ZFS Grundlagen am Beispiel Proxmox VE(Stand Dezember 2025)
Der Verfasser des Artikels, Christian-Peter Zengel, hat zum Zeitpunkt des Artikels ca 18 Jahre Erfahrung mit ZFS und Proxmox. Er betreibt aktuell ca 150 Systeme mit Proxmox und ZFS
Das Einsatzgebiet geht von Standaloneinstallation bis zu ca 10 Hosts im Cluster. Es ist keine produktive Ceph Expertise vorhanden, jedoch wird intensiv an einer Hauslösung gearbeitet.
In der Praxis zeigt sich aber ZFS einfacher, vielseitiger, schneller und günstiger als CepH zu sein.
Dieser Dokumentation basiert auf diesem online Kurse von cloudistboese.de
24. + 26.11.2025 (13.00 Uhr bis 17.00 Uhr) - ZFS Grundlagen (Onlinekurs)
Diese Kurse sind ca alle sechs Monate online buchbar. Das Wiederholen der Onlinekurse, wie auch der Zugriff auf Aufzeichnungen sind kostenlos!

ZFS ist die perfekte Grundlage für kleine und mittlere Systeme um gegen Ausfälle, Dummheit anderer und Erpressungstrojanern ideal aufgestellt zu sein.
In diesem Kurs erhalten sie Grundkenntnisse für Systeme wie Proxmox, TrueNAS oder ähnliche Systeme.
Der Fokus liegt auf der Technologie und der permanenten Sicherheit im Umgang mit Daten, Linux und dem Terminal.
Themen:
- Begrifflichkeiten und Überblick
- Aufbau von Raids mit zpool
- Basisfunktionen am Beispiel von Proxmox VE
- Erklärung und Beispiele Snapshots und Rollbacks
- Praxisbeispiele Replikation
- Prüfung der Replikationen
- Weitere Features die das Leben massiv erleichtern
Nach diesem Kurs bist Du bei Ausfällen und Datenverlust vor dem Schlimmsten geschützt und in Minuten wieder produktiv!
Erstellung eines Raids mit zpool
So erstellt Proxmox VE seinen ZFS Raid
zpool create -f -o cachefile=none -o ashift=12 rpool mirror disk1 disk2
Destruktives Anlegen (-f), kein automatisches Importieren beim Start (-o cachefile=none)
-o ashift=12 ist für 4k Festplatten, ashit=9 für 512e Disks, wobei man mit 12 nichts verkehrt macht
rpool ist der Name vom künftigen Pool, mirror der Raidlevel und die Disks wurden zweifelsfrei über Ihre ID definiertOptionen für Raidlevel wären noch: ohne als Stripe, raidz, raidz2 oder raidz3, also Raid Level 5-7
Im aktuellen Kurs verwenden wir einen älteren Supermicro Server mit 24 Einschüben plus zwei NVMe, damit wir alles abbilden können. Die Verwendung bereits benutzter Disks, die teilweise nicht getestet wurden, wird bald die Notwendigkeit von ZFS bestätigen! Die NVMe sind nach ca zwei bis drei Jahren Cachebetrieb schon am Ende ihrer Laufleistung!
Daher immer Enterprise NVMe und natürlich ECC RAM benutzen, das spart eine Menge Ärger!
Sollten sich dennoch Daten auf Ihren Datenträgern befinden taugt die Wipe Funktion in PVE gut zur Wiederinbetriebnahme belegter Disks, es sei denn es war etwas mit LVM oder CepH auf den Disks.
Solche Datenträger sollte man z. b. mit nwipe extern erst mal löschen.
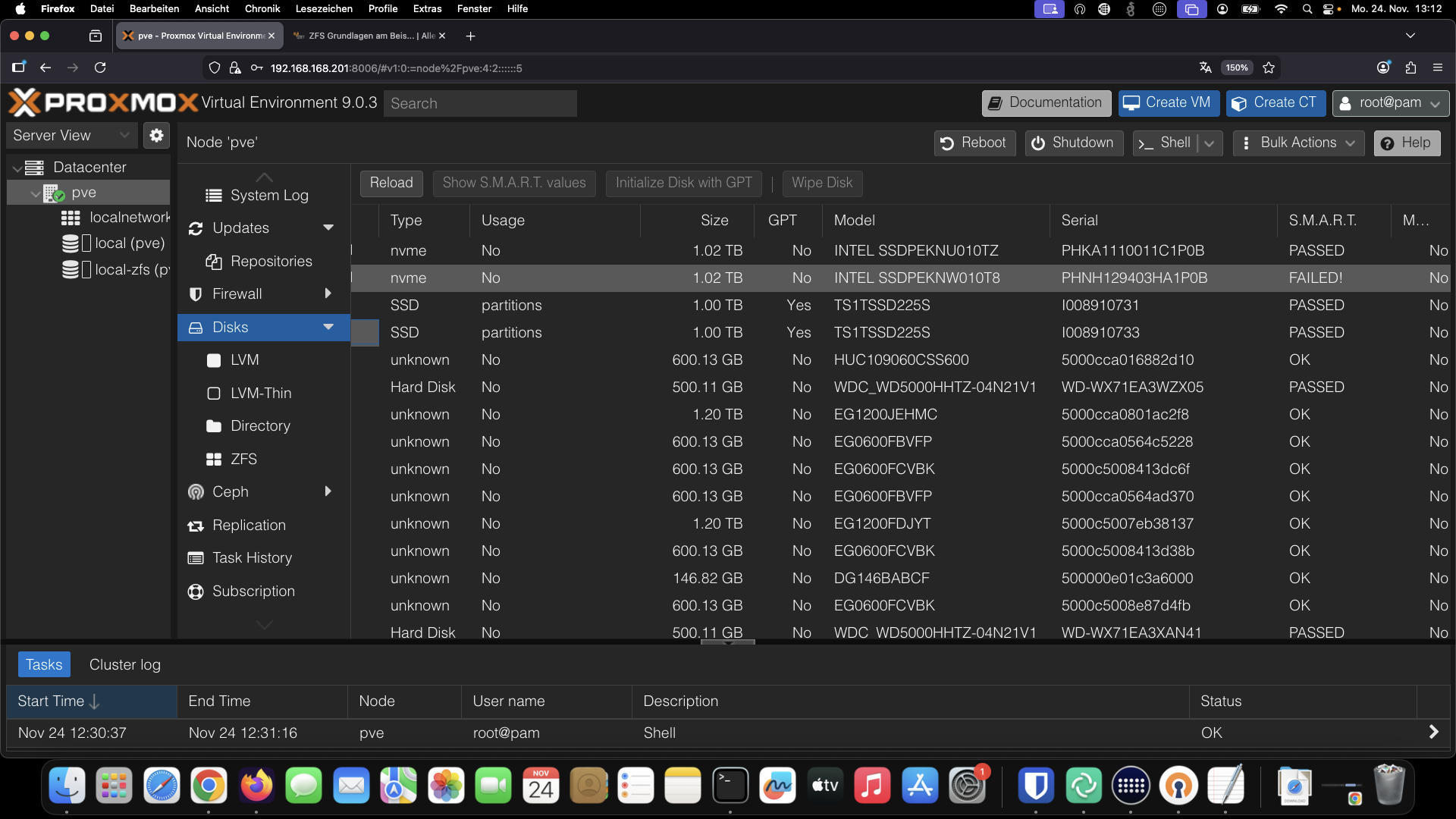
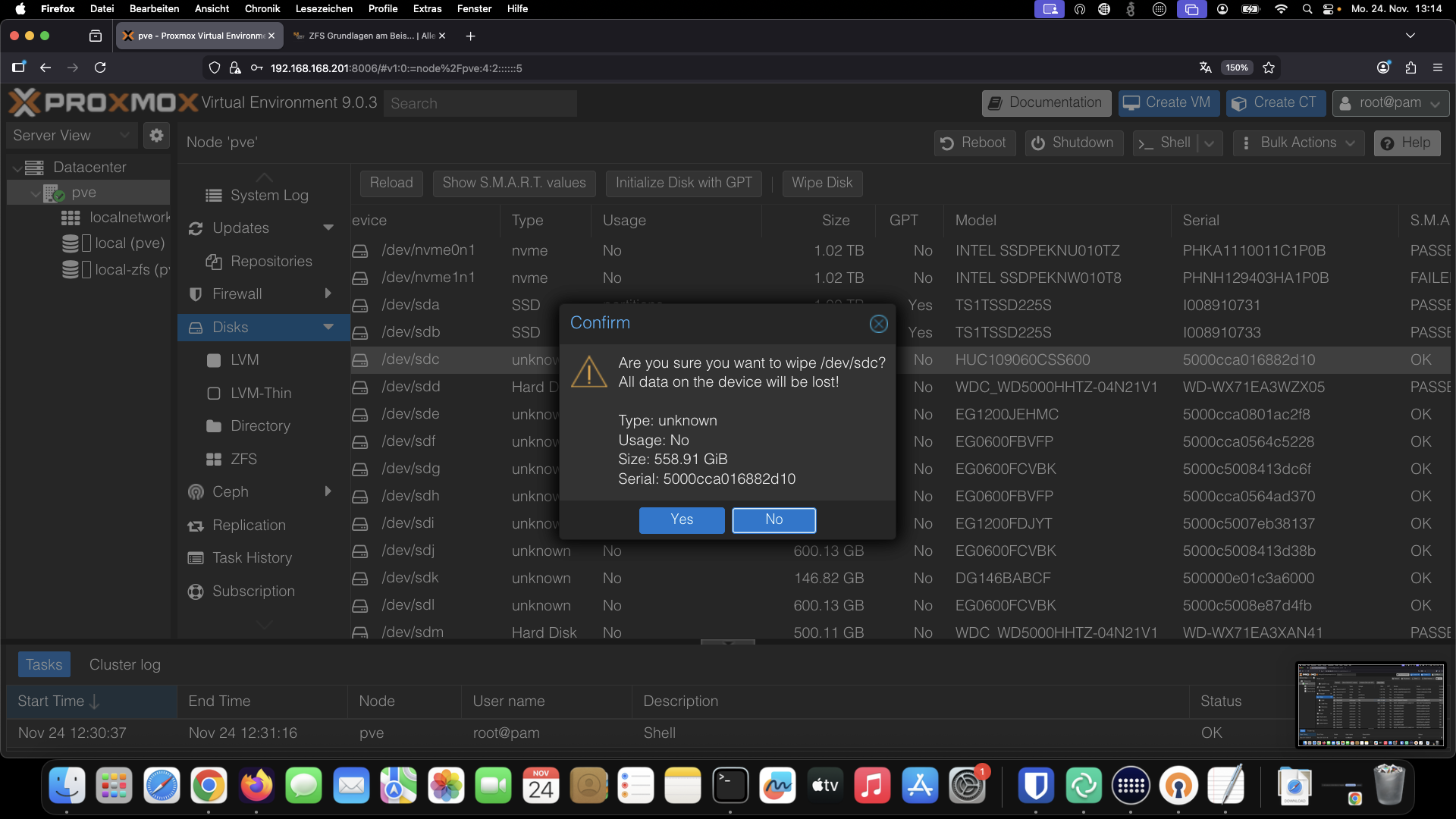
Proxmox, also Debian Linux, bootet aus lizenztechnischen Gründen nicht direkt von ZFS.
