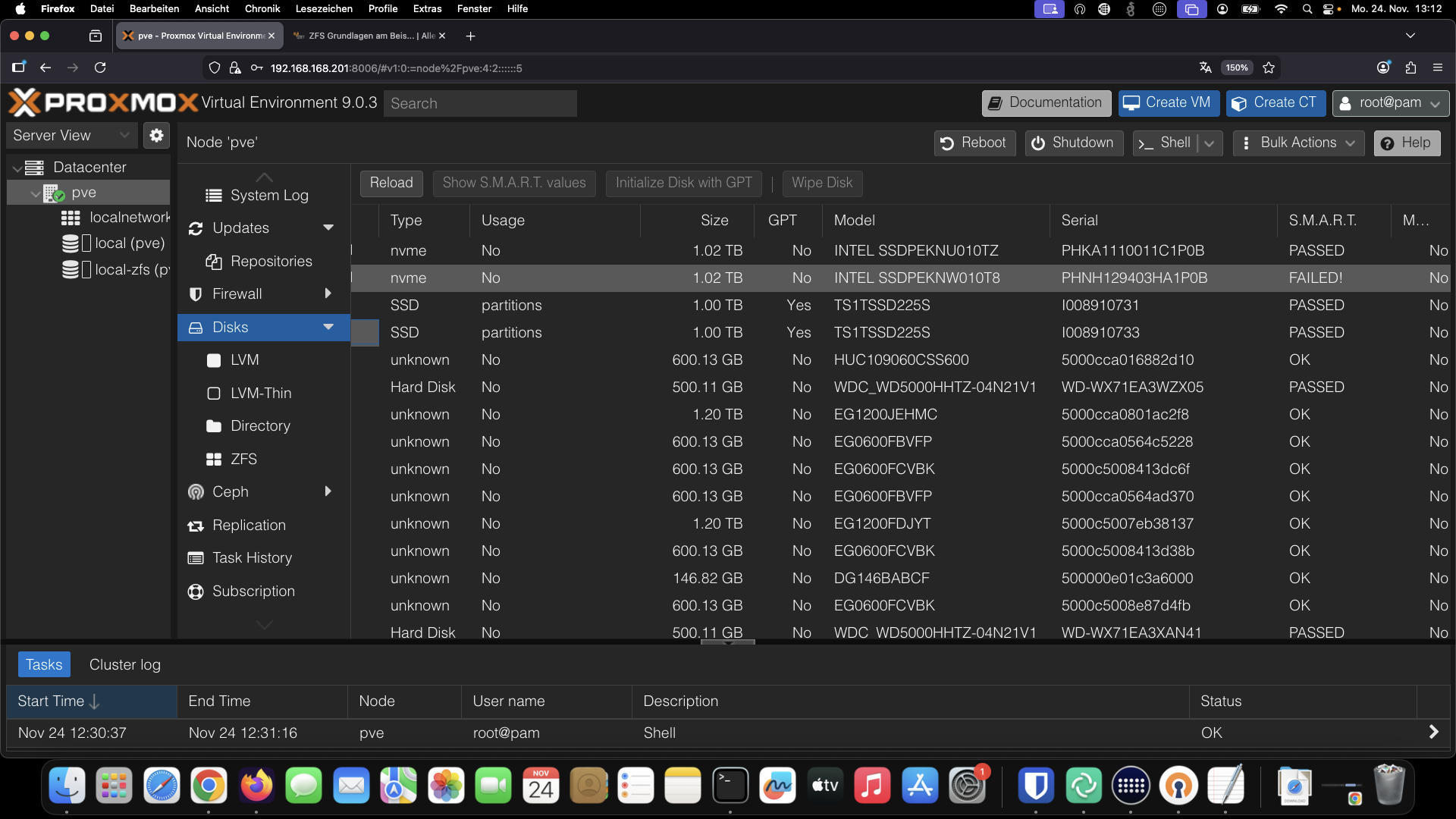
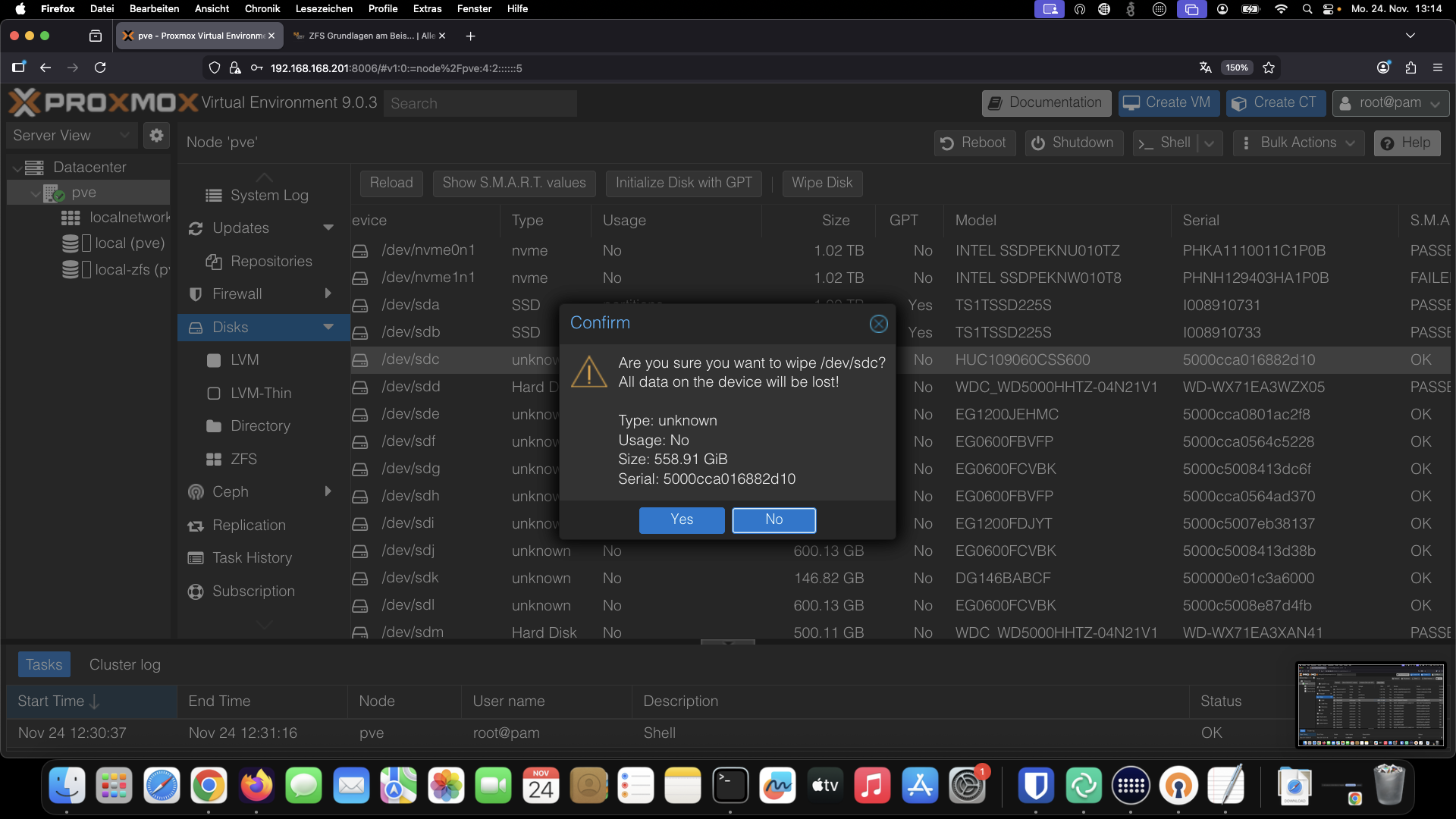
Proxmox, also Debian Linux, bootet aus lizenztechnischen Gründen nicht direkt von ZFS.
Daher ist zu beachten daß immer genügend Bootdisks mit einem dreiteiligen Partitionslayout vorhanden sind. Würde man im Laufe der Zeit die beiden dritten Partitionen gegen komplette Disks ersetzen, wäre nichts mehr zum für den Systemstart vorhanden. Bei Proxmox VE übernimmt diesen Teil das Tool proxmox-boot-tool (format/init/status) der auf die zweite Partition angewendet wird. Die erste Partition enthält noch Grub für Bios Boot, die Dritte dann das eigentliche ZFS mit Proxmox VE.Hierzu empfehle ich unsere Kursreihe Proxmox Produktiv mit ZFS betreiben!
