ZFS Grundlagen am Beispiel Proxmox VE(Stand Januar 2025)
Der Verfasser des Artikels, Christian-Peter Zengel, hat zum Zeitpunkt des Artikels ca 15 Jahre Erfahrung mit ZFS und Proxmox. Er betreibt aktuell ca 150 Systeme mit Proxmox und ZFS
Das Einsatzgebiet geht von Standaloneinstallation bis zu ca 10 Hosts im Cluster. Es ist keine Ceph Expertise vorhanden!
Dieser Dokumentation basiert auf diesem online Kurse von cloudistboese.de
21. + 23.01.2025 (13.00 Uhr bis 17.00 Uhr) - ZFS Grundlagen
ZFS ist die perfekte Grundlage für kleine und mittlere Systeme um gegen Ausfälle, Dummheit anderer und Erpressungstrojanern ideal aufgestellt zu sein.
In diesem Kurs erhalten sie Grundkenntnisse für Systeme wie Proxmox, TrueNAS oder ähnliche Systeme.
Der Fokus liegt auf der Technologie und der permanenten Sicherheit im Umgang mit Daten, Linux und dem Terminal.
Themen:
- Begrifflichkeiten und Überblick
- Basisfunktionen von Proxmox und TrueNAS per GUI
- Erklärung und Beispiele Snapshots und Rollbacks
- Praxisbeispiele Replikation
- Prüfung der Replikationen
- Weitere Features die das Leben massiv erleichtern
Nach diesem Kurs bist Du bei Ausfällen und Datenverlust vor dem Schlimmsten geschützt und in Minuten wieder produktiv!
So erstellt Proxmox VE seinen ZFS Raid
zpool create -f -o cachefile=none -o ashift=12 rpool mirror disk1 disk2
Destruktives Anlegen (-f), kein automatisches Importieren beim Start (-o cachefile=none)
-o ashift=12 ist für 4k Festplatten, ashit=9 für 512e Disks, wobei man mit 12 nichts verkehrt macht
rpool ist der Name vom künftigen Pool, mirror der Raidlevel und die Disks wurden zweifelsfrei über Ihre ID definiertOptionen für Raidlevel wären noch: ohne als Stripe, raidz, raidz2 oder raidz3, also Raid Level 5-7
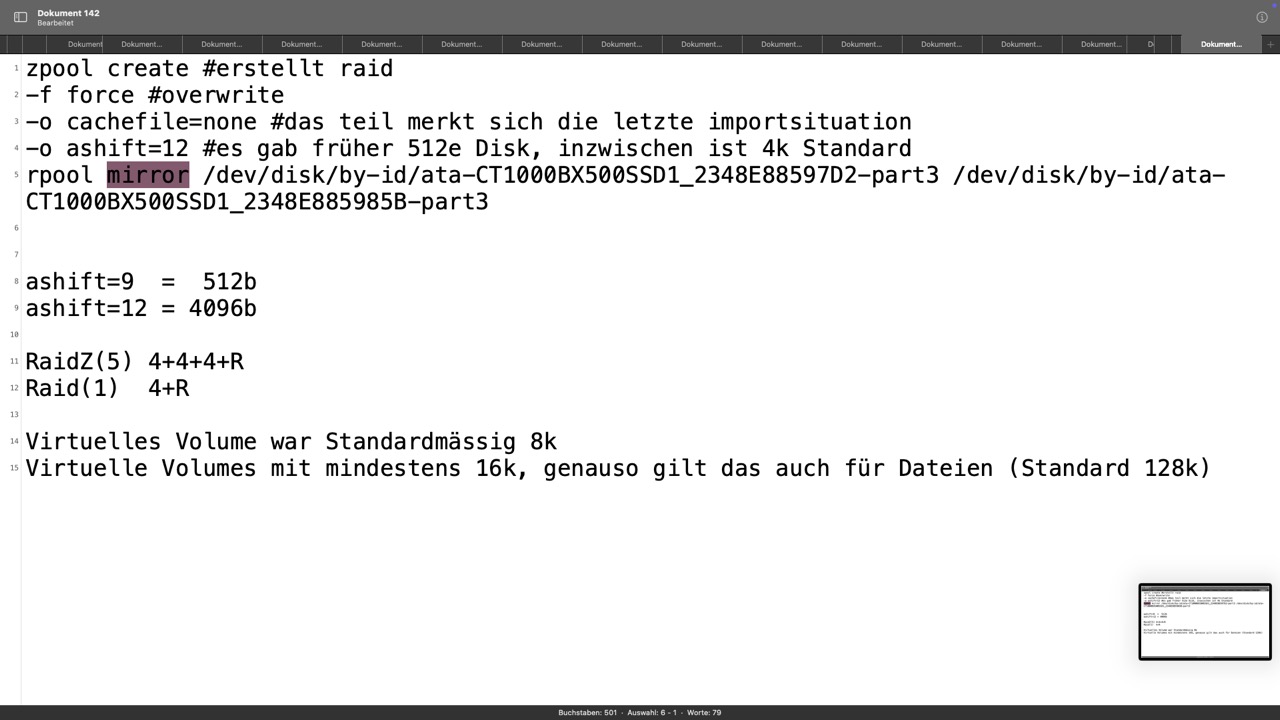
Die ersten Zpool Manöver und die endlose Aktionsliste sieht man mit
zpool history
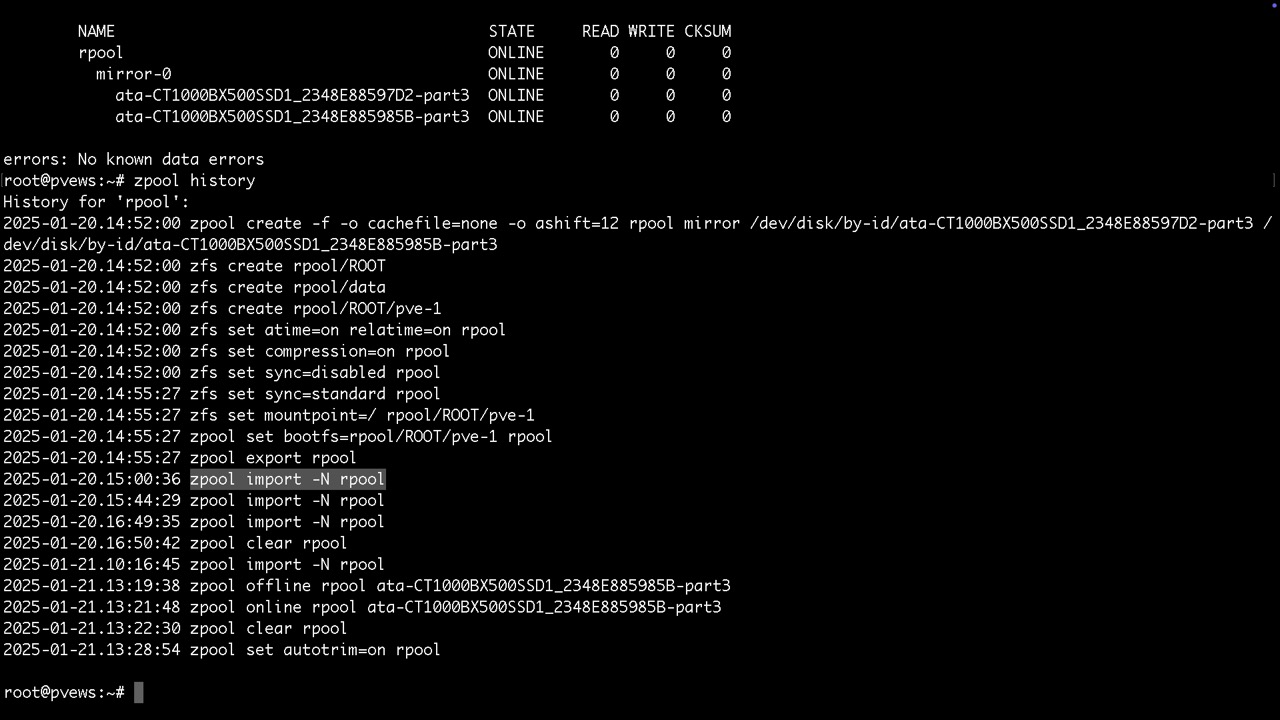
Manuelles Trimmen der SSDs um gelöscht Blöcke schner überschreiben zu können findet man unter /etc/cron.d
Ebenso wird nach diesem Zeitplan der sog. zpool scrub durchgeführt, der die Konsistenz der Redundanz prüft und ggf. korrigiert. Gefundene Fehler findet man dann mit zpool status
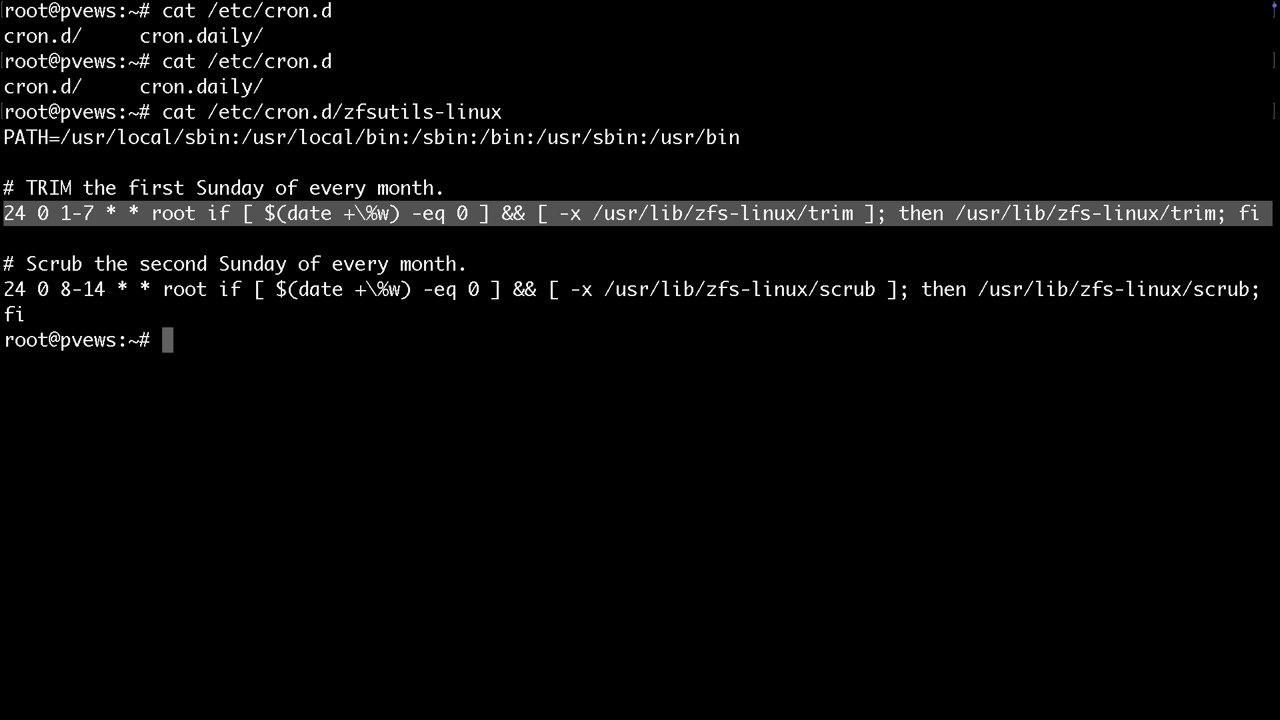
Zum identifizieren der Platten bieten sich neben der PVE GUI noch folgende Befehle an. Es wird dringend empfohlen bereits genutzte Platten via PVE GUI zu wipen
dmesg -Tw (live)
lsblk
ls -althr /dev/disk/by-id
Erstellen verschiedener Raidlevel und Ihrer Vorzüge
Mit ls -althr /dev/disk/by-id haben wir folgende Festplatten anhand ihrer aufgedruckten WWN Kennung identifiziert. Es ist dringend empfohlen bei HBAs sich die Slots und die Seriennummern beim Einbau zu notieren und in die Dokumentation aufzunehmen
wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
Stripe, also Raid0
zpool create -f test wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
Mirror, also Raid1