Daher ist zu beachten daß immer genügend Bootdisks mit einem dreiteiligen Partitionslayout vorhanden sind. Würde man im Laufe der Zeit die beiden dritten Partitionen gegen komplette Disks ersetzen, wäre nichts mehr zum für den Systemstart vorhanden. Bei Proxmox VE übernimmt diesen Teil das Tool proxmox-boot-tool (format/init/status) der auf die zweite Partition angewendet wird. Die erste Partition enthält noch Grub für Bios Boot, die Dritte dann das eigentliche ZFS mit Proxmox VE.Hierzu empfehle ich unsere Kursreihe Proxmox Produktiv mit ZFS betreiben!
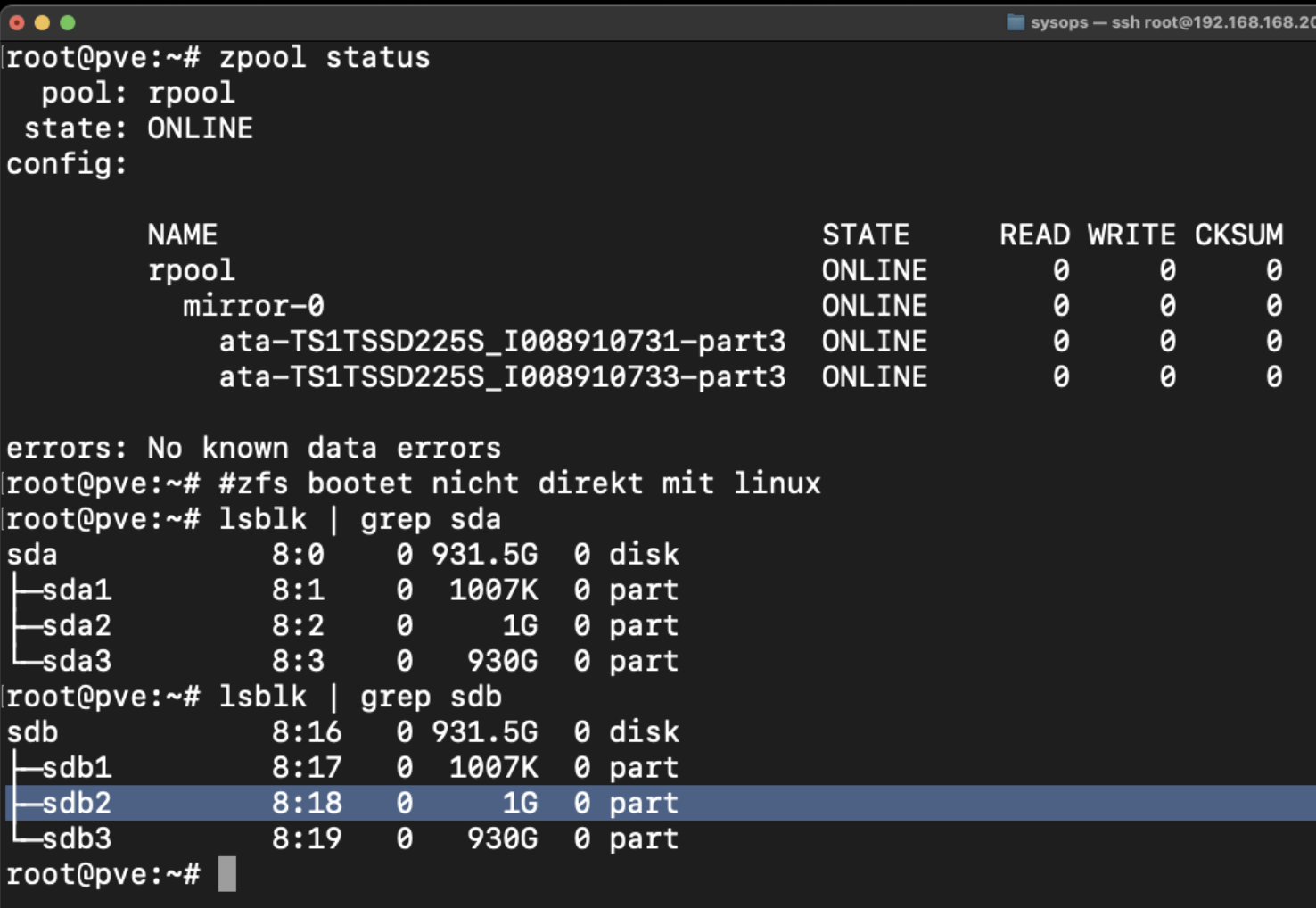
Ermittlung der Laufwerke mit der Kommandozeile
Für den Betrieb empfehlen sich einige Werkzeuge die eventuell nicht enthalten sind, daher installieren wir diese über unseren Postinstaller oder per Hand
apt install lshw iotop
#Detailierte Übersicht aller Laufwerke
lshw -class disk
#Liveansicht beim Enschieben von Platten
dmesg -Tw #time follow
#Auflösung von symbolischen Links im System - Hier werden teilweise mehrere Namenskonventionen angeboten, pro Disk und pro Parition
ls -althr /dev/disk/by-id
Beispiel lshw
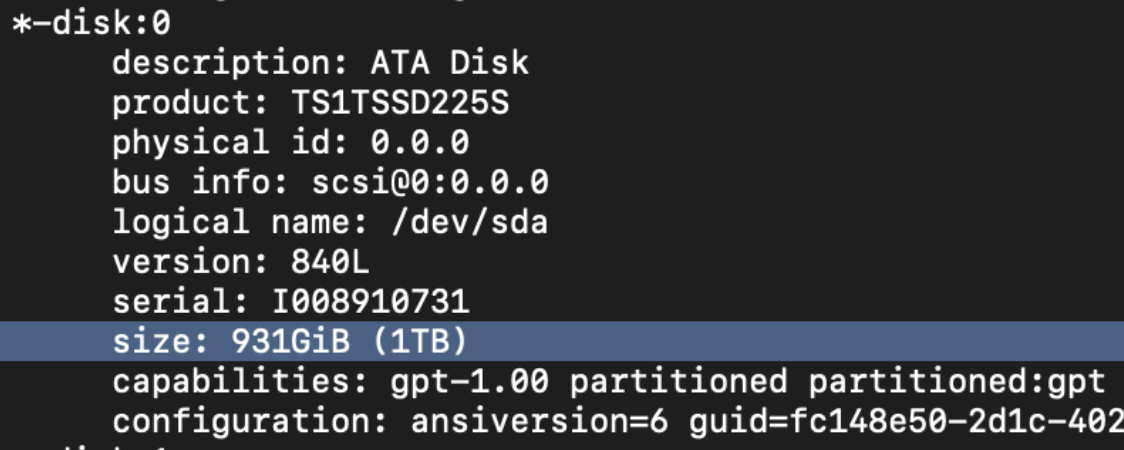
Beispiel by-id Ordner

Die Optionen der Raidanlage
Die wichtigsten Parameter sind RAID Level, Compression und Ashift. Alle drei Parameter können bei Fehlentscheidungen zu langfristigen Konsequenzen führen.
Beispiel Fehlentscheidung Raidlevel
- Mirror oder Striped Mirror (Raid 10) sind niemals eine falsche Entscheidung, jedoch verlieren wir hier immer 50% unserer Kapazität. Der entscheidende Vorteil bei einer Erweiterung ist daß man nur zwei Platten aus einem Spiegel ersetzen muss. Beim einfachen Mirror kann eine verdächtige Platte auch einfach entnommen und in die Schublade gelegt werden. Beim Austausch von Disks kann man auch einfach eine dritte Platte einspiegeln und später die Alte entfernen, so verliert man nie den Schutz beim Tausch und kann die alte Disk archivieren.