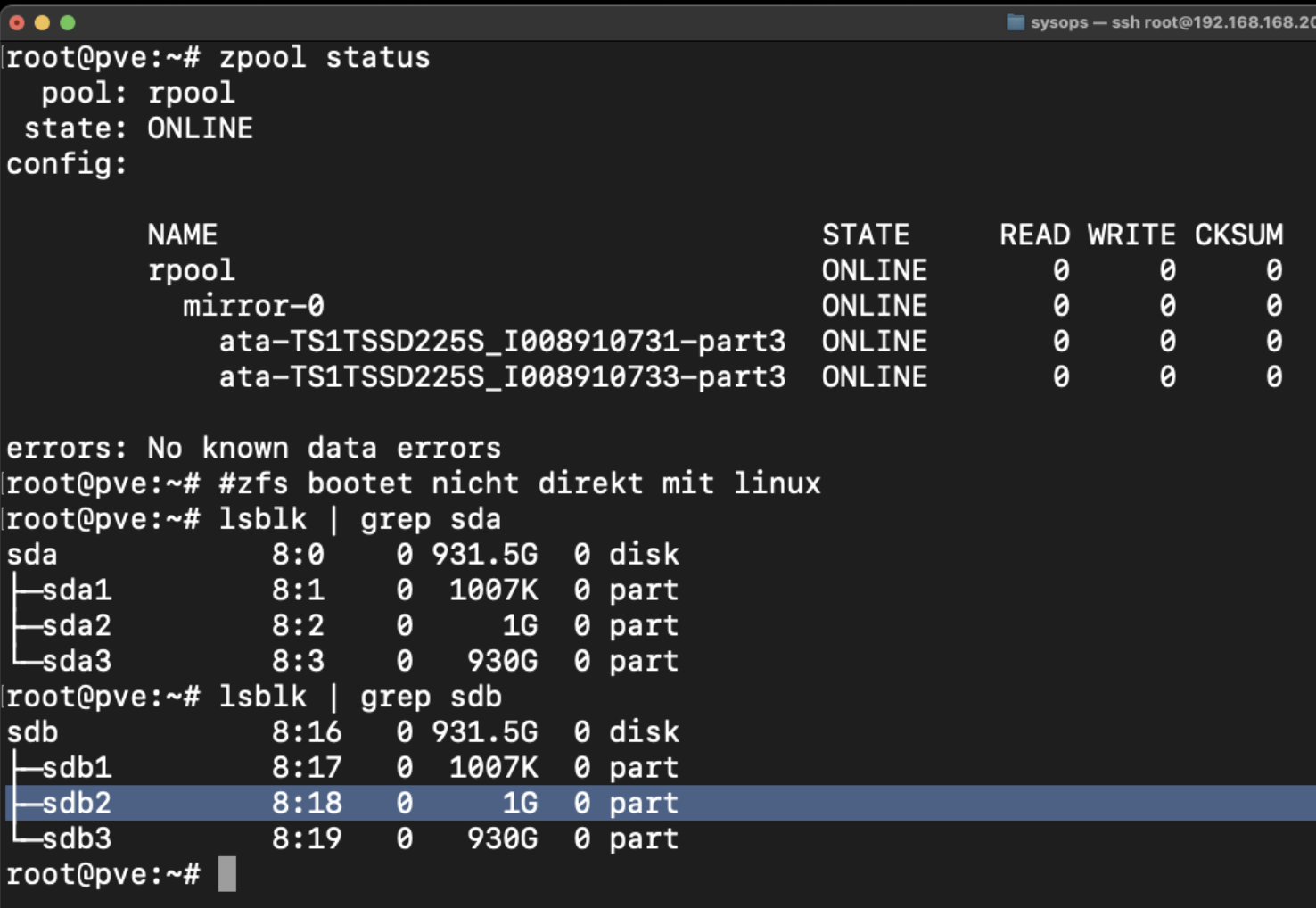
Ermittlung der Laufwerke mit der Kommandozeile
Für den Betrieb empfehlen sich einige Werkzeuge die eventuell nicht enthalten sind, daher installieren wir diese über unseren Postinstaller oder per Hand
apt install lshw iotop
#Detailierte Übersicht aller Laufwerke
lshw -class disk
#Liveansicht beim Enschieben von Platten
dmesg -Tw #time follow
#Auflösung von symbolischen Links im System - Hier werden teilweise mehrere Namenskonventionen angeboten, pro Disk und pro Parition
ls -althr /dev/disk/by-id
Beispiel lshw
Beispiel by-id Ordner

Die Optionen der Raidanlage
Die wichtigsten Parameter sind RAID Level, Compression und Ashift. Alle drei Parameter können bei Fehlentscheidungen zu langfristigen Konsequenzen führen.
Beispiel Fehlentscheidung Raidlevel
- Mirror oder Striped Mirror (Raid 10) sind niemals eine falsche Entscheidung, jedoch verlieren wir hier immer 50% unserer Kapazität. Der entscheidende Vorteil bei einer Erweiterung ist daß man nur zwei Platten aus einem Spiegel ersetzen muss. Beim einfachen Mirror kann eine verdächtige Platte auch einfach entnommen und in die Schublade gelegt werden. Beim Austausch von Disks kann man auch einfach eine dritte Platte einspiegeln und später die Alte entfernen, so verliert man nie den Schutz beim Tausch und kann die alte Disk archivieren.
- Vorteile: Schnell, einfach, problemlos
- Nachteile: Hoher Verlust der Kapazität, 50% immer für Spiegel
- Optionen: Bei SATA / SAS Raids gut mit Cache und LOG per NVMe zu beschleunigen
- RaidZ Level 1-3 kann bei drehenden Festplatten eine fatale Entscheidung sein. Die Nutzlast entspricht immer der Anzahl der Platten minus ein bis drei Paritäten. Also RaidZ2 entspricht Raid6 und bei acht Platten würde die Kapazität von zwei Platten für Parität verloren gehen, bei RaidZ1 eine und natürlich bei RaidZ3 drei.