zpool create -f test mirror wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c
Striped Mirror, also Raid10
zpool create -f test mirror wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c mirror wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 mirror wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
RaidZ, also Raid 5, Nettoplatz x-1
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
RaidZ2, also Raid 6, Nettoplatz x-2
zpool create test raidz2 wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
RaidZ-0, also Raid 5-0, Nettoplatz x-2, in diesem Beispiel
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
oder mit Spare, wenn Du davon nicht booten musst
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 spare wwn-0x5000cca01a8417fc
Erweiterung eines RaidZ zum RaidZ-0
zpool add -n test raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
Erweiterung eines Raid durch Ersetzen mit größeren Platten
Die Platten müssen die Gleiche Geometrie hanben, also 4k zu 4k oder 512e zu 512e
Bei Raid 1 und 10 reicht es zwei Disks zu tauschen, bei RaidZx müssen alle Disks getauscht werden
Replace Vorgänge können auch laufen ohne die Redundanz zu brechen, wenn weitere Slots frei sind
Bei Erweiterung durch Austausch von großen und vor allem älteren Raid 10 prüfen ob in einem Mirror ggf. neue Platten getauscht wurden, diese sollten weiter im Betrieb bleiben, während ältere Paare getauscht werden können
Caches und Logdevices
Vorsichtig formuloiert, Lese- und Schreibcache
First Level Cache, sog. ARC kommt aus dem RAM und bekommt idealerweise ca. 1GB für 1TB Nettodaten
Second Level Cache wird als Cachedevice als Partition auf einer schnelleren Disk als der Pool hat bereitgestellt, z. B. am idealsten mit NVMe
zpool add test -n cache sdl
Logdevice (Writecache muss gespiegelt werden)Damit der Log auch genutzt wird muss man noch mit zfs set sync den cache aktivieren
zpool add test -n log mirror sdl
zfs set sync=always test
Arc wird mit "arcstat 1" ausgelesen, er wird bei der Installation festgelegt oder später unter /etc/modprobe.d/zfs.conf geändert. update-initramfs -u macht das dann persistent und aktiviert die Änderungen beim nächsten reboot.Zur Laufzeit ändert man den Firstlevelcahce mitCache- und Logdevices mit zpool iostat 1
echo 2147483648 > /sys/module/zfs/parameters/zfs_arc_max
echo 1073741824 > /sys/module/zfs/parameters/zfs_arc_min
free -h && sync && echo 3 > /proc/sys/vm/drop_caches && free -h
arcstat 1
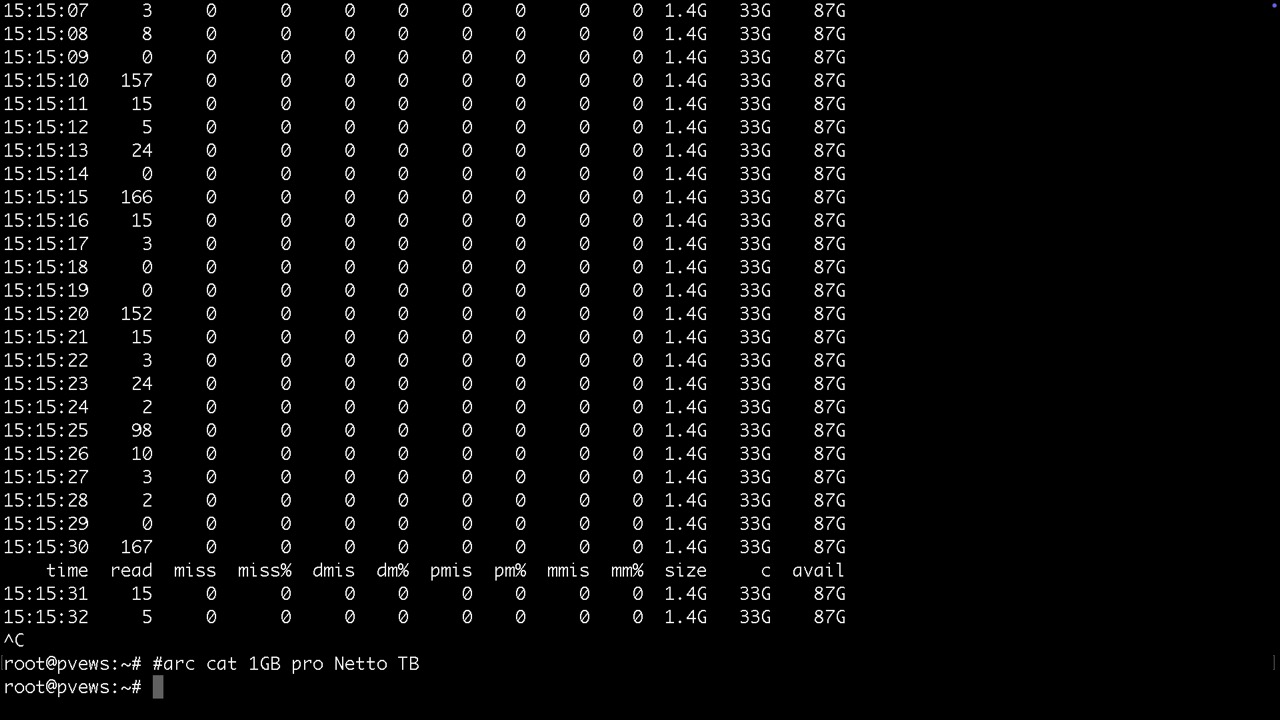
Test der Leistung eines Pools
zfs create -o compression=off test/speed
cd /test/speed
dd if=/dev/zero of=dd.tmp bs=256k count=16384 status=progress
dd if=/dev/zero of=dd.tmp bs=2M count=16384 status=progress


Erweiterung der Funktionen des Pools
zpool status meldet neue Funktionen im ZFS und kann leicht und schnell mit
zpool upgrade -a
erledigt werden
Jedoch würde ich in jedem Fall empfehlen zu prüfen ob meine Notfall ISO diese Funktionen bereits unterstützt!