- Vorteile: Schnell, einfach, problemlos
- Nachteile: Hoher Verlust der Kapazität, 50% immer für Spiegel
- Optionen: Bei SATA / SAS Raids gut mit Cache und LOG per NVMe zu beschleunigen
- RaidZ Level 1-3 kann bei drehenden Festplatten eine fatale Entscheidung sein. Die Nutzlast entspricht immer der Anzahl der Platten minus ein bis drei Paritäten. Also RaidZ2 entspricht Raid6 und bei acht Platten würde die Kapazität von zwei Platten für Parität verloren gehen, bei RaidZ1 eine und natürlich bei RaidZ3 drei.
- Vorteile: Mehr Platz, mehr Sicherheit, Erweiterbarkeit mit einzelnen Disks oder weiteren VDevs
- Nachteile: Für VMs und LXCs nur bedingt als Datengrab, NAS, Fileserver geeignet
- Optionen: Bei SATA / SAS HDDs und SSDs sind diese Raids gut mit Cache und LOG per NVMe zu beschleunigen. Zusätzlich besteht auch die Möglichkeit eines Special Devices, welches Metadaten und kleine Blöcke auf SSDs oder NVMes ablegt.
- Pool aus mehreren RaidZ-VDev kann als Kompromiss zwischen Platz und Leistung gewertet werden. Eine Vergrößereung des Pools ist dann an mehreren Stellen möglich
- Vorteile: Mehr Platz, mehr Sicherheit, Erweiterbarkeit mit einzelnen Disks oder weiteren VDevs und schneler als ein RaidZ mit nur einem VDev bei gleicher Anzahl von Disks
- Nachteile: Für VMs und LXCs nur bedingt als Datengrab, NAS, Fileserver geeignet
- Optionen: Bei SATA / SAS HDDs und SSDs sind diese Raids gut mit Cache und LOG per NVMe zu beschleunigen. Zusätzlich besteht auch die Möglichkeit eines Special Devices, welches Metadaten und kleine Blöcke auf SSDs oder NVMes ablegt.
- Stripe und dRaid machen in diesem Umfeld keinen Sinn und werden daher nicht behandelt
Virtuelle Maschinen im Normalfall nie auf drehende Disks mit RaidZ ablegen. Als Kompromiss kann man gut SATA RaidZ plus Cache & LOG Beschleunigung verwenden um Platz zu gewinnen
Die Analge von Raids per Proxmox ist möglich, jedoch ist man mit der Konfiguration per Kommandozeile viel flexibler!
Beispiel Fehlentscheidung Ashift
Hier etwas technischer Hintergrund im Vorfeld
Bei ZFS bezeichnet ashift die Blockgröße (Sektorgröße), mit der ZFS intern auf einem vdev arbeitet.Üblicherweise arbeiteten wir früher mit ashift=9 (512b) oder ashift=12 (4096b, also 4k)...
Daher aktuel immer ashift=12 nehmen um alle aktuell angesagten Disks in allen Raidlevel zu unterstützen.
Setzt man diesen Wert oder auch den volblocksize Wert kleiner als 16, schreibt zfs einzelne Blöcke auf mehr als Einen!Die Konsequenz sind massive Leistungseinbusen und Platzverschwendung von bis zu 50%!
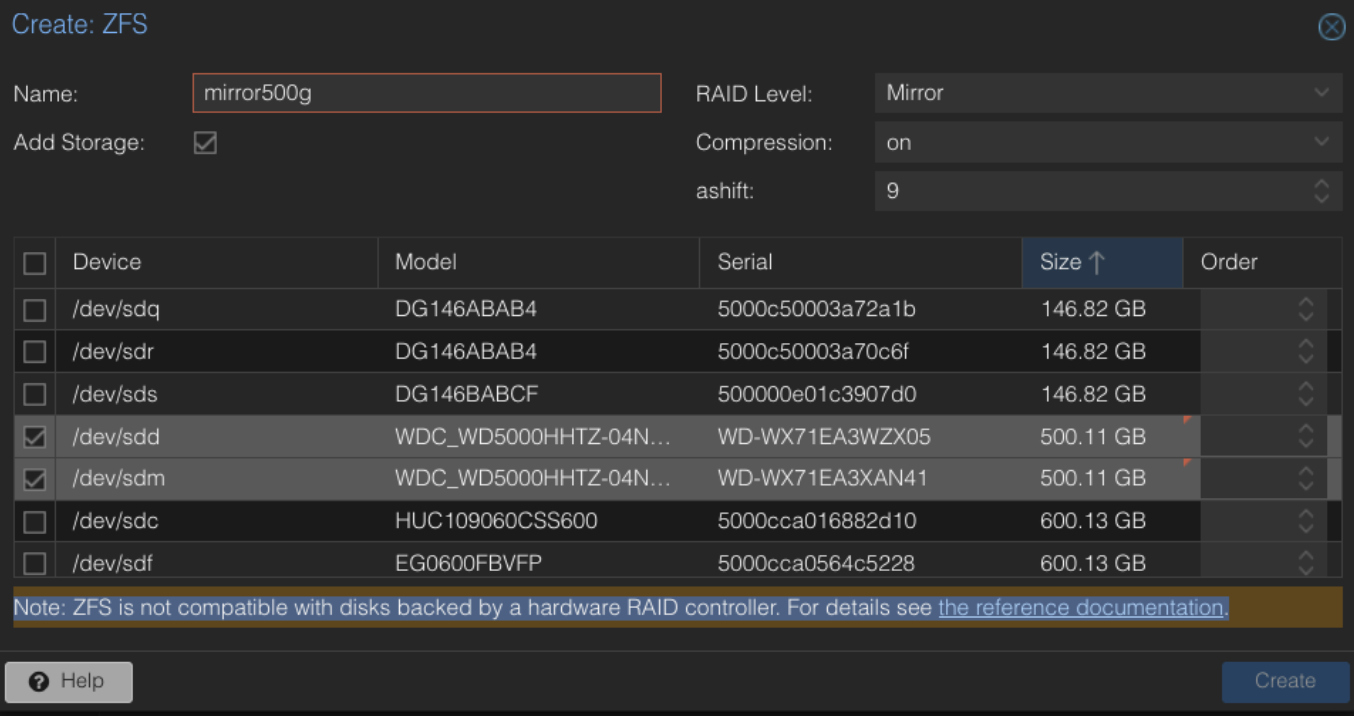
Beispiel der unspektakulären Raidanlage unter ProxmoxVE
Nach der Anlage eines Raid mit ProxmoxVE empfiehlt sich die Basis nicht wie hier auf mirror500g zu setzen, sondern die zu erwartenden Dateisysteme und Volumes zu strukturieren und dann dort den Proxmox Storage zu definieren
zfs create mirror500g/data zfs create mirror500g/clone zfs create -o com.sun:auto-snapshot=false mirror500g/repl #die option sorgt dafür daß das Tool zfs-auto-snapshot hier nicht arbeitetDanach den Storage unter Cluster in ProxmoxVE definieren, z. b. als mirror500g-data
Beispiel Fehlentscheidung Compression
Kompression kann immens viel Platz sparen, aber auch nur da wo unkomprimierte Daten liegen.
Grundsätzlich nehmen wir inzwischen compression=on, früher compression=lz4.
Mit beiden Einstellungen sparen wir oft mindestens ein Drittel der Daten und haben keine spürbaren Geschwindigkeitseinbußen.
Im Zweifelsfall compression=off
Praxis Raidanlage
Mit dem Parameter zpool create -n bekommt man als dry-run erst mal eine Vorschau!
Überlege Dir gut ob die Disks eventuell vorher paritioniert werden müssen, z. B. für Proxmox Boot oder Mischnutzung bei z. B. Cache/Log auf selbem Datenträger
ashift=12 ist inzwischen default
compression=off ist ebenfalls default!