- Vorteile: Mehr Platz, mehr Sicherheit, Erweiterbarkeit mit einzelnen Disks oder weiteren VDevs
- Nachteile: Für VMs und LXCs nur bedingt als Datengrab, NAS, Fileserver geeignet
- Optionen: Bei SATA / SAS HDDs und SSDs sind diese Raids gut mit Cache und LOG per NVMe zu beschleunigen. Zusätzlich besteht auch die Möglichkeit eines Special Devices, welches Metadaten und kleine Blöcke auf SSDs oder NVMes ablegt.
- Pool aus mehreren RaidZ-VDev kann als Kompromiss zwischen Platz und Leistung gewertet werden. Eine Vergrößereung des Pools ist dann an mehreren Stellen möglich
- Vorteile: Mehr Platz, mehr Sicherheit, Erweiterbarkeit mit einzelnen Disks oder weiteren VDevs und schneler als ein RaidZ mit nur einem VDev bei gleicher Anzahl von Disks
- Nachteile: Für VMs und LXCs nur bedingt als Datengrab, NAS, Fileserver geeignet
- Optionen: Bei SATA / SAS HDDs und SSDs sind diese Raids gut mit Cache und LOG per NVMe zu beschleunigen. Zusätzlich besteht auch die Möglichkeit eines Special Devices, welches Metadaten und kleine Blöcke auf SSDs oder NVMes ablegt.
- Stripe und dRaid machen in diesem Umfeld keinen Sinn und werden daher nicht behandelt
Virtuelle Maschinen im Normalfall nie auf drehende Disks mit RaidZ ablegen. Als Kompromiss kann man gut SATA RaidZ plus Cache & LOG Beschleunigung verwenden um Platz zu gewinnen
Die Analge von Raids per Proxmox ist möglich, jedoch ist man mit der Konfiguration per Kommandozeile viel flexibler!
Beispiel Fehlentscheidung Ashift
Hier etwas technischer Hintergrund im Vorfeld
Bei ZFS bezeichnet ashift die Blockgröße (Sektorgröße), mit der ZFS intern auf einem vdev arbeitet.Üblicherweise arbeiteten wir früher mit ashift=9 (512b) oder ashift=12 (4096b, also 4k)...
Daher aktuel immer ashift=12 nehmen um alle aktuell angesagten Disks in allen Raidlevel zu unterstützen.