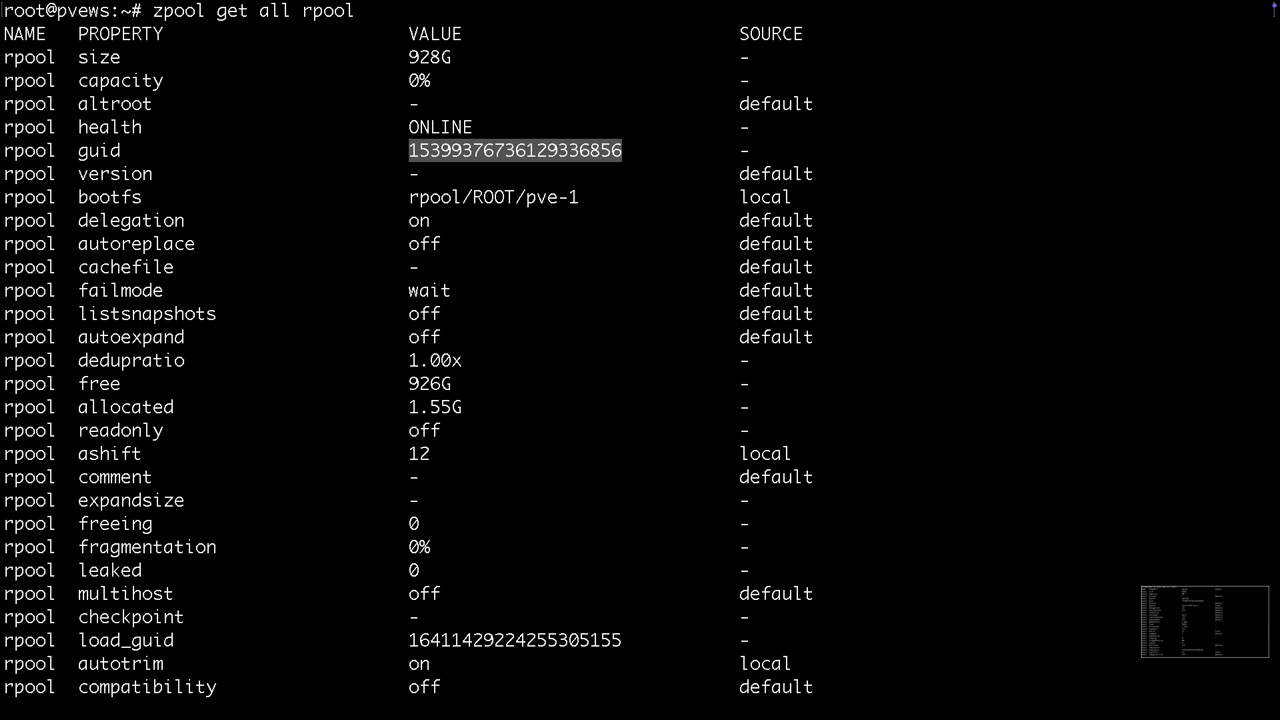
Für das Auslesen der Parameter von Pools, Volumes, Datasets und Snapshots gibt es den Parameter get
Bereitstellen und entfernen von Pools ohne löschen
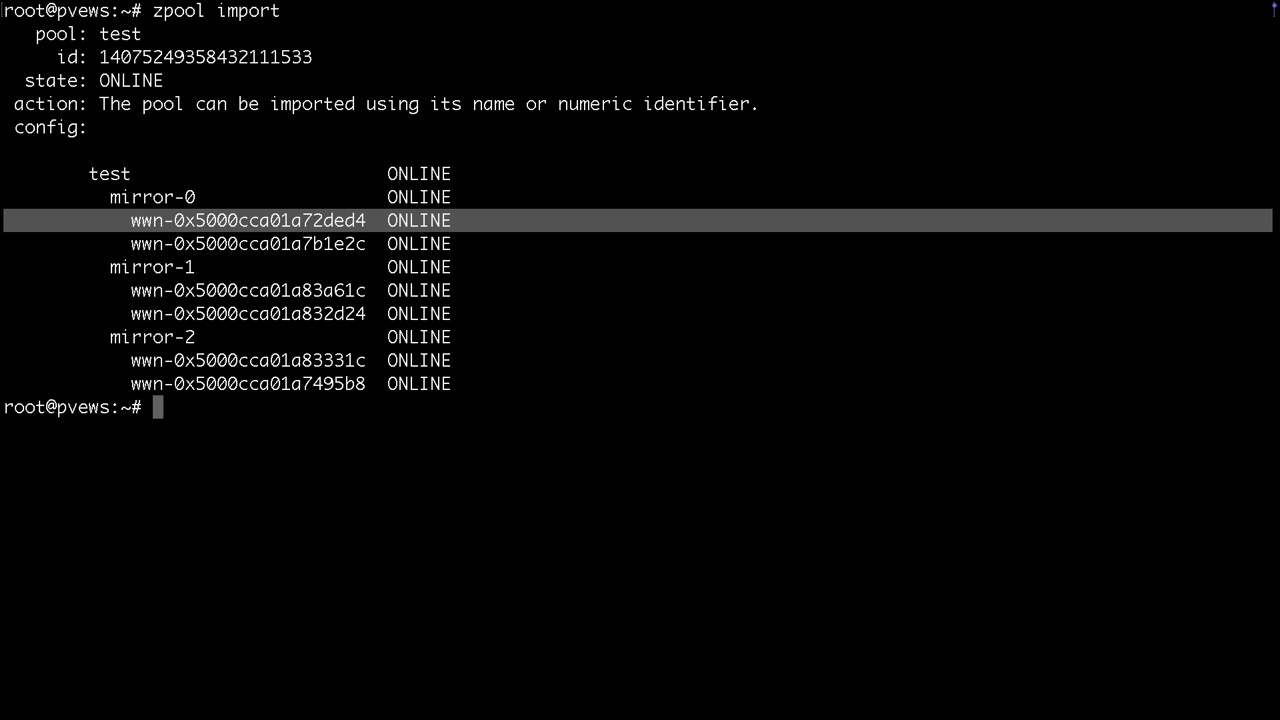
zpool import #zeigt was es zum importieren, also bereitstellen gibt
zpool import poolname oder -a für alle importiert den Pool oder alle verfügbaren Pools
Am elegantesten importiert man den Pool über
zpool import -d /dev/disk/by-id
damit man hinterher nicht sda, sdb, sondern die Bezeichner im Status sieht
Nach der Bereitstellung würde man hier lediglich einen Mountpoint /test finden, bei TrueNAS /mnt/test. Dazu noch die Systemdatasets vom Proxmox selbst. Danach legen wir gleich mal ein Dataset namens dateisystem und ein Volume namens volume an.