Stripe, also Raid0
zpool create -f test wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
Mirror, also Raid1
zpool create -f test mirror wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c
Striped Mirror, also Raid10
zpool create -f test mirror wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c mirror wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 mirror wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
RaidZ, also Raid 5, Nettoplatz x-1
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
RaidZ2, also Raid 6, Nettoplatz x-2
zpool create test raidz2 wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 wwn-0x5000cca01a8417fc
RaidZ-0, also Raid 5-0, Nettoplatz x-2, in diesem Beispiel
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
oder mit Spare, wenn Du davon nicht booten musst
zpool create test raidz wwn-0x5000cca01a72ded4 wwn-0x5000cca01a7b1e2c wwn-0x5000cca01a83a61c raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8 spare wwn-0x5000cca01a8417fc
Erweiterung eines RaidZ zum RaidZ-0
zpool add -n test raidz wwn-0x5000cca01a832d24 wwn-0x5000cca01a83331c wwn-0x5000cca01a7495b8
Caches und Logdevices
Vorsichtig formuliert, Lese- und Schreibcache
First Level Cache, sog. ARC kommt aus dem RAM und bekommt idealerweise ca. 1GB für 1TB Nettodaten
Second Level Cache wird als Cachedevice als Partition auf einer schnelleren Disk als der Pool hat bereitgestellt, z. B. am idealsten mit NVMe
zpool add test -n cache sdl
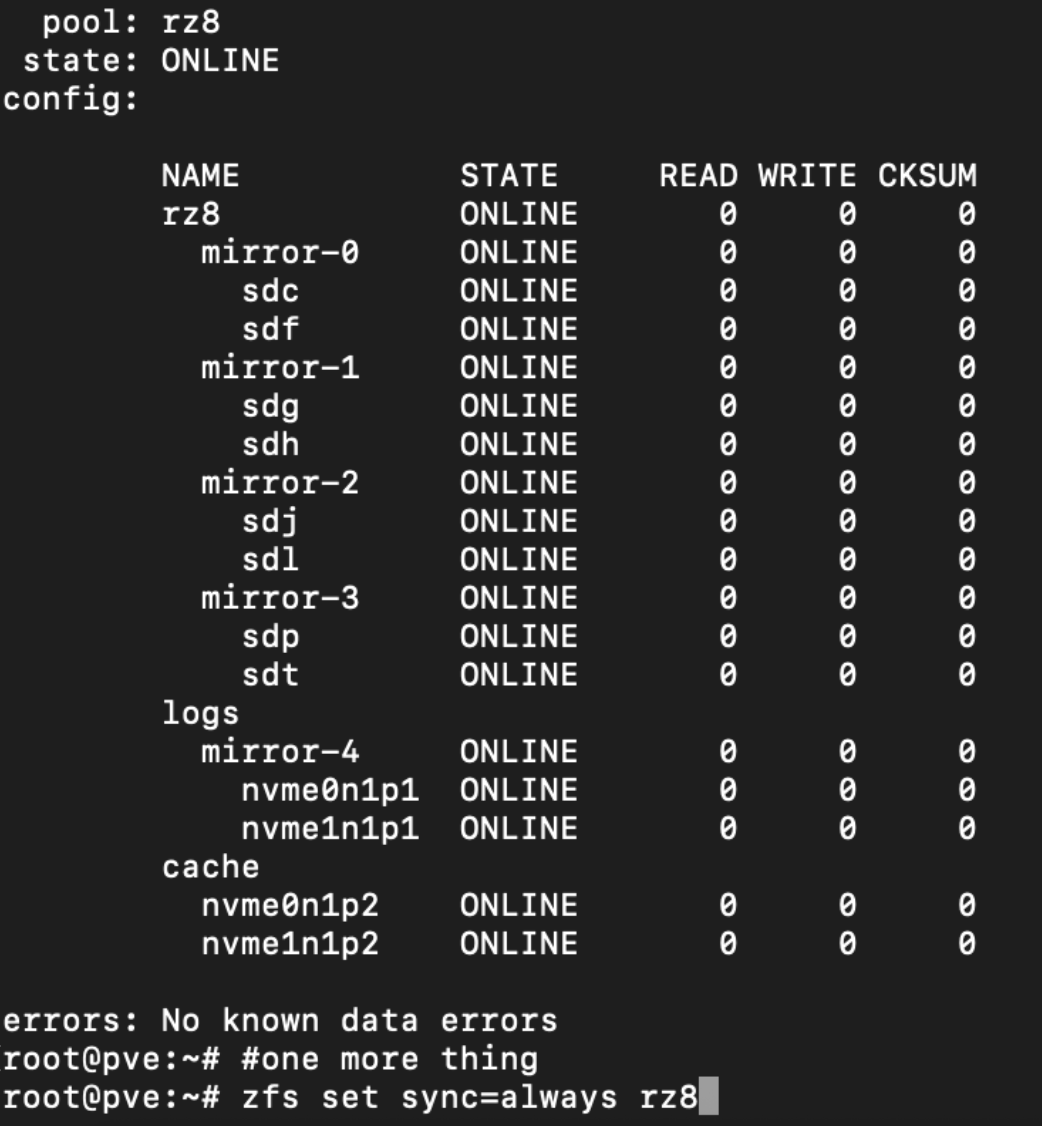
Logdevice (Writecache muss gespiegelt werden)Damit der Log auch genutzt wird muss man noch mit zfs set sync den cache aktivieren
zpool add test -n log mirror sdl sdk
zfs set sync=always test
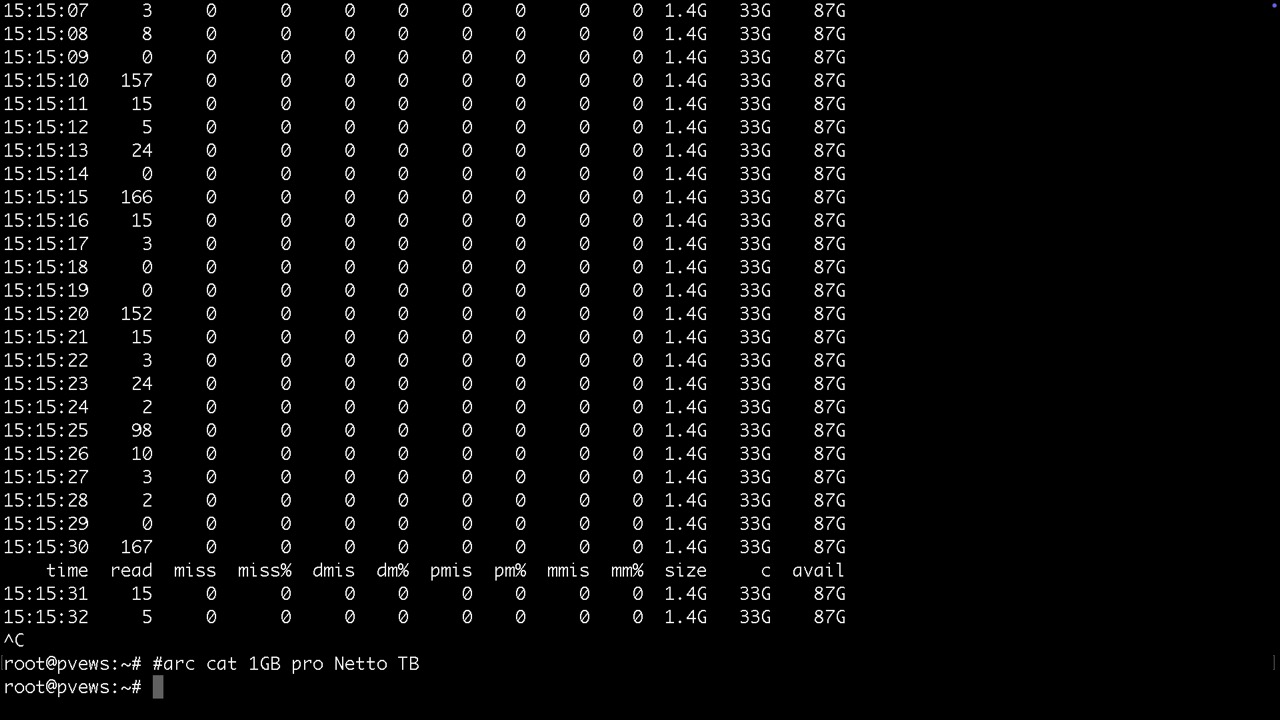
Arc wird mit "arcstat 1" ausgelesen, er wird bei der Installation festgelegt oder später unter /etc/modprobe.d/zfs.conf geändert. update-initramfs -u macht das dann persistent und aktiviert die Änderungen beim nächsten reboot.Zur Laufzeit ändert man den Firstlevelcahce mitCache- und Logdevices mit zpool iostat 1
echo 2147483648 > /sys/module/zfs/parameters/zfs_arc_max # ca 1GB pro Raidnetto x 1024 x 1024 x 1024
echo 1073741824 > /sys/module/zfs/parameters/zfs_arc_min # die Hälfte vom Max als Praxisempfehlung
free -h && sync && echo 3 > /proc/sys/vm/drop_caches && free -h #haut den Cache eben mal weg wenn RAM voll ist
arcstat 1
Hier ein Beispiel für einen idealen HDD Raid10 mit Cache(Stripe) und LOG (Mirror)
Beispiel Special Device, zwingend als Mirror!