Setzt man diesen Wert oder auch den volblocksize Wert kleiner als 16, schreibt zfs einzelne Blöcke auf mehr als Einen!Die Konsequenz sind massive Leistungseinbusen und Platzverschwendung von bis zu 50%!
Beispiel der unspektakulären Raidanlage unter ProxmoxVE
Nach der Anlage eines Raid mit ProxmoxVE empfiehlt sich die Basis nicht wie hier auf mirror500g zu setzen, sondern die zu erwartenden Dateisysteme und Volumes zu strukturieren und dann dort den Proxmox Storage zu definieren
zfs create mirror500g/data zfs create mirror500g/clone zfs create -o com.sun:auto-snapshot=false mirror500g/repl #die option sorgt dafür daß das Tool zfs-auto-snapshot hier nicht arbeitetDanach den Storage unter Cluster in ProxmoxVE definieren, z. b. als mirror500g-data
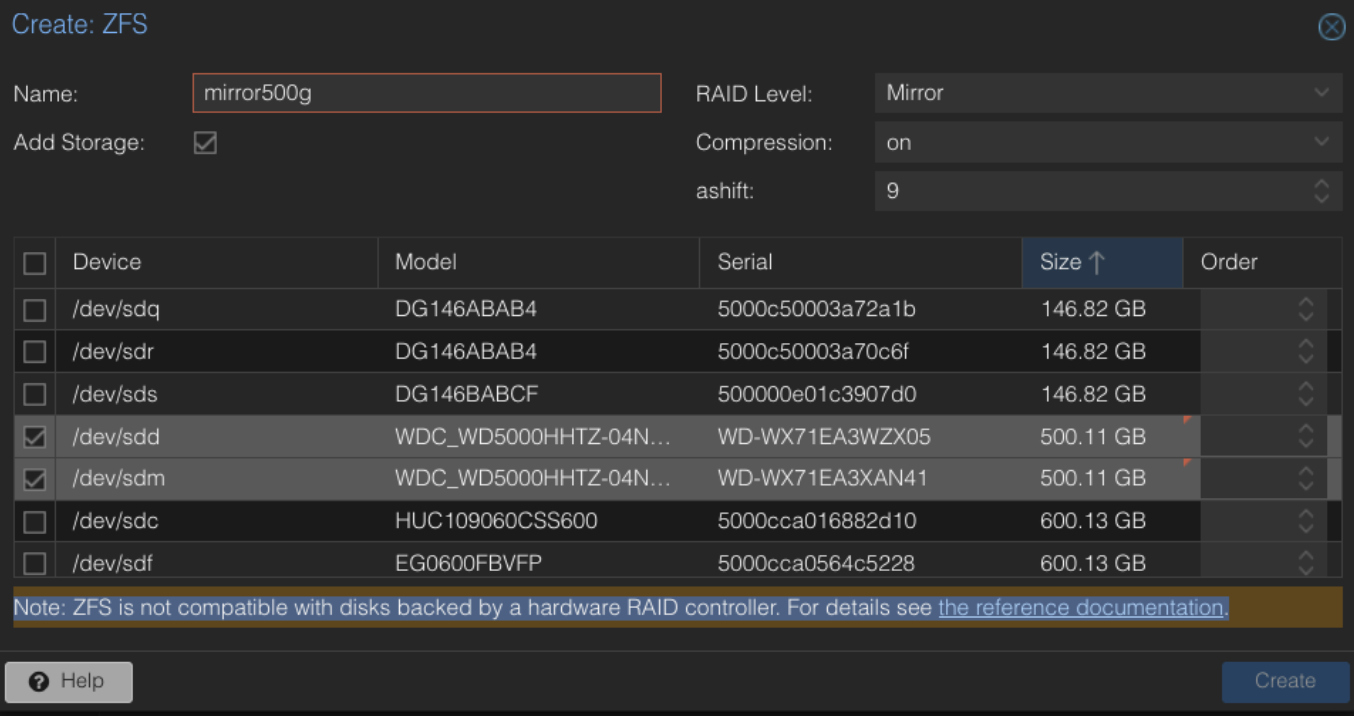
Beispiel Fehlentscheidung Compression
Kompression kann immens viel Platz sparen, aber auch nur da wo unkomprimierte Daten liegen.
Grundsätzlich nehmen wir inzwischen compression=on, früher compression=lz4.
Mit beiden Einstellungen sparen wir oft mindestens ein Drittel der Daten und haben keine spürbaren Geschwindigkeitseinbußen.
Im Zweifelsfall compression=off
Praxis Raidanlage
Mit dem Parameter zpool create -n bekommt man als dry-run erst mal eine Vorschau!
Überlege Dir gut ob die Disks eventuell vorher paritioniert werden müssen, z. B. für Proxmox Boot oder Mischnutzung bei z. B. Cache/Log auf selbem Datenträger
ashift=12 ist inzwischen default
compression=off ist ebenfalls default!
Stripe, also Raid0
zpool create -f test wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
Mirror, also Raid1
zpool create -f test mirror wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c
Striped Mirror, also Raid10
zpool create -f test mirror wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c mirror wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 mirror wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