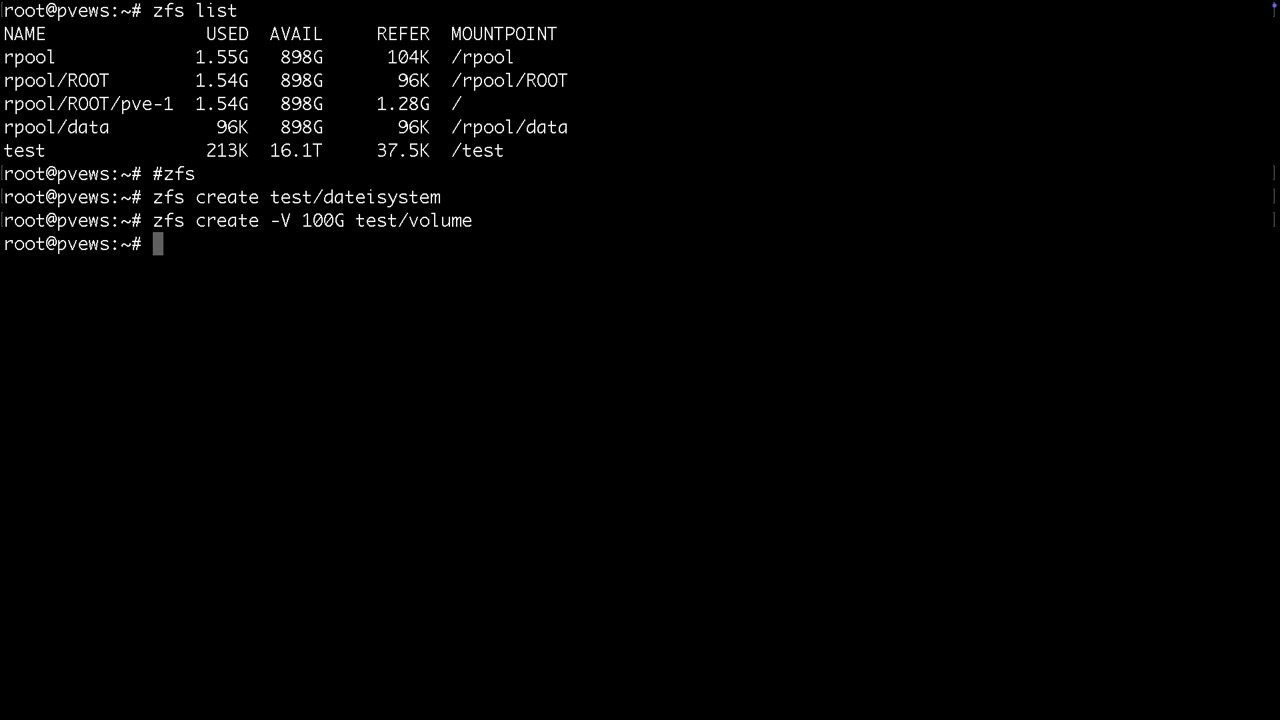
Datasets werden als Ordner gemountet und / oder /mnt
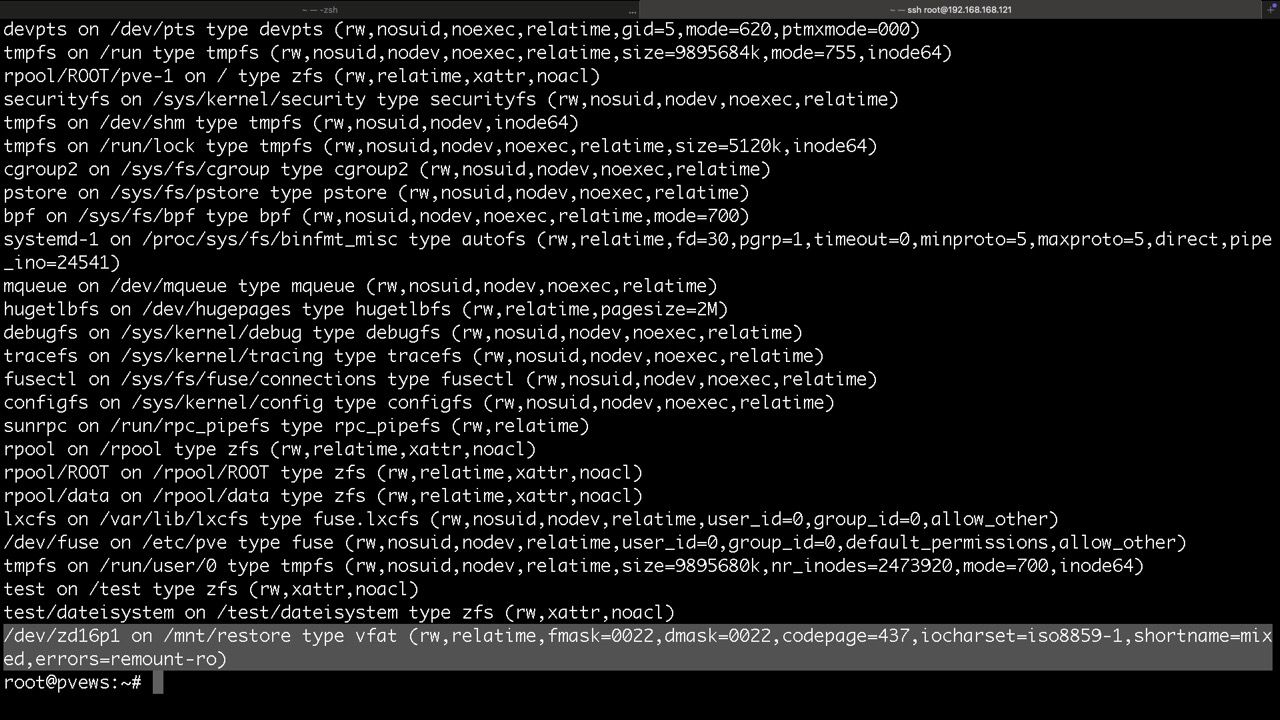
Volumes findet man unter /dev/zd... und zusätzlich mit vernünftigen Namen unter /dev/zvol/tankname/....