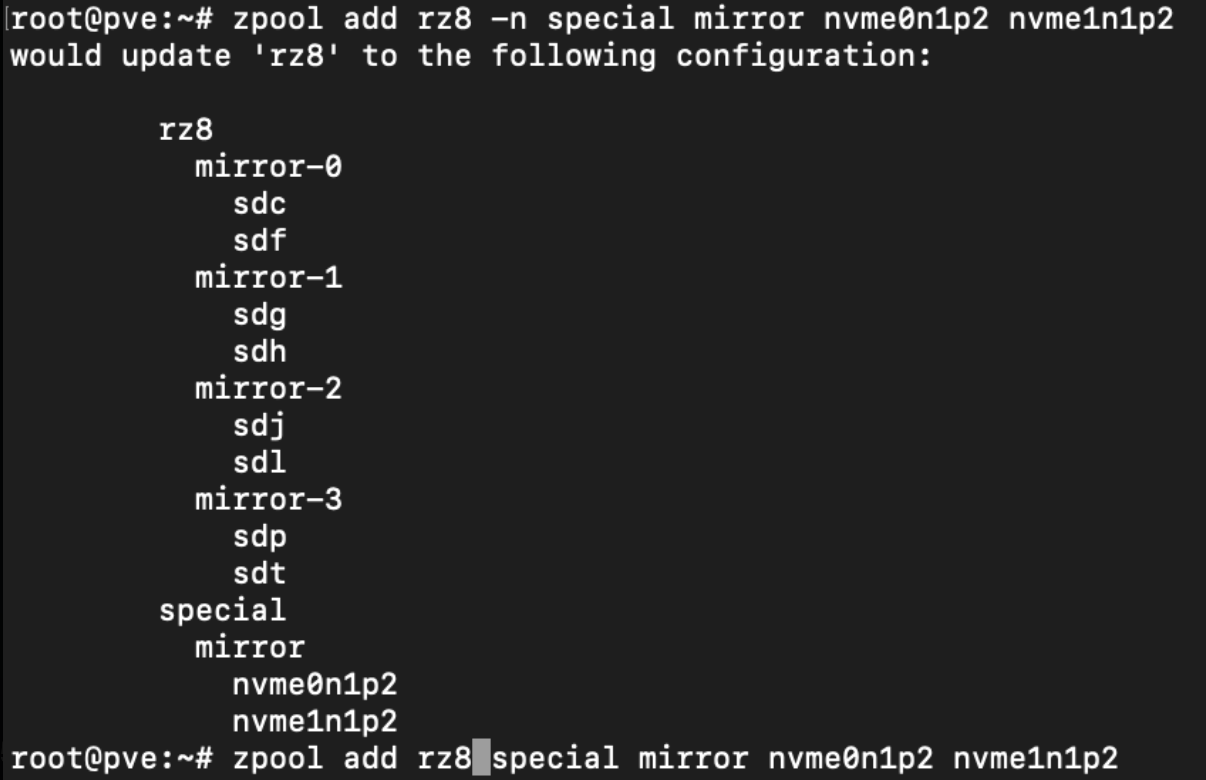
Sinnvoll wirksam wird es erst nach der Definition der Blocksize die auf die NVMe gehen soll, also vermutlich so grob 64k und kleinere Blöcke
Im VM-Betrieb konnten wir durch Special Device keine Leistungssteigerung feststellen, nur bei Fileserver und LXCs

Beispiel arcstat 1
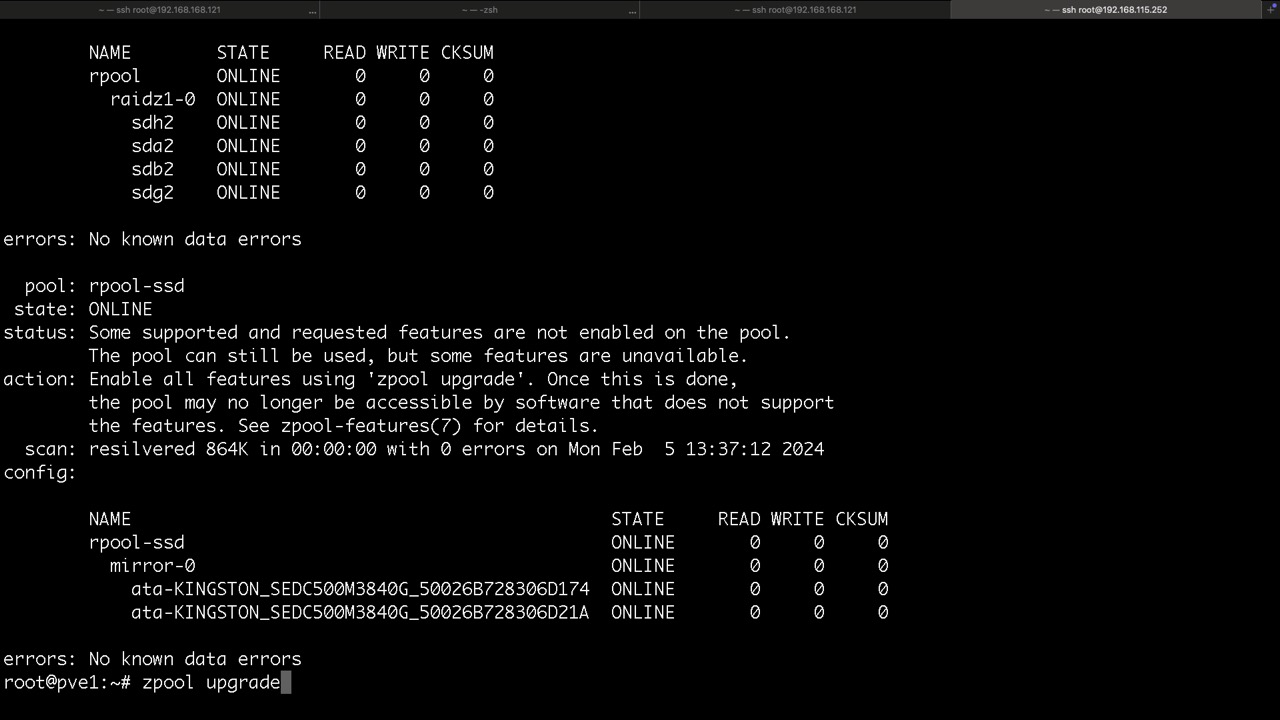
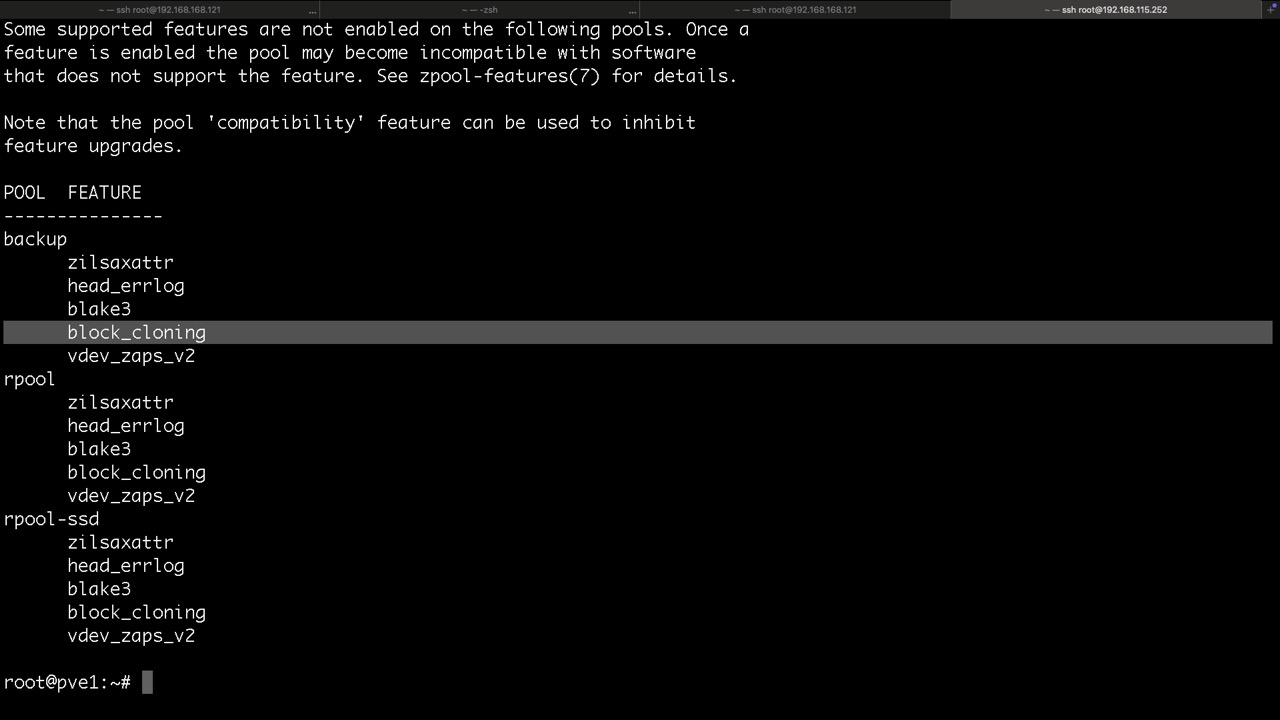
Erweiterung der Funktionen des Pools
zpool status meldet neue Funktionen im ZFS und kann leicht und schnell mit
zpool upgrade -a
erledigt werden
Jedoch würde ich in jedem Fall empfehlen zu prüfen ob meine Notfall ISO diese Funktionen bereits unterstützt!