RaidZ, also Raid 5, Nettoplatz x-1
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
RaidZ2, also Raid 6, Nettoplatz x-2
zpool create test raidz2 wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
RaidZ-0, also Raid 5-0, Nettoplatz x-2, in diesem Beispiel
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
oder mit Spare, wenn Du davon nicht booten musst
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 spare wwn-0x5000cca01a8417fc
Erweiterung eines RaidZ zum RaidZ-0
zpool add -n test raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
Caches und Logdevices
Vorsichtig formuliert, Lese- und Schreibcache
First Level Cache, sog. ARC kommt aus dem RAM und bekommt idealerweise ca. 1GB für 1TB Nettodaten
Second Level Cache wird als Cachedevice als Partition auf einer schnelleren Disk als der Pool hat bereitgestellt, z. B. am idealsten mit NVMe
zpool add test -n cache sdl
Logdevice (Writecache muss gespiegelt werden)Damit der Log auch genutzt wird muss man noch mit zfs set sync den cache aktivieren
zpool add test -n log mirror sdl sdk
zfs set sync=always test
Arc wird mit "arcstat 1" ausgelesen, er wird bei der Installation festgelegt oder später unter /etc/modprobe.d/zfs.conf geändert. update-initramfs -u macht das dann persistent und aktiviert die Änderungen beim nächsten reboot.Zur Laufzeit ändert man den Firstlevelcahce mitCache- und Logdevices mit zpool iostat 1
echo 2147483648 > /sys/module/zfs/parameters/zfs_arc_max # ca 1GB pro Raidnetto x 1024 x 1024 x 1024
echo 1073741824 > /sys/module/zfs/parameters/zfs_arc_min # die Hälfte vom Max als Praxisempfehlung
free -h && sync && echo 3 > /proc/sys/vm/drop_caches && free -h #haut den Cache eben mal weg wenn RAM voll ist
arcstat 1
Hier ein Beispiel für einen idealen HDD Raid10 mit Cache(Stripe) und LOG (Mirror)
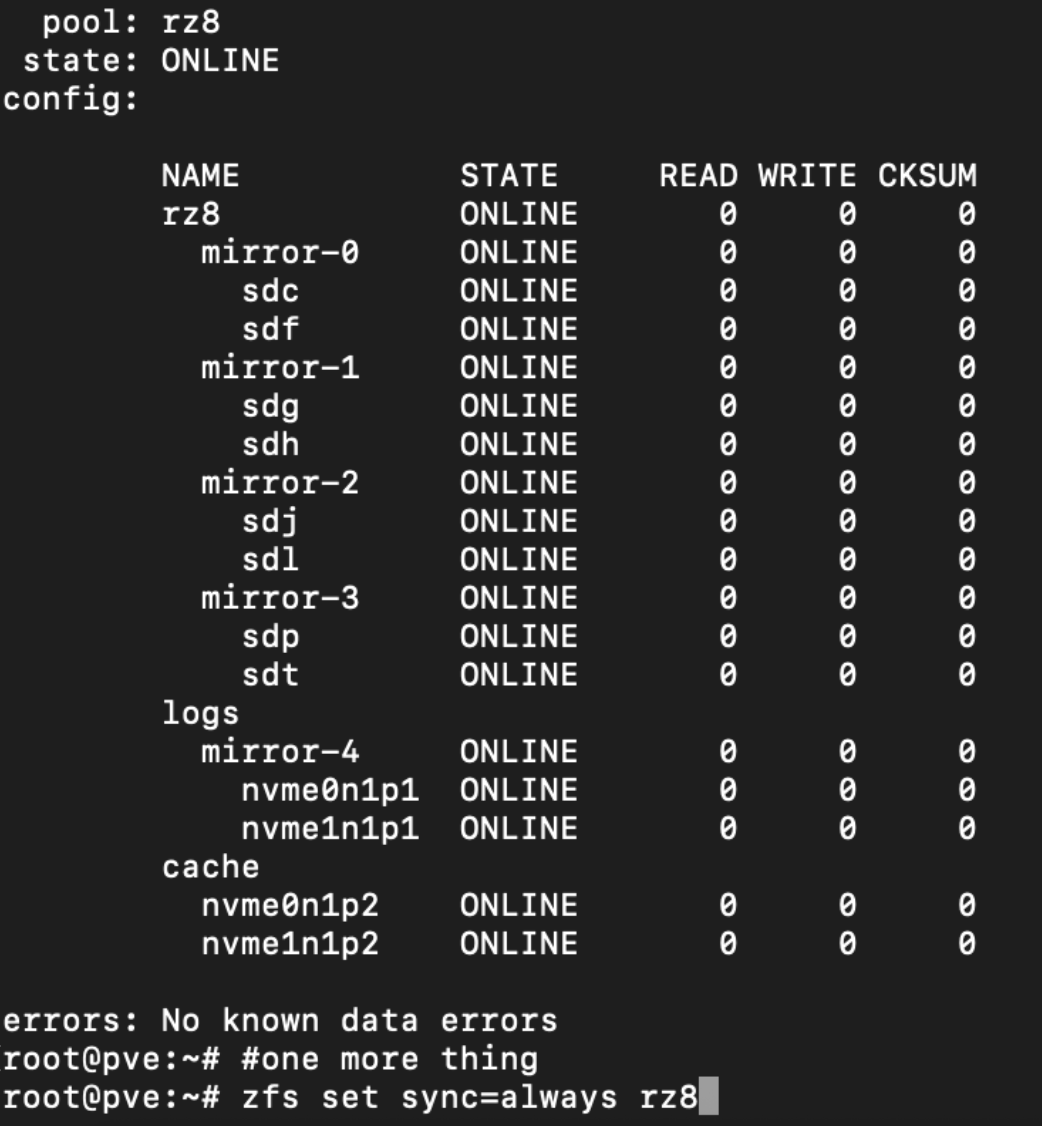
Beispiel Special Device, zwingend als Mirror!