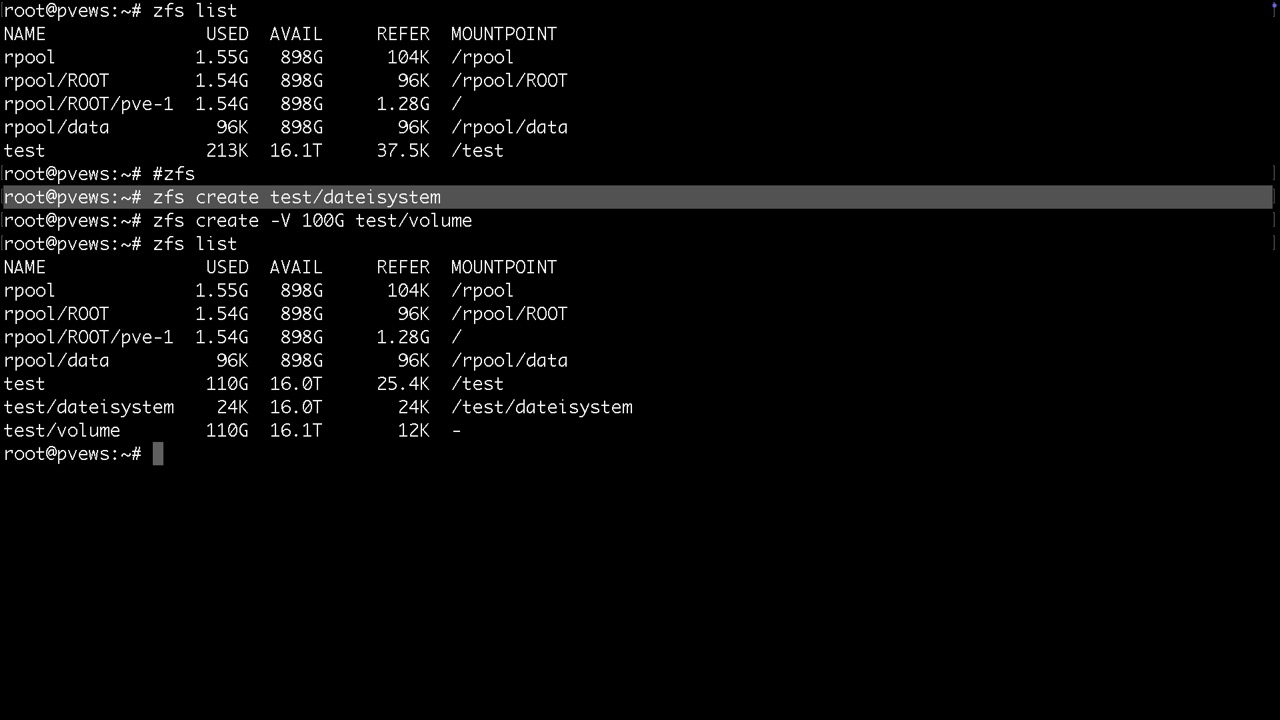
Datasets werden mit Linuxcontainern, Backupfiles, Vorlagen oder Serverdateien bespielt
Volumes verhalten sich wie eingebaute Datenträger, jedoch virtuell. Sie stehen nach dem Import des Pools bereit und können in einer VM genutzt werden. Manipulationen an Volumes zur Vorbereitung oder Datenrettung können jedoch ebenso auf dem PVE Host vorgenommen werden
Diese Schritte übernimmt üblicherweise der Installer in der VM und sollen nur aufzeigen wie diese ZVOLs genutzt werden
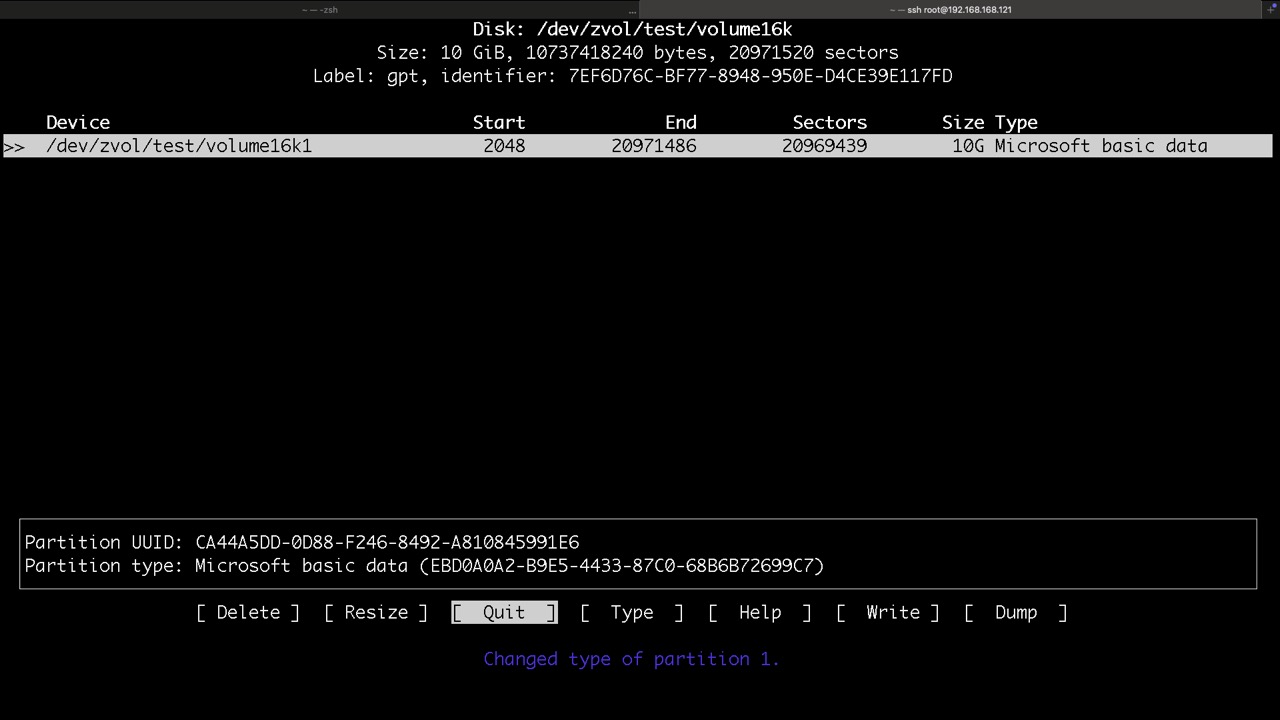
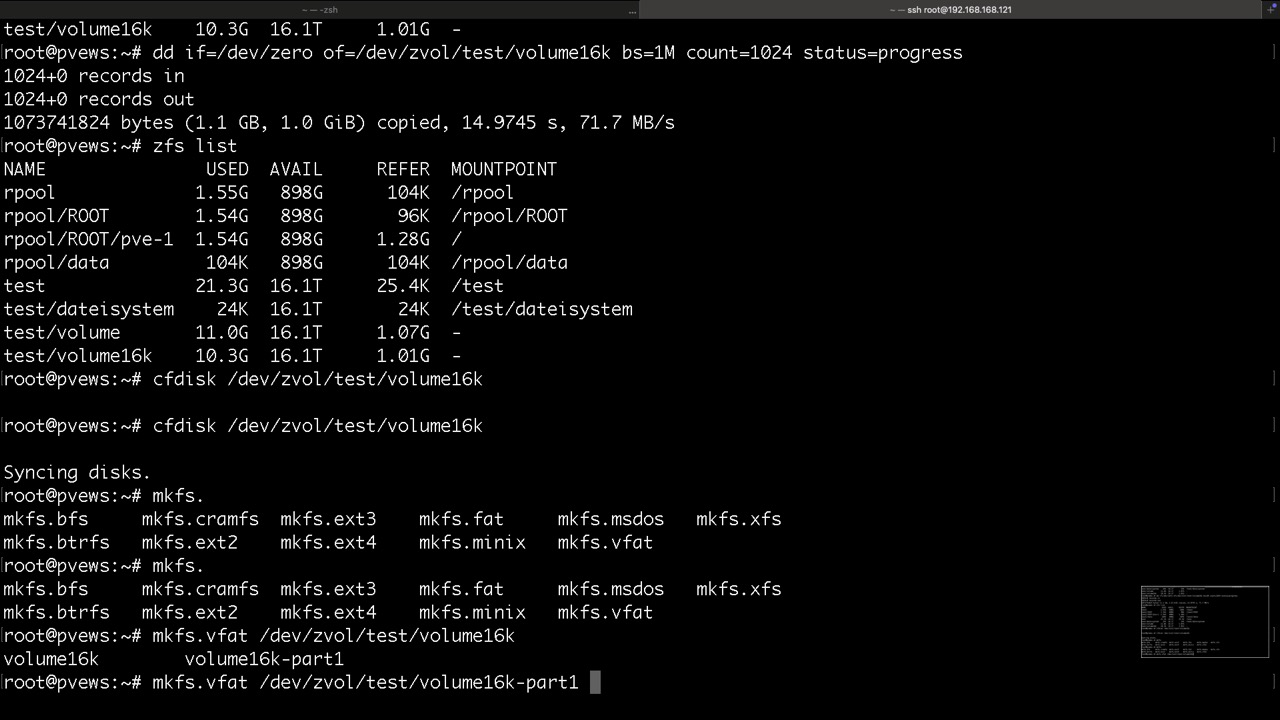

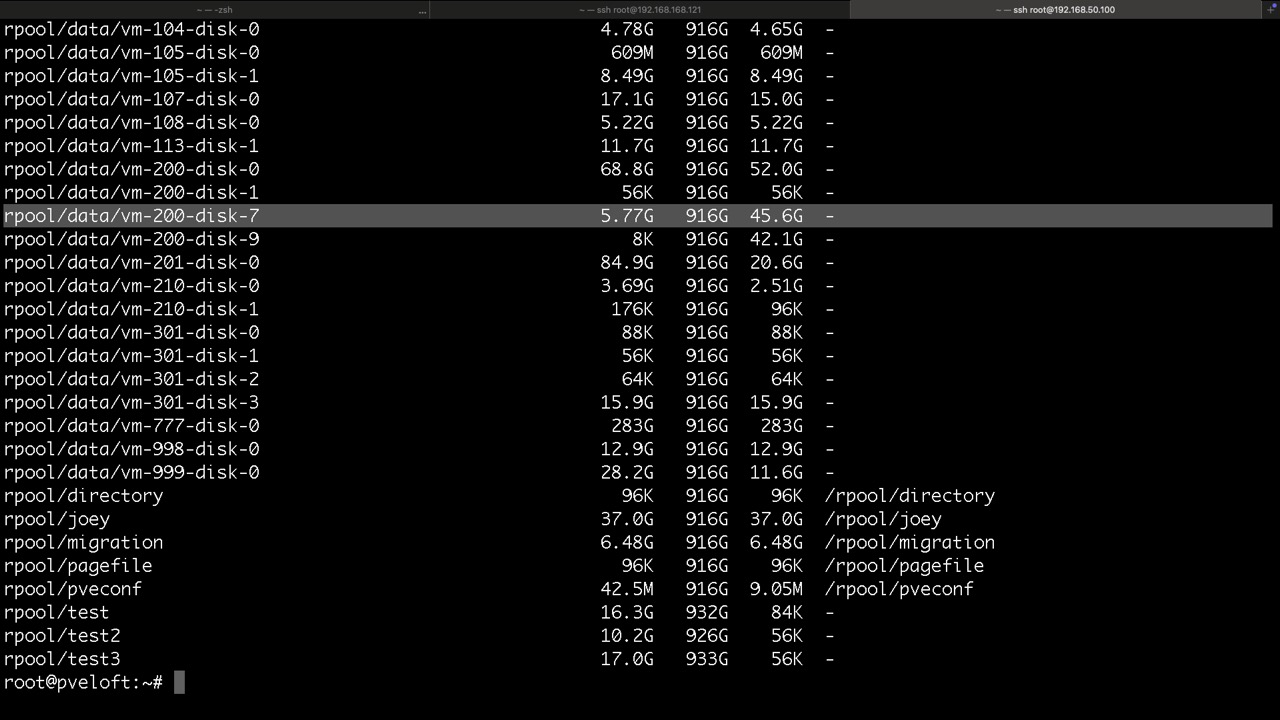
Proxmox legt seine Datasets für LXC so ab
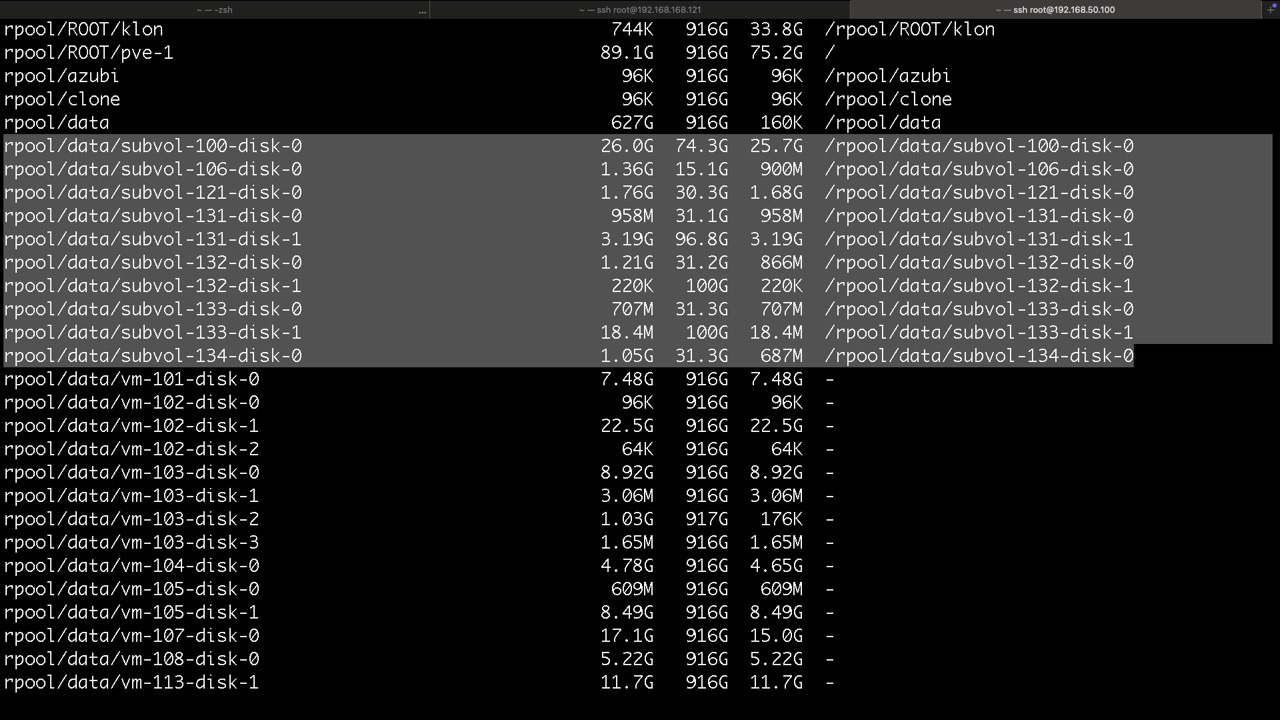
und so die ZVOLs für VMs mit KVM, hier findet man die virtuellen Disk und /dev/zvol...
Thin- und Thickprovisioning für Datasets und Volumes
Am Beispiel von Proxmox VE via GUI wird hier eine Thinprovision Festplatte für VM 301 mit 32GB und einer Standardblockgröße von 16k erzeugt. 8k sind nur bei Raid1 und 10 möglich. Hakt man den Thinprovision Haken nicht an, wird beim Erzeugen noch die Option -o refreservation=32G ergänzt. Diese macht bei ZFS mit Autosnapshots aber keinen Sinn
zfs create -s -b 16k -V 33554432k rpool/data/vm-301-disk-4
rpool/data/vm-301-disk-4 56K 1.17T 56K - #hier kein Mount sonder unter /dev/zvol/...
Bei LXC werden Datasets genutzt und der Platz via Reservierung genutzt, wobei bei der genutzten Refquota auch die Snapshotaufhebezeiten den Nettoplatz verkleinern, daher größer dimensionieren, gerne mal doppelt so groß
zfs create -o acltype=posixacl -o xattr=sa -o refquota=33554432k rpool/data/subvol-106-disk-1
rpool/data/subvol-106-disk-1 96K 32.0G 96K /rpool/data/subvol-106-disk-1 #hostzugriff möglich