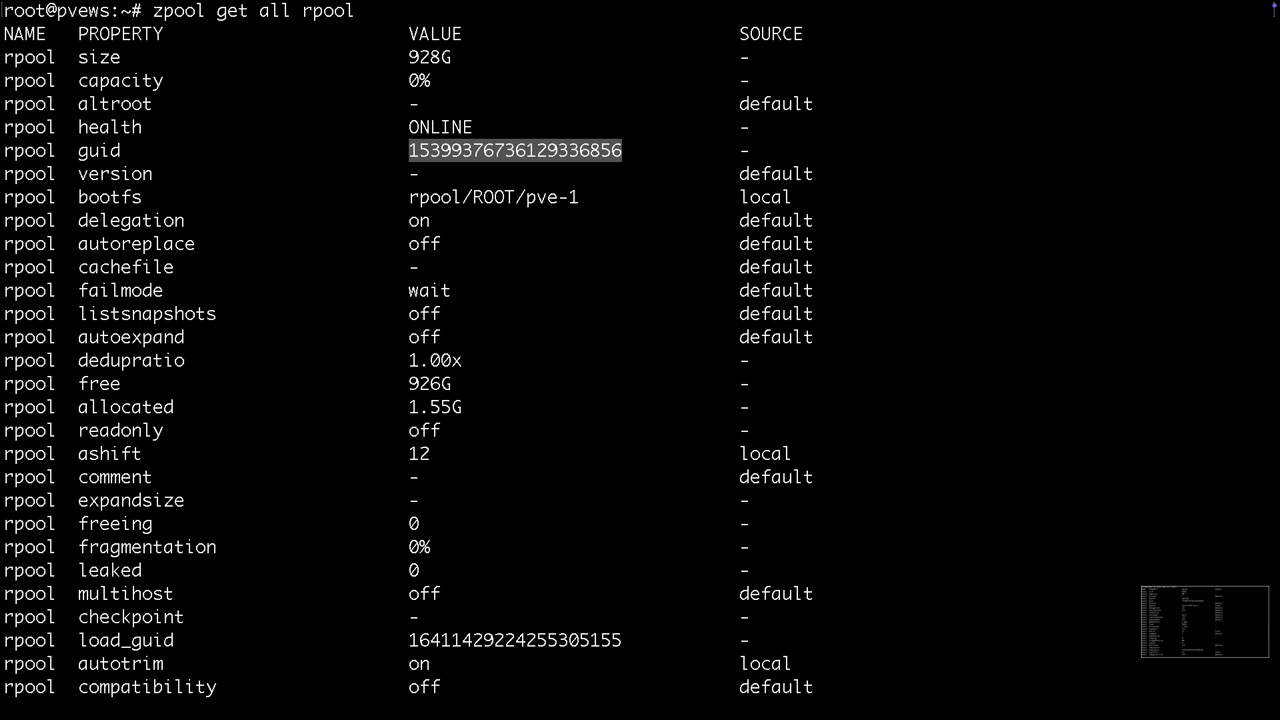
Für das Auslesen der Parameter von Pools, Volumes, Datasets und Snapshots gibt es den Parameter get
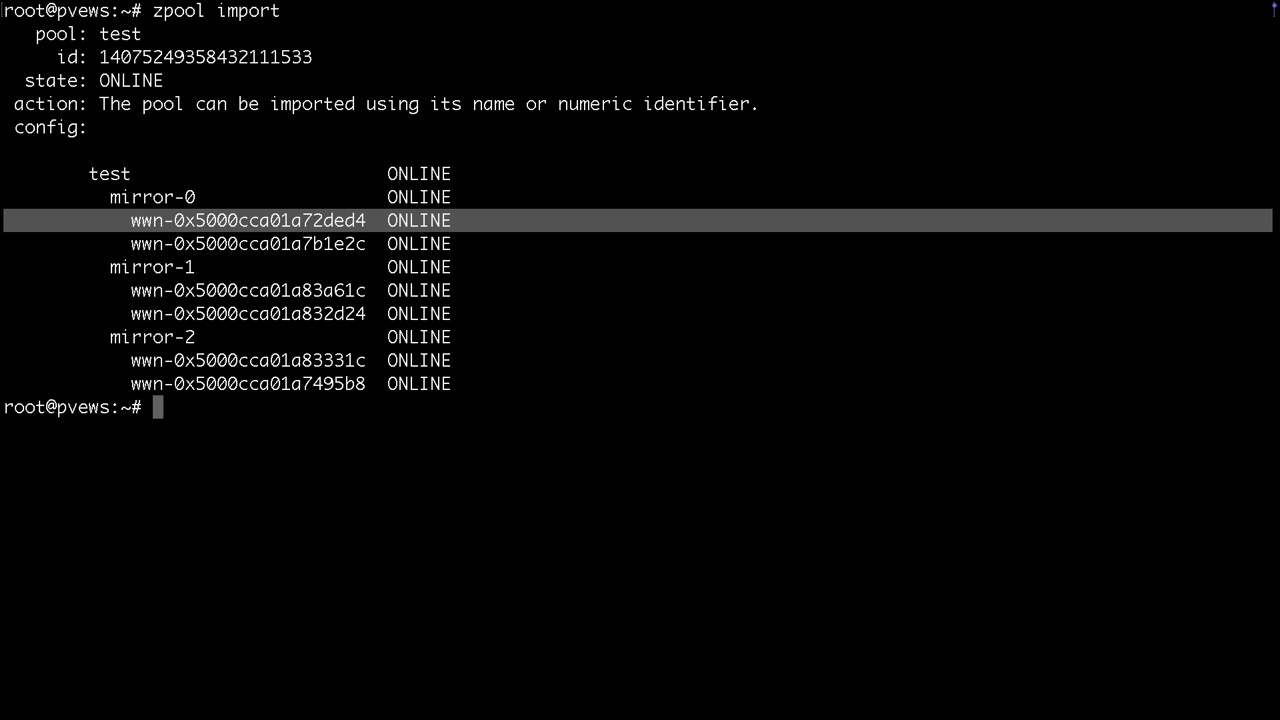
Bereitstellen und entfernen von Pools ohne löschen
zpool import #zeigt was es zum importieren, also bereitstellen gibt zpool import poolname #oder -a für alle importiert den Pool oder alle verfügbaren PoolsAm elegantesten importiert man den Pool über
zpool import -d /dev/disk/by-iddamit man hinterher nicht sda, sdb, sondern die Bezeichner im Status sieht
Nach der Bereitstellung würde man hier lediglich einen Mountpoint /test finden, bei TrueNAS /mnt/test. Dazu noch die Systemdatasets vom Proxmox selbst. Danach legen wir gleich mal ein Dataset namens dateisystem und ein Volume namens volume an.
Anlage eines ZVOL (unter /dev zu finden)
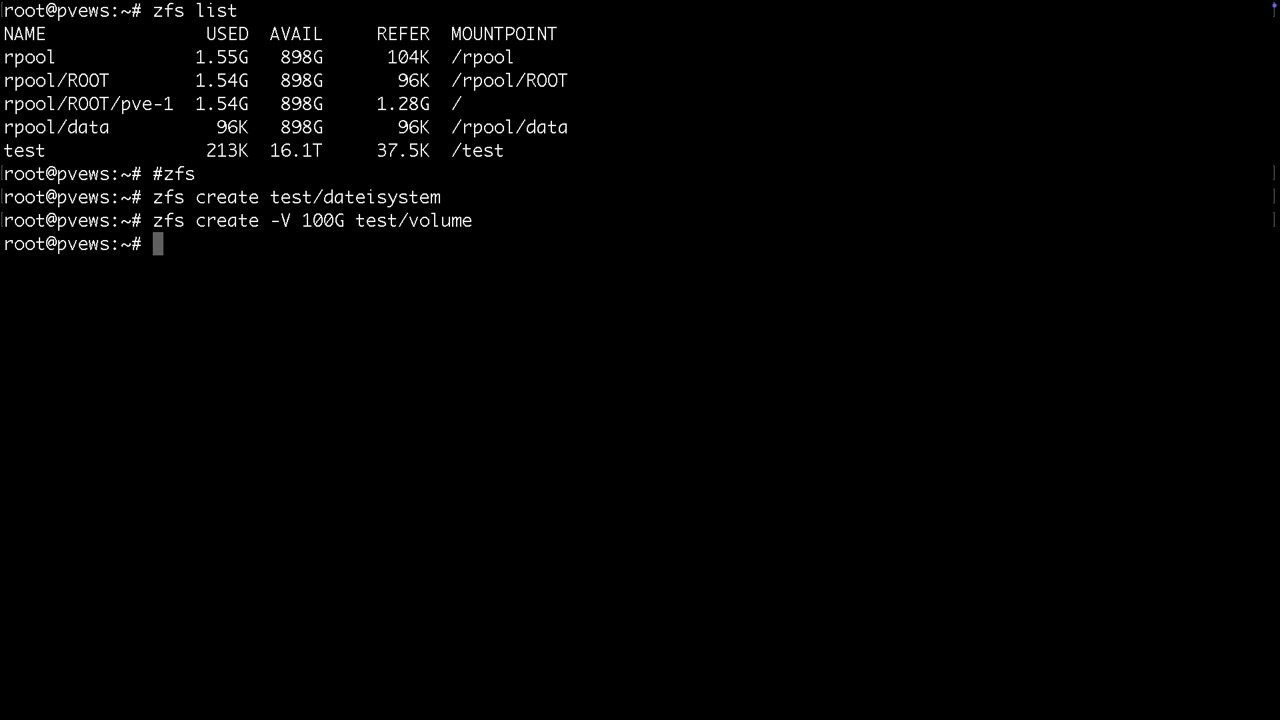
Datasets werden als Ordner gemountet und / oder /mnt (altroot)
Volumes findet man unter /dev/zd... und zusätzlich mit vernünftigen Namen unter /dev/zvol/tankname/....