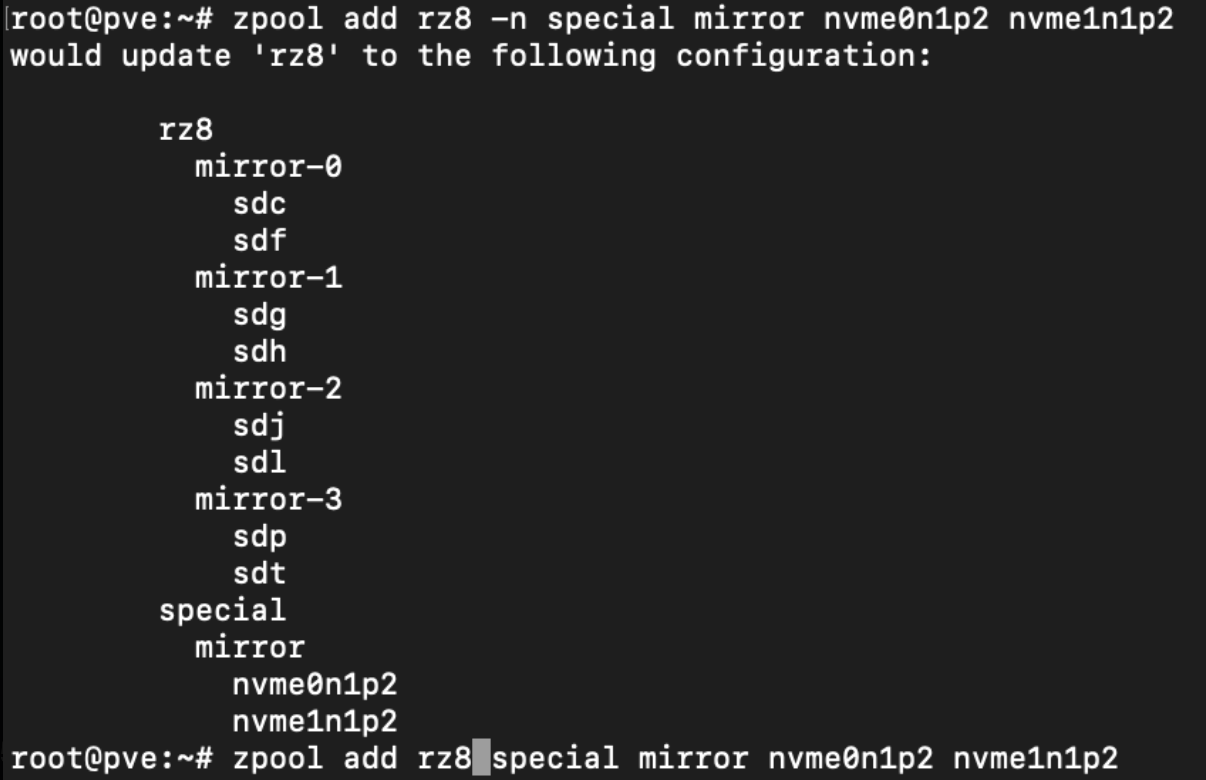
Sinnvoll wirksam wird es erst nach der Definition der Blocksize die auf die NVMe gehen soll, also vermutlich so grob 64k und kleinere Blöcke
Im VM-Betrieb konnten wir durch Special Device keine Leistungssteigerung feststellen, nur bei Fileserver und LXCs

Beispiel arcstat 1
Erweiterung der Funktionen des Pools
zpool status meldet neue Funktionen im ZFS und kann leicht und schnell mit
zpool upgrade -a
erledigt werden
Jedoch würde ich in jedem Fall empfehlen zu prüfen ob meine Notfall ISO diese Funktionen bereits unterstützt!
Für das Auslesen der Parameter von Pools, Volumes, Datasets und Snapshots gibt es den Parameter get
Bereitstellen und entfernen von Pools ohne löschen
zpool import #zeigt was es zum importieren, also bereitstellen gibt zpool import poolname #oder -a für alle importiert den Pool oder alle verfügbaren PoolsAm elegantesten importiert man den Pool über
zpool import -d /dev/disk/by-iddamit man hinterher nicht sda, sdb, sondern die Bezeichner im Status sieht
Nach der Bereitstellung würde man hier lediglich einen Mountpoint /test finden, bei TrueNAS /mnt/test. Dazu noch die Systemdatasets vom Proxmox selbst. Danach legen wir gleich mal ein Dataset namens dateisystem und ein Volume namens volume an.
Anlage eines ZVOL (unter /dev zu finden)
Datasets werden als Ordner gemountet und / oder /mnt (altroot)
Volumes findet man unter /dev/zd... und zusätzlich mit vernünftigen Namen unter /dev/zvol/tankname/....
Datasets werden mit Linuxcontainern, Backupfiles, Vorlagen oder Serverdateien bespielt
Volumes verhalten sich wie eingebaute Datenträger, jedoch virtuell. Sie stehen nach dem Import des Pools bereit und können in einer VM genutzt werden. Manipulationen an Volumes zur Vorbereitung oder Datenrettung können jedoch ebenso auf dem PVE Host vorgenommen werden
Diese Schritte übernimmt üblicherweise der Installer in der VM und sollen nur aufzeigen wie diese ZVOLs genutzt werden
Proxmox legt seine Datasets für in LXC so in ZFS ab
und so die ZVOLs für VMs mit KVM, hier findet man die virtuellen Disk und /dev/zvol...