Virtuelle Diskimages wie QCOW2, VMDK oder RAW-Dateien legt man üblicherweise nicht in Datasets, bestenfalls für NFS oder iSCSI Server
Snapshots
Snapshots können jederzeit erstellt oder gelöscht werden. Die Datasets und Volumes befinden sich immer in einem Livezustand der sich durch die Vektorkette der eventuell vorhandenen Snapshots ergibt. Entfernt man einen Snapshot, so verändert sich der Weg der Vektoren. Das Ganze geschieht fast ohne Last!
ZFS selbst bringt weder Workflows für Snapshotting, noch Replikationen mit. Es stellt nur die Werkzeuge bereit
Snapshots generiert man bei Proxmox offiziell mit der GUI manuell oder für Replikationen, jedoch leistet dieser Workflow nicht genug.
Daher nutzen wir...
apt install zfs-auto-snapshot -y
ZFS-AUTO-SNAPSHOT legt seine Verknüpfungen in alle Cronordner. Proxmox VE weiß erst mal nichts davon. Zu berücksichtigen ist hier lediglich daß wir den Pool nicht über 80% befüllen wollen. Gehen wir darüber hinaus, müssen wir in den Cronordnern die Verknüpfungen anpassen um die Aufhebezeiten zu reduzieren.
nano /etc/crontab #kann angepasst werden, die viertelstündlichen finden sich unter cron.d!
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.daily; }
47 6 * * 7 root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.weekly; }
52 6 1 * * root test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.monthly; }
cat /etc/cron.hourly/zfs-auto-snapshot
exec zfs-auto-snapshot --quiet --syslog --label=hourly --keep=96 // #also in dem Fall 96 Stunden
Wir empfehlen für den Start folgende Settings: Drei Monate, sechs Wochen, zehn Tage, 96h und 12 Viertelstunden
Damit kommt man auf ca. 2,5x- 3x so viele Daten wie belegt wären ohne Snapshots. Erfahrungswert.