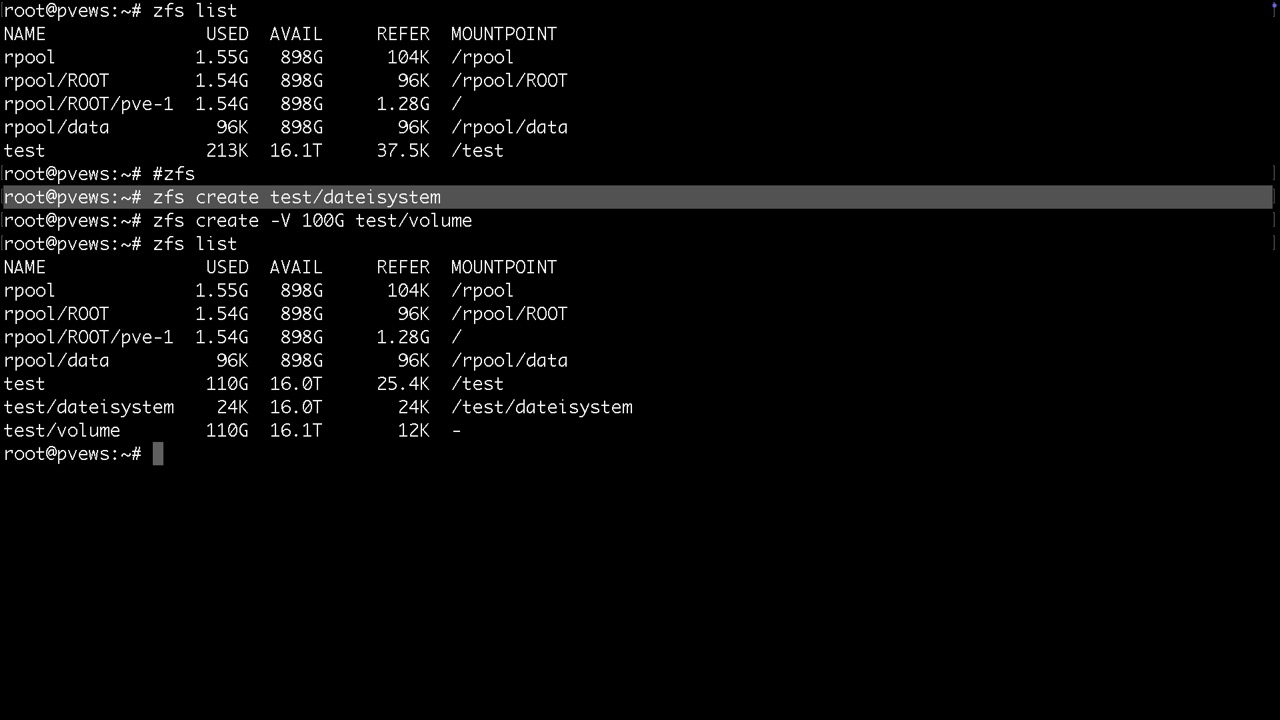
Datasets werden mit Linuxcontainern, Backupfiles, Vorlagen oder Serverdateien bespielt
Volumes verhalten sich wie eingebaute Datenträger, jedoch virtuell. Sie stehen nach dem Import des Pools bereit und können in einer VM genutzt werden. Manipulationen an Volumes zur Vorbereitung oder Datenrettung können jedoch ebenso auf dem PVE Host vorgenommen werden
Diese Schritte übernimmt üblicherweise der Installer in der VM und sollen nur aufzeigen wie diese ZVOLs genutzt werden
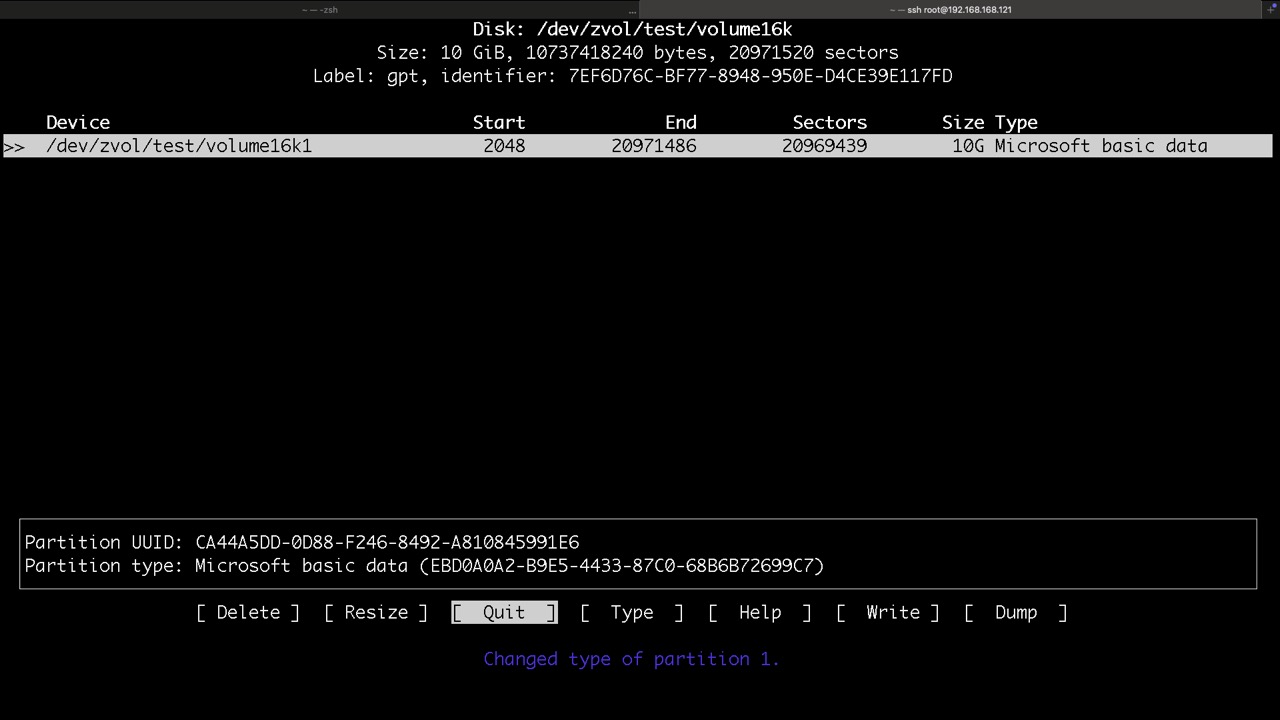
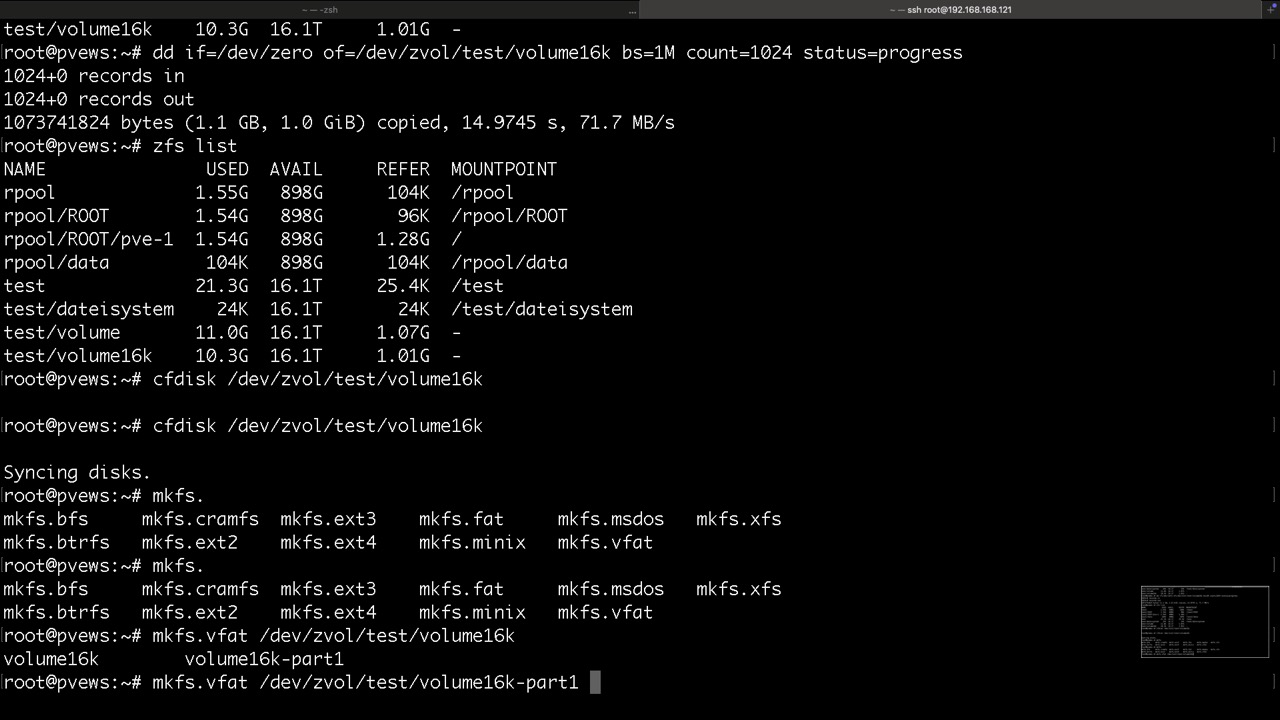

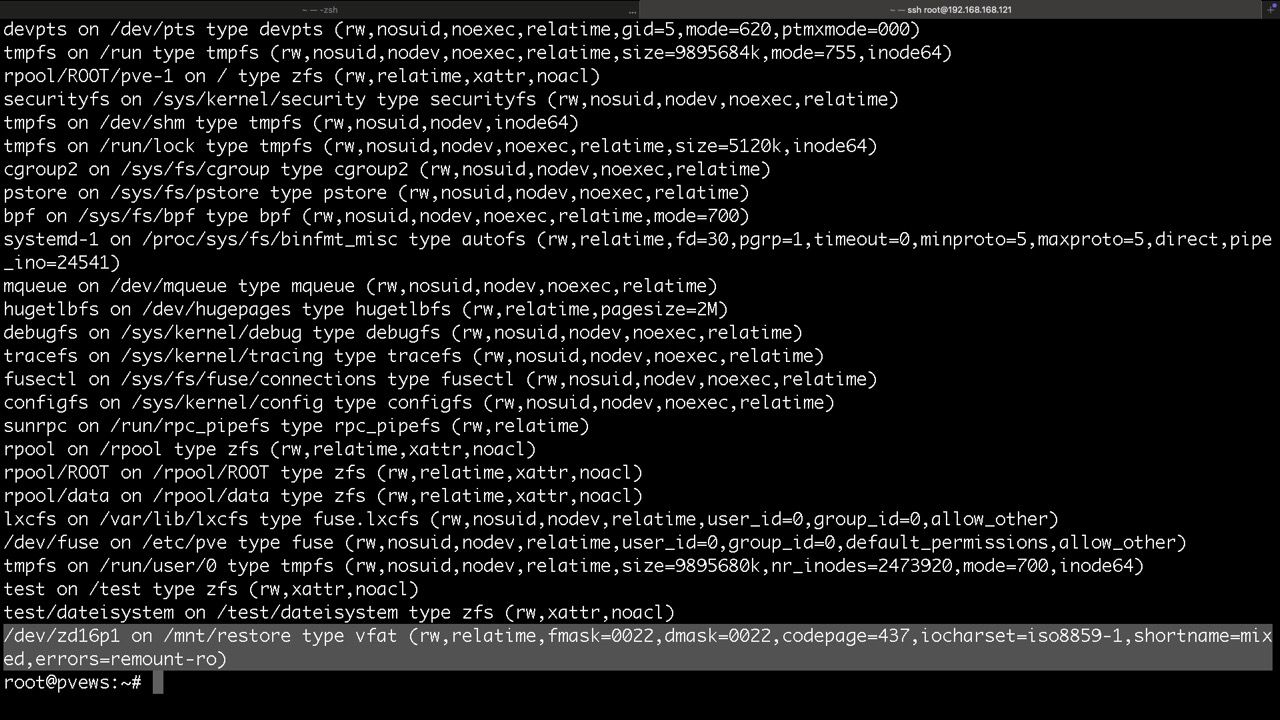
Proxmox legt seine Datasets für in LXC so in ZFS ab
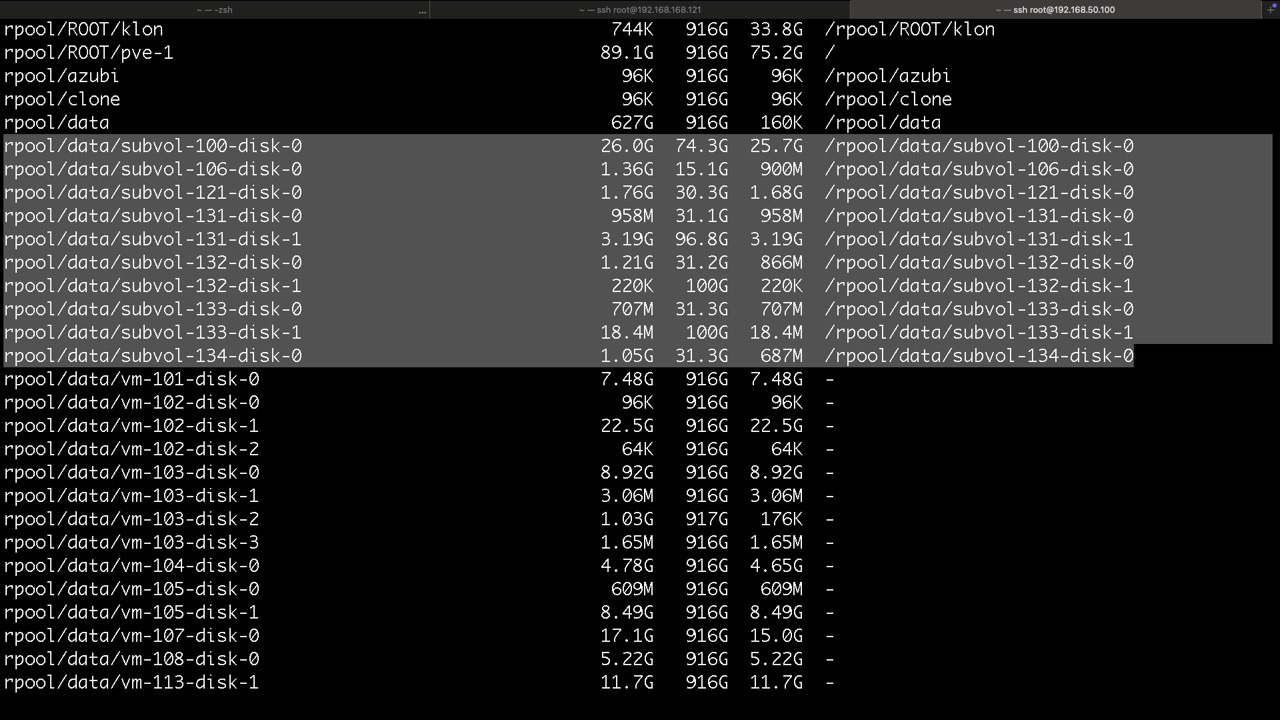
und so die ZVOLs für VMs mit KVM, hier findet man die virtuellen Disk und /dev/zvol...
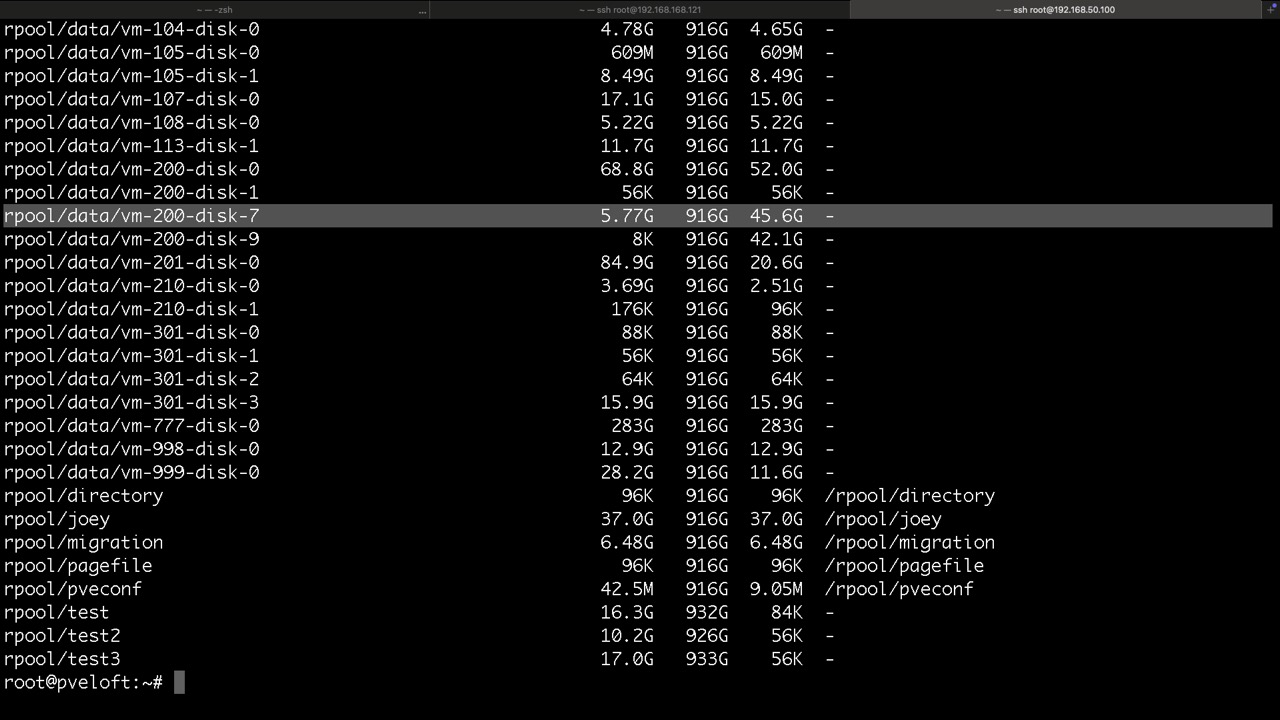
Thin- und Thickprovisioning für Datasets und Volumes