Thin- und Thickprovisioning für Datasets und Volumes
Am Beispiel von Proxmox VE via GUI wird hier eine Thinprovision Festplatte für VM 301 mit 32GB und einer Standardblockgröße von 16k erzeugt. 8k sind nur bei Raid1 und 10 möglich. Hakt man den Thinprovision Haken nicht an, wird beim Erzeugen noch die Option -o refreservation=32G ergänzt. Diese macht bei ZFS mit Autosnapshots aber keinen Sinn
zfs create -s -b 16k -V 33554432k rpool/data/vm-301-disk-4
rpool/data/vm-301-disk-4 56K 1.17T 56K - #hier kein Mount sonder unter /dev/zvol/...
Bei LXC werden Datasets genutzt und der Platz via Reservierung genutzt, wobei bei der genutzten Refquota auch die Snapshotaufhebezeiten den Nettoplatz verkleinern, daher größer dimensionieren, gerne mal doppelt so groß
zfs create -o acltype=posixacl -o xattr=sa -o refquota=33554432k rpool/data/subvol-106-disk-1
rpool/data/subvol-106-disk-1 96K 32.0G 96K /rpool/data/subvol-106-disk-1 #hostzugriff möglich
Virtuelle Diskimages wie QCOW2, VMDK oder RAW-Dateien legt man üblicherweise nicht in Datasets, bestenfalls für NFS oder iSCSI Server
Das Ende von Hetzner DNS Robot und ACME API - Stand Januar 2026
Hallo liebe Kursteilnehmer,
ich wünsche euch zunächst ein frohes neues Jahr 🎉
Bitte schaut euch die Sendung zum Thema
„Welche unnötigen Arbeiten müssen dieses Jahr erledigt werden?“ – Live vom 05.01.2026
an.
⚠️ Wichtige Änderung: Hetzner Robot DNS Service
Wir nutzen den Hetzner Robot DNS Service seit fast 20 Jahren.
Dieser endet im Mai 2026.
🔗 Statusmeldung von Hetzner:
https://status.hetzner.com/incident/c2146c42-6dd2-4454-916a-19f07e0e5a44
Domänen werden anschließend automatisch in die neue Verwaltungskonsole umgezogen:
🔗 Neue Hetzner Console:
https://console.hetzner.com/projects
Wichtig:
-
In der alten Verwaltung können keine neuen DNS-Zonen mehr angelegt werden
-
API-Keys lassen sich dort ebenfalls nicht mehr erzeugen
🚨 Kritischer Punkt: Automatisierungen
Alle Automatisierungen, die z. B. mit
-
OPNsense
-
Proxmox VE
-
Proxmox Mail Gateway (PMG)
arbeiten, funktionieren spätestens ab Mai nicht mehr, sofern sie noch den alten Hetzner DNS-Service verwenden.
🔐 ACME / Zertifikate – aktueller Stand (heute)
✅ OPNsense Community
-
ACME Plugin 4.11
-
Funktioniert mit der Hetzner Cloud Console
-
Vorgehen:
-
Neue Challenge anlegen
-
Im Zertifikat entsprechend anpassen
-
⚠️ OPNsense Business
-
Enthält aktuell ACME Plugin 4.10
-
Funktioniert noch nicht mit der neuen Hetzner API
-
Neuer Release-Termin für die Business Edition ist noch offen
⚠️ Workaround (auf eigenes Risiko!)
Funktioniert bei uns im Test und soll laut OPNsense upgradefähig sein:
pkg add -f https://pkg.opnsense.org/FreeBSD:14:amd64/25.7/latest/All/acme.sh-3.1.2.pkg
pkg add -f https://pkg.opnsense.org/FreeBSD:14:amd64/25.7/latest/All/os-acme-client-4.11.pkg
🖥️ Proxmox VE / PMG / PBS
-
Das neue ACME scheint hier noch nicht enthalten zu sein
-
PMG unterstützt keine HTTP-Challenge als Alternative
🔧 Mögliche Lösungen
-
HTTP-Challenge (falls verfügbar)
-
Gekauftes Zertifikat
-
Zertifikats-Upload über OPNsense
Hinweis:
-
PVE und PBS werden von der OPNsense-Variante direkt unterstützt
-
PMG nicht, da hierfür keine API existiert
➡️ Für PMG sind zwei getrennte Automationen notwendig:
-
Upload
-
Aktivierung
sleep 90 ; pmgconfig cert set api /root/-.sysopservice.net/fullchain.pem /root/-.sysopservice.net/key.pem --force --restart 1 ; pmgconfig cert set smtp /root/-.sysopservice.net/fullchain.pem /root/-.sysopservice.net/key.pem --force --restart 1
🛠️ Support
Die sysops GmbH unterstützt bei Problemen gerne.
Bitte nutzt hierfür folgende Kontaktadresse:
📧 ticket@sysops.de
Der neue Kursplan folgt in den nächsten Tagen.
Liebe Grüße
Chriz