Das wären pro virtueller Disk oder LXC Mountpoint etwa 127 Snaphots, bei 20 Disks über 2540.
Nicht davon abschrecken lassen, es geht auch easy fünfstellig, wenn die IO stimmt!
Die in PVE eingebaute Snapshotfunktion sollte nicht mit den Autosnapshots kombiniert werden.
Im Problemfall stoppen wir die VM, manipulieren was zu machen ist und starten sie wieder!
Der eigentliche Vorteil der Snapshots in der GUI ist die Notierung der VM Definition zur Zeit der Erstellung, was wir über ein Backup im hauseigenen Postinstaller kompensieren. Dort findet man die Historie der PVE Config
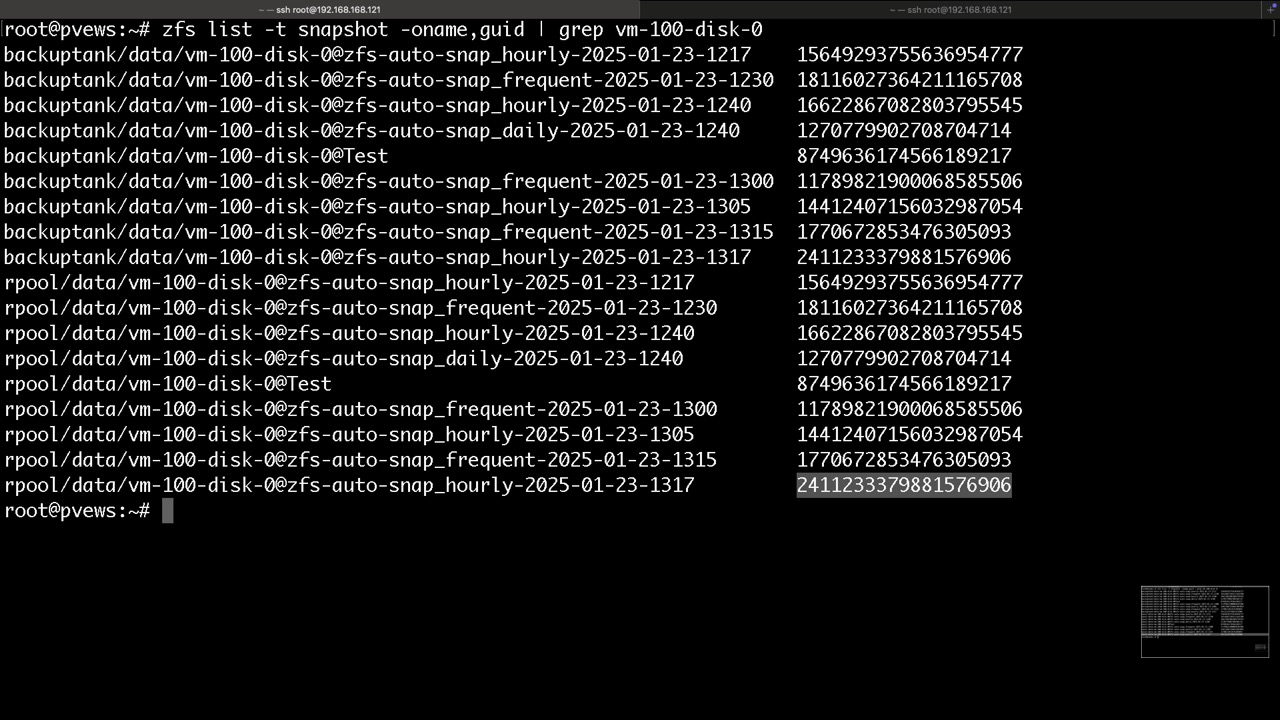
Kleines manuelles Beispiel, was für uns aber Z-A-S übernimmt
Snapshot
zfs snapshot tank/sub/datasetodervolume@snapshotname
Auflisten
zfs list -t snapshot tank/sub/datasetodervolume
VM oder LXC ausmachen
Rollback
zfs rollback -r rpool/data/vm-100-disk-0@Test #danach ist alles neuere weg!
VM oder LXC starten
Dynamik von Snapshots
Wir unterscheiden zwei Sorten von Datennutzung
- Zunehmende Datennutzung wie bei einem NAS
- Es kommt nur was dazu und wird selten gelöscht
- Viele Snapshots auf lange Zeit ändern nichts an der Gesamtnutzung des Pools
- Replikation außer Haus kann in kleinen Schritten passieren, da die Gesamtübertragung gleich groß ist
- Rotierende Datennutzung wie bei einem Datenbankserver
- Daten verändern sich permanent, wenig Zuwachs
- Viele Snapshots auf lange Zeit ändern brachial viel an der Gesamtnutzung des Pools
- Replikation außer Haus sollte in einem Schritt, ohne Zwischensnapshots passieren, da die Gesamtübertragung sonst ein vielfaches größer sein kann
- Nur essenzielle Wiederherstellungspunkte sollten aufgehoben werden um das System nicht unnötig zu befüllen
Dynamik von Snapshots
Dank ZFS kann man langfristig Replikationen inkrementell vornehmen, jedoch dauert die erste Replikation natürlich länger, wenn schon Datenbestand da war