Am Beispiel von Proxmox VE via GUI wird hier eine Thinprovision Festplatte für VM 301 mit 32GB und einer Standardblockgröße von 16k erzeugt. 8k sind nur bei Raid1 und 10 möglich. Hakt man den Thinprovision Haken nicht an, wird beim Erzeugen noch die Option -o refreservation=32G ergänzt. Diese macht bei ZFS mit Autosnapshots aber keinen Sinn
zfs create -s -b 16k -V 33554432k rpool/data/vm-301-disk-4
rpool/data/vm-301-disk-4 56K 1.17T 56K - #hier kein Mount sonder unter /dev/zvol/...
Bei LXC werden Datasets genutzt und der Platz via Reservierung genutzt, wobei bei der genutzten Refquota auch die Snapshotaufhebezeiten den Nettoplatz verkleinern, daher größer dimensionieren, gerne mal doppelt so groß
zfs create -o acltype=posixacl -o xattr=sa -o refquota=33554432k rpool/data/subvol-106-disk-1
rpool/data/subvol-106-disk-1 96K 32.0G 96K /rpool/data/subvol-106-disk-1 #hostzugriff möglich
Virtuelle Diskimages wie QCOW2, VMDK oder RAW-Dateien legt man üblicherweise nicht in Datasets, bestenfalls für NFS oder iSCSI Server