Übliche Vorgehensweise einer Datenübertragung
PC NTFS>SMB> Datei > SAMBA Server BTRFS LVM > EXT4 Datei = Konsistent? Bitrod?
Zu viele Köche verderben die Köchin
Funktion von Snapshotreplikation
Von ZFS zu Datei, was wenig Praxis findet
zfs send tank/dataset@snapshot > datei.zfs
zfs recv tank < datei.zfs
Von ZFS zu ZFS, was üblich ist
zfs send | zfs recv #laufen immer gleichzeitig
zfs send rpool/data/vm-100-disk-0@Test | zfs recv -dvF backuptank
#überträgt den Zustand Test auf ein lokalen weiteren Pool, wobei das zfs Tool immer doppelt läuft
Pushreplikation
zfs send -pvwRI rpool/data/vm-100-disk-0@Test rpool/data/vm-100-disk-0@zfs-auto-snap_hourly-2025-01-23-1317 | zfs recv -dvF backuptank
#Fortschritt, Infos, Rohdaten plus Historie, ideal für verschlüsselte Volumes, erspart das De- und Komprimieren
Workflow
- Erzeugen eines Datasets oder Volumes
- Snapshot auf Dataset oder Volume ausführen
- Übertragung des Snapshotzustands auf Ziel, optional mit Zwischenständen
Trojanerproblem: Wer auf Quelle sitzt kann Pushziele löschen
Lösung: Pullreplikation, ähnlich Backupsoftware, Transport SSH, Daten ZFS
Quelle |> Pullserver
zfs recv | ssh root@quelle zfs send #Pull Replikation via SSH
Von PVE zu PVE, was uns zu wenig ist
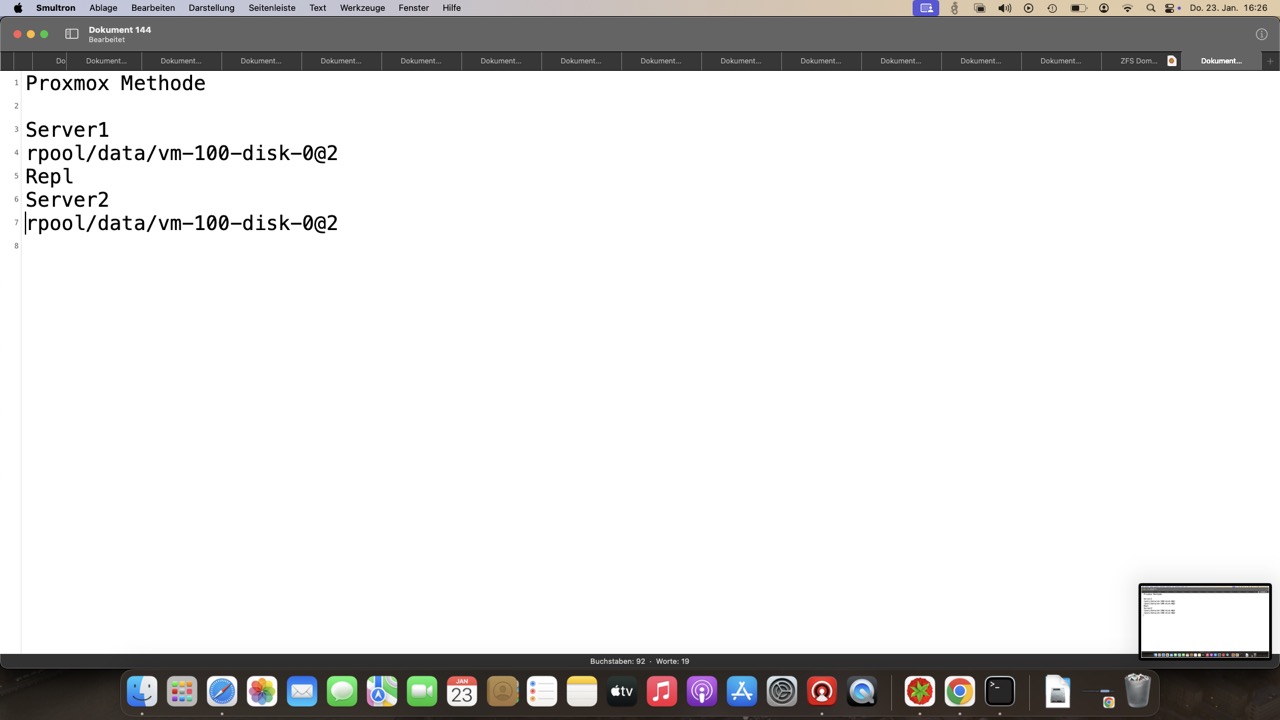
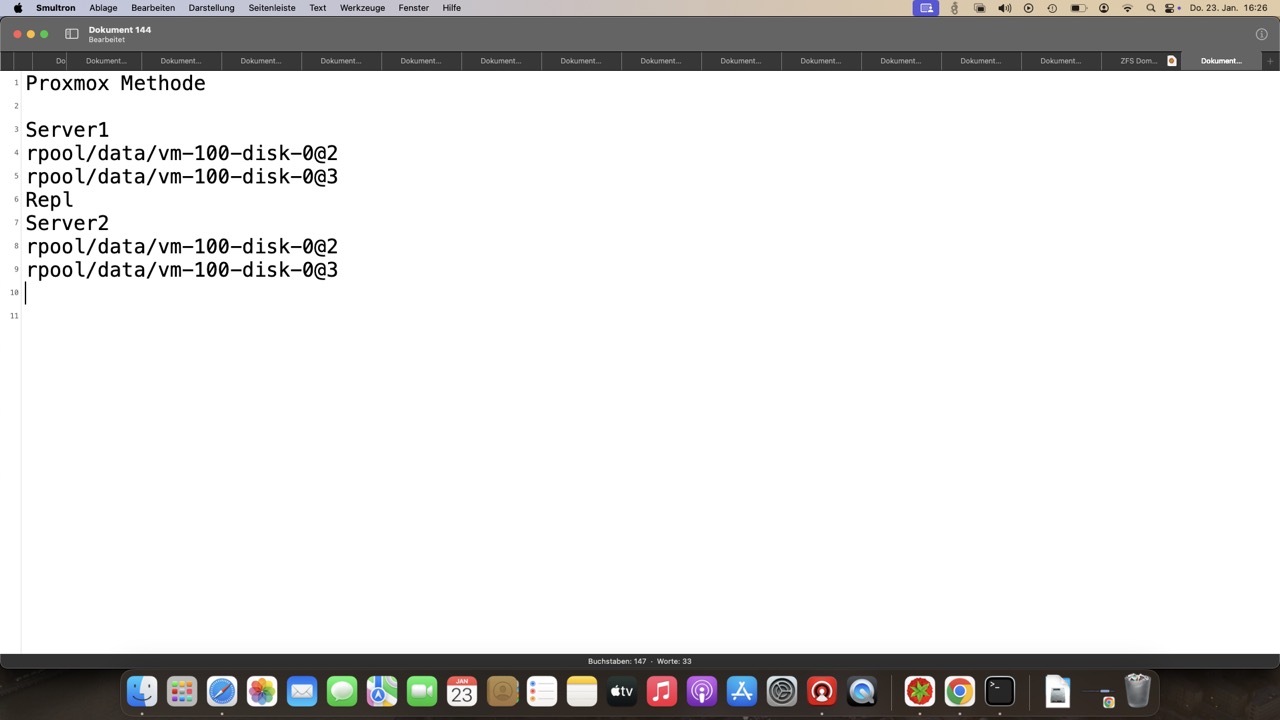
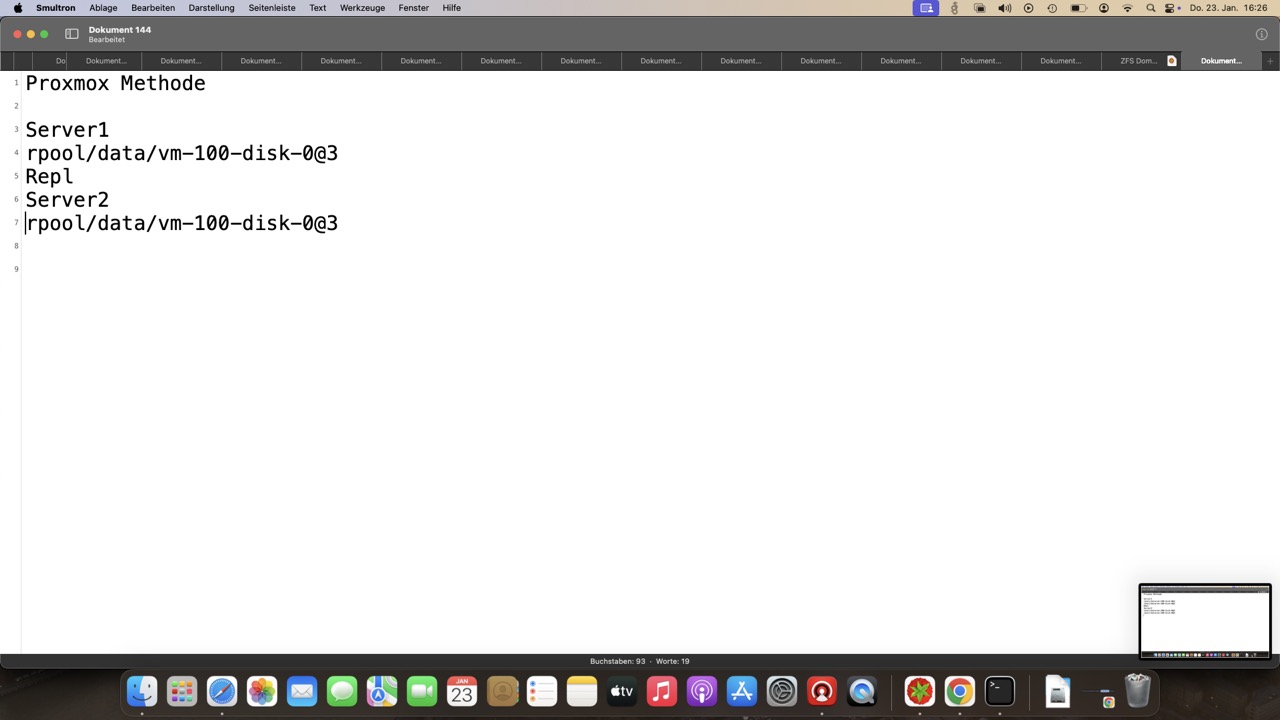
Proxmox baut selbst keine Notfallpunkte auf und nutzt ZFS nur als Transport, nimmt jedoch manuelle und automatisierte Snapshots mit, auch von Z-A-S!
Weitere Kopien per ZFS sind nur per Pushverfahren möglich, was ideal für Angreifer ist wenn sie alles löschen möchten. Ein Backupserver ist hier unverzichtbar, bei Pullreplikation gehts ggf. auch ohne. Außer Haus ist es nicht möglich ein ZFS Replikat zu senden, da sich der Partner im lokalen Cluster befinden muss!